



トレンド
GTC 2026基調講演:Jensen Huangは、なぜ「GPU」ではなく「AIファクトリー」を語ったのか
2026.04.01

GPUエンジニア
大野 泰弘

GTC 2026にて、NVIDIA 創業者/CEO の Jensen Huang(ジェンスン フアン) 氏による基調講演が行われました。現地で聴講した内容をレポートします。
- Jensen Huangは、なぜ「GPU」ではなく「AIファクトリー」を語ったのか
- CUDA 20周年、推論時代の本格到来、そして Vera, Rubin, Groq 統合によるクラスタの再設計
GTC 2026 の基調講演は、単なる新製品発表ではありませんでした。
一言でいえば、NVIDIA が「GPUベンダー」から「AI時代の産業基盤そのもの」を作る会社へ、完全に自己定義を書き換えた講演だったと言ってよいと思います。
もちろん、Jensen Huang らしい軽妙な冗談も、毎年更新される新たな哲学も健在でした。
冒頭から「これはテック(技術)カンファレンスだよ。みんな朝早くから並んでいるけどね」と会場を笑わせつつ、そこから CUDA🄬 20周年、AI Factory、推論需要の爆発、NVIDIA Vera Rubin 世代、そして NVIDIA Omniverse™ ベースの AI ファクトリー設計まで、一気に話をつないでいきます。
この講演を通して強く感じたのは、NVIDIA が今や「高速なチップを売る会社」ではなく、計算資源、ソフトウェア、ネットワーク、ストレージ、運用、そして収益モデルまで含めて「AIファクトリー」を設計する会社になっている、ということでした。
以下、講演の流れを追いながら、要点と背景を噛み砕いて整理していきます。
この講演の本題は「GPUの新作」ではなく「3つのプラットフォーム」だった
Jensen は冒頭で、NVIDIA には大きく3つのプラットフォームがあると整理しました。
それがNVIDIA CUDA-X™、Systems、そして前面に出した AIファクトリーです。
ここがまず重要です。
従来の GTC では、どうしても GPU アーキテクチャや CUDA の話が中心に見えやすかった。ですが、今回の基調講演では、その GPU はあくまで一部品に過ぎない、という見せ方が徹底されていました。
つまり NVIDIA の主張はこうです。
- CUDA-X は、各業界・各用途を高速化するためのライブラリ群
- Systems は、それを現実のスケールで動かすための計算機システム
- AIファクトリーは、その上でトークンを生産し、売上を生む産業設備
ここで「ファクトリー」という言葉を使っているのは、単なる比喩ではありません。
講演全体を通して、Jensen はデータセンターを「ファイルを置く場所」ではなく、トークンを生産する工場として再定義していました。これはかなり大きな視点転換です。
CUDA 20周年の話は、懐古ではなく「なぜNVIDIAが今ここにいるのか」の説明だった
今回の講演は CUDA 20周年でもありました。
Jensen は CUDA の歴史をかなり丁寧に振り返りますが、それは単なる記念演出ではありません。CUDA の土台こそが、今の NVIDIA の強さそのものだという説明になっていました。
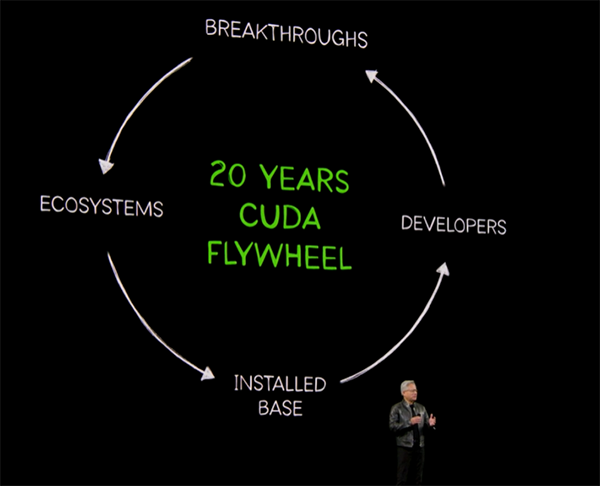
