



性能検証
テトリスで比較!DGX Spark×Ollamaで実現するローカルコーディングエージェント
2026.03.18

GPUエンジニア
小野 雅也

GPUエンジニア
塩田 晃弘
こんにちは、NTTPCコミュニケーションズ1年目社員の小野・塩田です。普段は GPU クラスタの構築やRAG ChatBotの検証業務に取り組んでいます。
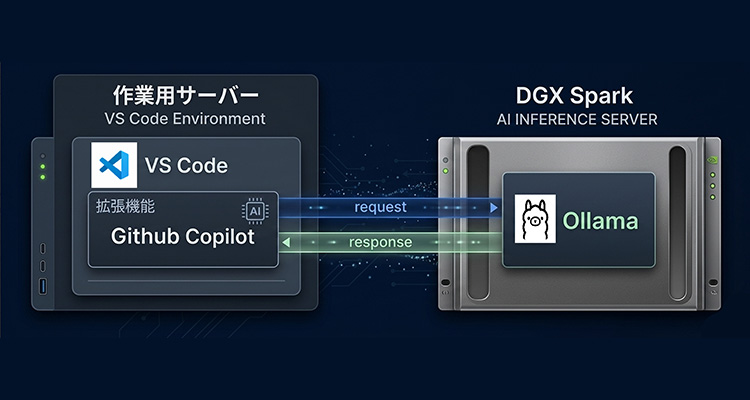
このコラムでは、メモリ容量の潤沢なNVIDIA DGX™ Sparkの活用シーンの一例として、ローカルコーディングエージェントの性能を検証します。
VS Code 上でGithub CopilotとOllamaを連携し、GPT-OSS 120BとQwen3.5 122Bの2モデルにおいて、「テトリス」を模したWebアプリを動作させるためのコード生成を行わせ、完成度を比較しました。
【目次】
手順
1. DGX SparkへのOllamaインストール
まず、DGX Spark上でOllamaを常駐させるためのdocker-compose.yamlを作成します。
⚠ セキュリティに関する重要な注意
Ollamaはデフォルトで認証機構を持たないため、
ポートを公開すると誰でも API にアクセス可能な状態になります。
実運用や社外公開を想定する場合は、必ずアクセス制御(Firewall / VPN / Reverse Proxy / IP 制限 等)を併用してください。
本記事では検証用途を前提としており、認証・認可の設定は扱いません。
Ollamaを起動するための docker-compose.yaml の例は次の通りです。
yaml
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: always
shm_size: '16gb'
ports:
- "11434:11434"
volumes:
- ./volumes/ollama:/root/.ollama
environment:
OLLAMA_FLASH_ATTENTION: 1
OLLAMA_KV_CACHE_TYPE: 'q8_0'
OLLAMA_NUM_PARALLEL: 2
OLLAMA_KEEP_ALIVE: -1
OLLAMA_CONTEXT_LENGTH: 131072
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
次のコマンドでOllamaコンテナを起動します。
docker compose up -d
Ollamaコンテナにログインして、モデルをダウンロードします。
# ollama コンテナにログイン docker exec -it ollama /bin/bash # ollama pullでモデルをダウンロード ollama pull gpt-oss:120b ollama pull qwen3.5:122b
2. VS Codeのインストール
次に、コーディングエディターのVS Codeをインストールします。ここでは一例として、Ubuntuサーバーにインストールする際の手順を説明します。
Webブラウザで https://code.visualstudio.com/download を開きます。