彼が強調していたのは、いちばん難しいのは下の層、つまり土台を作ることだという話です。
何億もの GPU と計算機が CUDA を動かし、その基盤の上に開発者が集まり、ライブラリが増え、アルゴリズムが進歩し、新市場が生まれ、さらに土台が強化される。この循環が 20 年かけて完成した、というわけです。
この話の流れで飛び出したのが、今回最初の大きな冗談でした。
GeForce は NVIDIA 最大のマーケティングキャンペーンだ。
君たちが自分で GPU を買えるようになる前から未来の顧客を集めていた。
親が払っていたんだ。毎年、毎年、毎年。
そしてある日、君たちは立派なコンピューター科学者になって、優良な顧客になった。

私自身、(親に払ってもらって) GeForce で育った身であり、しかも今は計算リソースを設計・構築する側の人間になっていることもあって、ここは腹を抱えて笑いました。
ただの笑い話に見えて、実際に言っていることはかなり鋭い。GeForce の巨大な出荷台数があったからこそ、CUDA を全世界へ運び込めた。しかもその結果として、科学者たちが GPU を深層学習に使えた。つまりゲーム向け GPU の量産基盤が、AI 爆発の前提条件だったという物語に仕立てているわけです。
「親が払ってた」というネタで笑わせながら、実際には GeForce、CUDA、Deep Learning という 20 年スケールの因果を一気につないでいる。ここに Jensen のうまさがあります。
Neural Rendering の話は、単なるグラフィックス新機能ではない
講演前半で Jensen は、次世代グラフィックスとしてNeural Renderingを紹介します。
一見するとここだけ別テーマに見えますが、実は講演全体の核心につながっています。
彼の説明はこうです。
- 3D グラフィックスは 構造化された、完全に制御可能な世界
- 生成 AI は 確率的だが非常にリアルな世界
- その両者を融合することで、美しく、しかも制御可能な生成ができる
このとき彼は「structured data is the foundation of trustworthy AI」と何度も言い換えていました。
ここがこの講演の重要な伏線です。
Neural Rendering の話をしているようで、本当はそのあとに来る企業データ処理、RAG、AI エージェント、AIファクトリーの全部につながる思想を提示しています。
つまり NVIDIA の世界観では、
- 構造化データは「現実の教師データ」
- 生成 AI は「その上に乗る推論・生成エンジン」
- 信頼できる AI を作るには、両者の融合が必要
ということになります。
「このスライドは君たちを少し怖がらせる」――巨大な構造化データ図のくだりが面白い
講演前半でも特に Jensen らしかったのが、巨大なデータ基盤図を出す場面でした。
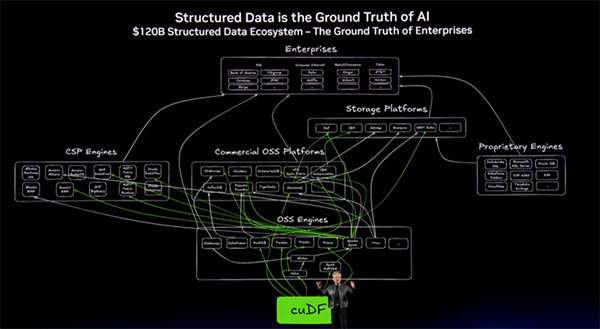
彼はスライドを切り替える前に、
“This is going to scare you a little bit. Don’t gasp.”
「ちょっと怖がるかもしれないけど、悲鳴は上げないでね」
と言い、さらに
“These seats are free for some of you. So this is your price of admission.”
「無料で座ってる人もいるだろうから、これが入場料だ」
と畳み掛けます。
データベース設計をかじったことのある人なら、過去の記憶がよみがえって少し頭が痛くなるかもしれません。私はなりました。
このくだりは完全に会場の空気を読んだジョークなのですが、同時に意味もあります。
彼が見せたかったのは、現代のデータ基盤がすでに SQL、Spark、Pandas、Snowflake、Databricks、BigQuery、EMR、Fabric…という巨大な既存エコシステムでできているという現実です。AI はそこに後付けで乗るのではなく、そこを直接加速しなければならない。そういうメッセージでした。
ここで NVIDIA は 2 つの基盤ライブラリを前面に出します。
- cuDF: 構造化データ / DataFrame 用
- cuVS: ベクトルストアや非構造データ向け
講演では、構造化データは「企業の教師データ」、非構造データは PDF、動画、音声など世界の大半を占める情報であり、これまでは“読まれるだけでほとんど活用されてこなかった”と位置づけていました。AI がその意味を理解して初めて検索可能な資産になる、という整理です。
この説明は、RAG や企業内検索を日常的に触っているエンジニアにはかなり腑に落ちるはずです。
NVIDIA はここで「学習用 GPU を売る会社」ではなく、企業データ基盤そのものを GPU 化する会社として振る舞っていました。
企業導入事例の並べ方から見える、NVIDIA の本当の戦略
IBM Watsonx.data、Dell AI Data Platform、Google Cloud BigQuery、Snapchat などの事例が次々に紹介されました。
Nestlé では 5 倍高速・83%低コスト、Snapchat ではほぼ 80%の計算コスト削減といった数字も出ています。
ここで注目したいのは、数字そのものよりも 見せ方です。
Jensen は
「NVIDIA がライブラリを作り、クラウド/OEM に統合する。顧客がその上で使う。」
というパターンを何度も繰り返して見せていました。Google Cloud、AWS、Microsoft Azure、Oracle などとの関係も、単なる GPU 供給ではなく、NVIDIA がソフトウェアごと顧客を連れてくるという構図で説明しています。
これはかなり重要です。
クラウド事業者から見ると NVIDIA は仕入先である以上に、需要を運んでくるプラットフォームになっている。だからクラウド各社は NVIDIA と深く組まざるを得ない。そんな構図が見えてきます。
「Vertical integration, but horizontally open」という新しい Jensen 哲学
今回の基調講演で最重要の経営メッセージを一つ挙げるなら、これだと思います。
“NVIDIA is vertically integrated, but horizontally open.”
NVIDIAは垂直統合型だが、水平方向にはオープンである。
Jensen は Accelerated Computing について、「これはチップの問題ではない。システムの問題でもない。本当は “application acceleration” なんだ」と言います。つまり、汎用 CPU のように何でも速くする時代は終わり、ドメインごとのアルゴリズムとライブラリを深く理解しないと大きな加速は出せないという認識です。
そして今回の GTC では、ムーアの法則を「半導体の集積密度だけの話」としてではなく、ソフトウェア最適化まで含めて性能向上を実現していく考え方として語っていたのが印象的でした。ここにも、いわば新しい Jensen 哲学が表れていたように思います。
だから NVIDIA は垂直統合せざるを得ない。
- アルゴリズムを理解する
- ライブラリに落とす
- システムへ最適化する
- ネットワークやストレージまで含めて設計する
しかし同時に、それを自社だけで閉じるのではなく、世界中のクラウド、OEM、産業システムに水平展開する。
この「垂直統合 × 水平開放」という整理は、今回の講演全体を貫く思想でした。
なお、現在このレベルの垂直統合を実現できている企業は極めて限られており、少なくとも現時点では NVIDIA の独自性が際立っている、と感じます。
「AIネイティブ企業」の急増は、計算資源がそのまま事業資産になったから
講演中盤では、AI Native 企業群の存在が強調されました。
OpenAI や Anthropic だけでなく、数え切れない新興企業が並び、この 1 年で急拡大したという説明です。Jensen は、これは単なるスタートアップブームではなく、新しい計算プラットフォームの誕生に伴う新産業の誕生だと捉えていました。
ここでのポイントは、今回の AI 企業は過去のスタートアップと違って、最初から莫大な計算資源を必要とすることです。