ターミナルからダウンロードしたパッケージを解凍します。
ls cd ダウンロード ls #code_1.107.1-1765982437_arm64.deb がダウンロードされてることを確認 sudo dpkg -i code_1.107.1-1765982437_arm64.deb sudo apt-get install -f
codeコマンドでVS Codeを起動します。
code &
3. VS Code拡張機能のインストール
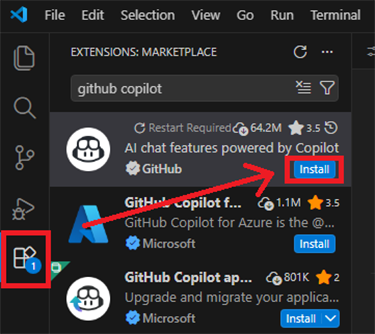
VS Codeの左サイドバーで「Extensions」(拡張機能)を開き、検索ボックスに 「github copilot」と入力。「GitHub Copilot Chat」を選択してインストールする。
4. chatウィンドウを開く
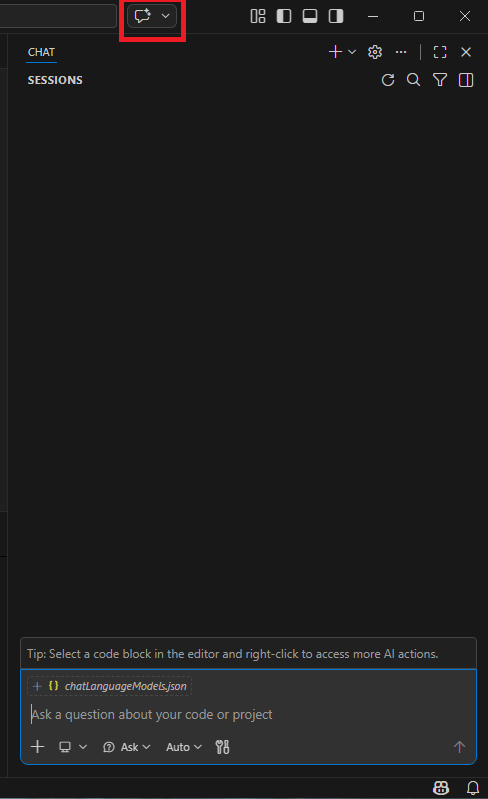
画面右上の吹き出しアイコンをクリックすると、Copilotとの対話ウィンドウが表示されます。
5. モデルの設定画面を開く
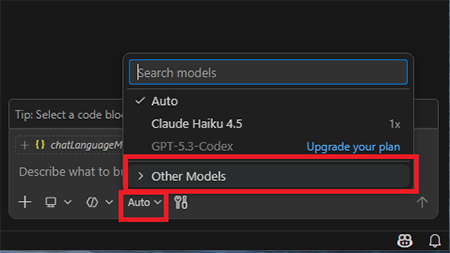
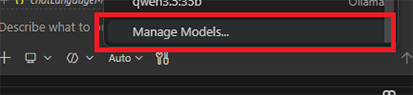
1. Chat ウィンドウ左下の「Auto」ボタンをクリック →「Other Models」を選択。
2. 「Other Models」画面下部の「Manage Models」をクリック。
6. Ollamaエンドポイントの設定
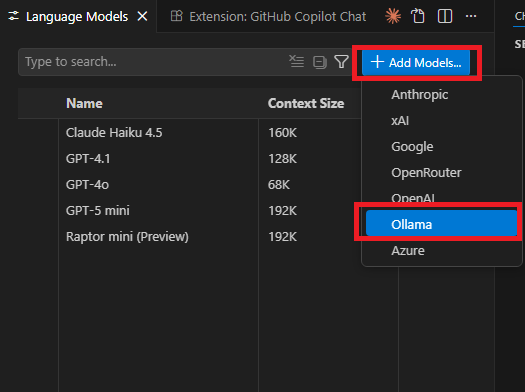
1. 左側メニューから「Add Models」 → 「Ollama」を選択。
2. デフォルト設定のままEnterキーを押す。