彼の言い方を借りれば、これらの企業はみな大量のトークンを「生成する」か、「既存トークンに付加価値を乗せる」ことで事業を作っている。だから資本投入額も急拡大する、というわけです。
つまり AI ネイティブ企業とは、ソフトウェア会社であると同時に、トークン生産設備の運用会社でもあるわけです。
この2年で何が変わったのか? Jensen の答えは「3段階進化」だった
Jensen はここで、ここ 2 年の変化を 3 ステップで整理します。
- ChatGPT による Generative AI の起点
- reasoning AI(o1/o3) による思考・分解・検証の導入
- agentic AI(Claude Code, Codex, Cursor など)による実作業の実行
という流れです。
彼の言い回しが面白いのは、以前の AI には “what / where / when / how” を聞いていたのに、今は “create / do / build” と命じるようになった、という説明です。これはかなりわかりやすい。
また NVIDIA 社内でも、すべてのソフトウェアエンジニアが Claude Code、Codex、Cursor のいずれか、あるいは複数を使っていると話していました。これは講演内の発言としてかなり強いメッセージで、エージェントは未来ではなく、もう日常業務の一部だという温度感が伝わってきます。
今回の最大テーマは「推論の転換点」だった
ここから講演は後半の本題に入ります。
Jensen が最も強く押し出していたのは、AI はもう学習だけの時代ではなく、推論が爆発する時代に入ったという点です。
彼のロジックは明快です。
- AI が考えるには推論が必要
- AI が読むにも推論が必要
- AI が行動するにも推論が必要
- AI がトークンを生成する限り、すべて推論である
そして reasoning と agentic AI によって、
- 入力コンテキスト長が増え
- 出力トークン数も増え
- 思考時間も増え
- ツール呼び出しも増えた
結果として、必要計算量はここ 2 年で 1 万倍、利用量は 100 倍、合成すると需要感として 100 万倍に跳ね上がった、と彼は語ります。
ここはかなり誇張的にも聞こえます。
ただ、基調講演の文脈では、単に「GPU が売れてます」という話ではありません。AI が仕事をするようになった瞬間、推論コストは直接売上と結びつく。その転換点を示していたのだと思います。
「5000億ドル? みんな驚かないね。だって全員、過去最高の年だから」
このあたりから Jensen 節がさらに強くなります。
昨年時点で、NVIDIA Blackwell / Rubin 向けに 2026 年までで 5,000 億ドル規模の高確度需要が見えていたと回顧しつつ、
「でもみんな驚いてないね。君たち全員、過去最高の年だったからだ」と笑わせる。そんな場面がありました。
そのうえで、今は 2027 年までに 少なくとも 1 兆ドルが見えている、と踏み込みます。
この数字の真偽を外から厳密に検証するのは難しいでしょう。
ただ、講演の中での意味は明確です。Jensen が言いたいのは、「AI インフラは過熱している」ということではなく、今後の世界経済は AI 推論能力を収益源とする工場建設フェーズに入ったということです。
トークンファクトリーという概念が、今回いちばん重要だった
今回の基調講演を一言で要約するなら、私はここだと思います。
データセンターは、もはや従来のストレージセンターではなく、トークンファクトリーである。
Jensen は、AI ファクトリーを評価するうえで重要な軸を 2 つ挙げます。
- throughput(どれだけ多くのトークンを生産できるか)
- token speed / interactivity(どれだけ速く応答し、長い文脈や複雑な推論を回せるか)
ここで面白いのは、彼がこれを単なる性能指標ではなく、価格表と売上モデルの話に結びつけたことです。
低速・大量の free tier、高速・高品質の premium tier という具合に、トークン生産の品質帯によって価格が変わる。そして AI ファクトリーの価値は、その価格帯ごとにどれだけ供給できるかで決まる、という整理でした。
この考え方は、クラウド屋や推論基盤屋にとってかなり本質的です。
なぜなら、同じ 1GW の電力制約下でも、より高単価帯のトークンを安く生産できれば、そのまま粗利差になるからです。Jensen はここをかなり明確に説明し、「every CEO will study this」とまで言っていました。
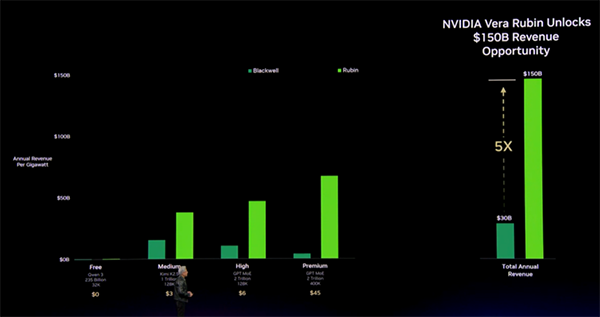
「このチャートでみんなを拷問する」――でも実際いちばん重要なスライドだった
性能と収益の関係を示すチャートについて、Jensen は
“This is where I torture all of you.”
「ここでみんなを拷問するんだけど」
と冗談を言います。
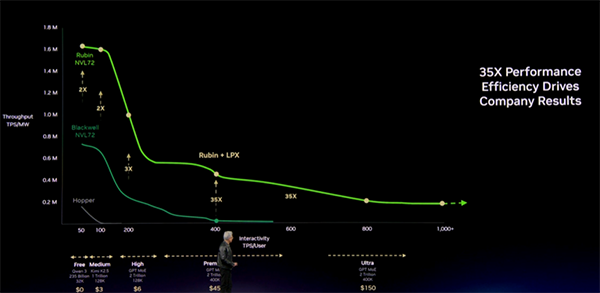
ただ実際、このスライドは今回の基調講演で最重要だったと言ってよいと思います。
彼の言う通り、今後 AI サービス事業者は、
- 同じ電力でどれだけ多くのトークンを吐けるか
- どの価格帯のサービスをどれだけ提供できるか
- その結果、来年の売上がどうなるか
を、まさにこの図で考えるようになるはずです。
要するに、NVIDIA Hopper / Blackwell / Vera Rubin の比較は、TFLOPS 比較ではなく、事業モデル比較として示されている。ここが従来とはまったく違うところでした。
また、トークンを利用するユーザー企業の側から見れば、新たに人を雇うのではなく、どの Tier のモデルを使うエージェントを何体稼働させるのかが、新しい時代の業務設計になっていく。そんな見方もできると思います。
Grace Blackwell と Vera Rubin は「チップ」ではなく「収益装置」として説明された
Jensen は Grace Blackwell について、単なる次世代 GPU ではなく、トークン当たりコストを劇的に下げ、高単価帯のサービス提供能力を引き上げるシステムとして説明しました。
SemiAnalysis の評価に触れつつ、Hopper 比で 35 倍、実際には 50 倍近い perf/watt とまで言及する場面もありました。
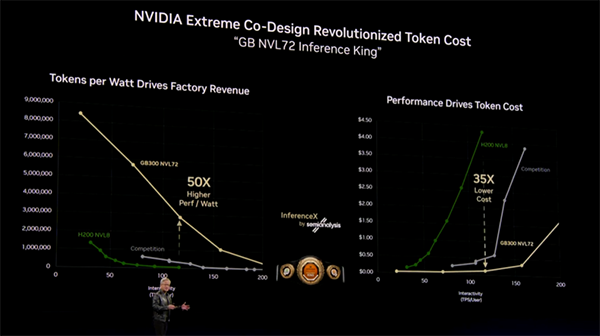
そして Vera Rubin では、それをさらに押し上げます。
ポイントは、Vera Rubin が単体の演算装置ではなく、CPU、ストレージ、ネットワーク、セキュリティまで含めた フルスタックの Agentic AI 用インフラとして語られていることです。
彼が強調していたのは、エージェント時代にはモデル本体だけでなく、
- KV cache
- 構造化/非構造化データアクセス
- ツール呼び出し
- 高速 CPU 実行
- AI ネイティブストレージ
がボトルネックになる、という点です。
だから Rubin 世代では CPU やストレージまで再設計した。そこに大きな意味があります。
Groq 統合の意味は「高スループット」と「高インタラクティブ性」を両立すること
後半の技術的な山場は、NVIDIA Groq LP 系プロセッサを Rubin 系に組み合わせる話でした。
Jensen の説明を簡単に整理するとこうです。
- 高スループットを出すには大規模演算・広帯域相互接続が効く
- しかし超低遅延・超高トークンレートを狙うと、別種のアーキテクチャが必要
- そこで SRAM を大量搭載した推論特化型プロセッサを組み合わせる
- Dynamo により分離型の推論基盤を実装し、prefill / decode を最適分担する
つまり Rubin は大規模推論の主力、Groq は超高速トークン生成の加速器、というすみ分けです。
これは技術的にもかなり面白い話です。
従来の「より大きな汎用 GPU 一発」ではなく、ワークロードの相反する要求を異種プロセッサ統合で解く方向に踏み込んでいるからです。
特に agentic / coding workload のように、高い interactivity が価値に直結する用途では、この構成が効くという説明にはかなり説得力がありました。
Omniverse ベースの DSX は、AIファクトリー を“設計・建設・運用するためのOS”に見せた
講演終盤では、Omniverse をベースにした DSX / AIファクトリー 設計・運用基盤が紹介されました。
ここでは物理・熱・電力・ネットワークのシミュレーション、建設前検証、稼働後の電力最適化まで含めたデジタルツインの話が展開されます。
Jensen は、AI インフラ建設は「史上最大のインフラビルドアウト」だと位置づけ、1 カ月遅れるだけで数十億ドルの売上を失う、とまで言います。そこで、設備ベンダー、設計会社、シミュレーションツール、電力制御、データセンター運用を、Omniverse 上で先に結合する必要がある、という主張になります。
ここまで来ると NVIDIA は、もう半導体会社というより、AI 用発電所・工場の統合設計会社に近い印象です。