3. 次のダイアログで Ollama の IP アドレス(デフォルトはhttp://127.0.0.1:11434)を必要に応じて変更し Enter。

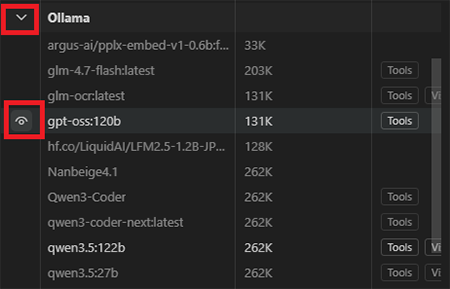
4. Ollamaの左側にあるボタンをクリックしてモデル一覧を展開。デフォルトではすべてのモデルが非アクティブのため、各モデルの左側にあるボタンを押しアクティブに切り替えてください。
7. Ollamaモデルを選択
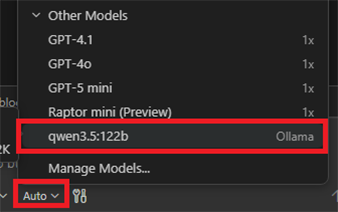
再度、chatウィンドウの下部の「Auto」ボタンを選択し、「Other Models」から gpt-oss:120bやqwen3.5を選択することで、Ollamaを使ったコーディングが可能になります。
8. テトリス Webアプリ作成の検証
指示するのは「テトリスのWebアプリを作成して」という1クエリだけです。「テトリス」がどんなゲームかを調べたり、UIデザイン動作フローはすべてLLMが実行します。
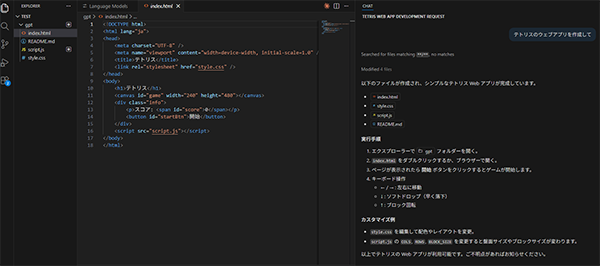
gpt-oss:120bでの実行結果
gpt-oss:120bでの実行結果は次の通りでした。
一発で動作するテトリスが作られました。質素なUIですが、凄い!
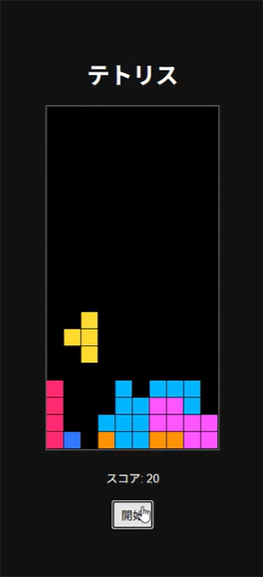
qwen3.5:122bでの実行結果
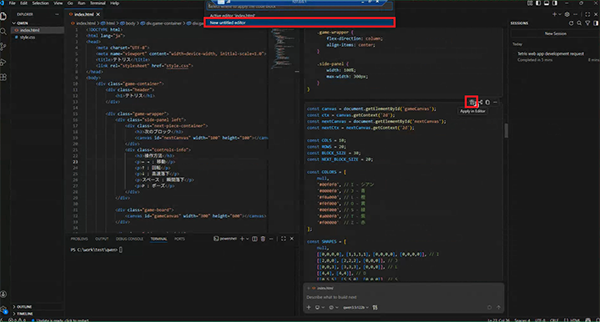
一方、qwen3.5:122bではモダンなUIが作成されました。
ただし、現状ツール使用の連携がGithub Copilotとはうまくいかないようで、一部ファイル操作に人の手助けが必要でした。ファイルの新規作成や書き込みを手作業で実施したり、ファイルの一部変更時にどの箇所の変更なのか人の目でチェックしてコードの上書きを行ったりしました。
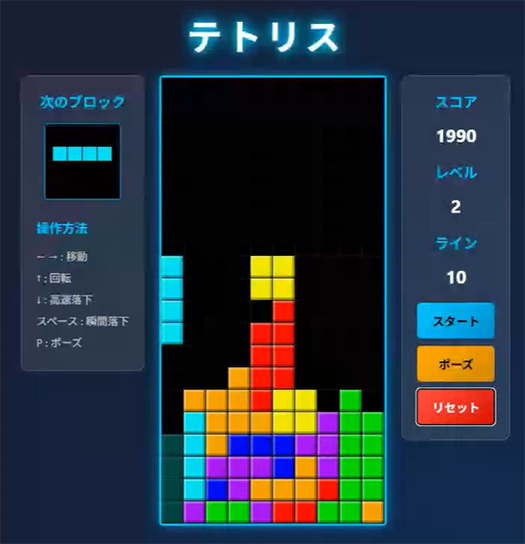
9. まとめ
本検証では、VS CodeとGithub Copilot、そしてローカルLLM を提供するOllamaを組み合わせることで、完全なローカル環境においても高品質なコード生成が実現することを確認しました。
- gpt‑oss:120bは、シンプルかつ即座に実行可能なテトリスアプリを生成でき、開発者の手間を最小限に抑える点で優れています。
- qwen3.5‑122bは、デザイン面での表現力が高く、よりモダンなUIを提供しますが、本検証ではGithub Copilotとのファイル操作連携に若干の手動作業を要しました。
今後、Copilot側の機能拡充やローカルLLMのさらなる高性能化が進むことで、より高い開発効率を実現するワークフローが確立されることも期待されます。
コスト予測のし易さやセキュリティ上の懸念を踏まえると、ローカルLLMを活用した開発環境を構築したいチームや、プライベートなコード生成基盤を整えたい組織にとって良い選択肢であると思います。
最後に、本検証を通じて、DGX Spark上でサービング可能な大規模モデルが、コーディング用途において高い性能を発揮することを確認しました。今後も引き続き、DGX Sparkの検証を進めていく予定です。
DGX SparkをはじめとするGPU製品や、LLM実行環境の導入をご検討の際は、ぜひNTTPCにご相談ください。お客さまの要件に応じたGPUソリューションを提案します。
▶︎ お問い合わせはこちら
※本記事に掲載しているコマンド、設定例、手順等は、2026年3月時点での情報をもとに作成しています。
本記事の内容を実行した際に発生する損害について、弊社は一切の責任を負いません。また、設定手順等が記載通りに再現されない場合があります。
※「NVIDIA」「NVIDIA DGX™ Spark」は、米国およびその他の国におけるNVIDIA Corporationの商標または登録商標です。
※「Visual Studio Code」は、米国およびその他の国におけるMicrosoft Corporationの商標または登録商標です。
※「GitHub」「Github Copilot」は、米国およびその他の国におけるGitHub, Inc.の商標です。
※「Ollama」は、OLLAMA INC.の登録商標です。
※「テトリス」は、米国およびその他の国におけるThe Tetris Company, LLCの商標または登録商標です。