宇宙データセンターの話は半分本気、半分 Jensen 節
終盤には「宇宙へ行く」話まで飛び出します。
放射線耐性を持つ Thor 系、衛星、そして将来的な宇宙データセンターの話です。宇宙では伝導も対流もないから放射で冷やすしかない、というかなり工学的なコメントまで入っていました。
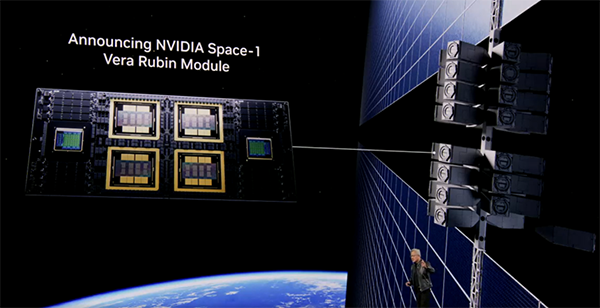
正直、この部分は現時点で即座に実用化というより、Jensen の「AI 基盤は地球規模、いや惑星規模になる」という世界観の演出として見るのが自然だと思います。
ただし NVIDIA が Omniverse やロボティクスで見せてきた流れを考えると、単なる夢物語として切り捨てるのも早いでしょう。
全体を通して何がいちばん重要だったのか
この講演を見て、特に重要だと思ったポイントを 3 つに絞ると、次のようになります。
1. NVIDIA は「GPU性能」ではなく「AIファクトリーの経済性」を語る会社になった
throughput、token speed、tokens per watt、token cost。
今回の基調講演では、性能指標がそのまま収益指標に翻訳されていました。
2. 推論時代では、GPUだけでは足りない
CPU、ストレージ、ネットワーク、KV cache、ツール実行、液冷、運用最適化。
Agentic AI の実用化は、システム全体の再設計を要求する。Vera Rubin はその象徴でした。
3. NVIDIA の本質は“アルゴリズム会社”だという自己認識
CUDA-X、各種ライブラリ、ドメイン最適化、垂直統合。
Jensen は何度も「NVIDIA は algorithm company だ」と言っていました。チップだけではこのポジションは取れない、という自覚がはっきり見えます。
まとめ
- GTC 2026 は、「AIは計算機の上で動くソフトウェア」ではなく「新しい産業設備」だと宣言した講演だった
今回の基調講演で Jensen Huang がやったことは、
Vera Rubin や Groq を発表すること以上に、AI の見方そのものを変えることだったと思います。
- データセンターはトークンファクトリー
- AI モデルは生産設備
- 推論は売上
- 電力は生産制約
- システム設計は工場設計
- Omniverse はそのデジタルツイン
- NVIDIA はその工場を構成するフルスタックの供給者
この構図で見ると、今回の GTC は非常に一貫していました。
CUDA 20周年の振り返りですら、過去を懐かしむためではなく、なぜ NVIDIA がここまで垂直統合できるのかを示す伏線だったわけです。
そして何より印象的だったのは、Jensen がときどき冗談を挟みながらも、終始本気で「これからの CEO は token speed と throughput で会社を見るようになる」
と語っていたことでした。
少し大げさに聞こえるかもしれません。
でも、もし AI が本当に“仕事をする存在”になったのだとすれば、その仕事量を支える推論工場こそが新しい産業基盤になる。
GTC 2026 の基調講演は、まさにその宣言だったのだと思います。
※「NVIDIA」、「CUDA」、「CUDA-X」、「GeForce」、「Omniverse」は、米国およびその他の国におけるNVIDIA Corporationの商標または登録商標です。
※「Databricks」はDatabricks, Inc.の米国およびその他の国における商標または登録商標です。
※「Google Cloud」、「BigQuery」は Google LLC の商標です。
※「AWS」は米国およびその他の国におけるAmazon.com,Inc.またはその関連会社の商標です。
※「Microsoft Azure」はMicrosoft Corporation の商標または登録商標です。
※「Oracle」はOracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
※「IBM watsonx」は、米国やその他の国におけるInternational Business Machines Corporationの商標または登録商標です。
※「ChatGPT」は、米国Open AIの商標または登録商標です。