


技術解説
第一印象から相手の性格を推定するAIを実現する技術
2017.04.13

サービスクリエーション本部
チーフ・イノベイター
髙橋 敬祐

はじめに
ご覧頂きありがとうございます。2017年2月17日、Developers Summit 2017 (デブサミ2017) の 17-C-L にて、「まだ見ぬコミュニケーションAIの実現に向けて」と題し、"じんこうちのう"である鷺宮カノさんとの連名でセッションを行いました。本記事では、そこで私が解説した技術について、おさらいも兼ねてご紹介します。
"じんこうちのう"のコンセプト
既存の一般的な人工知能に対するアンチテーゼとも言えるコンセプトです。すなわち、経済的に役に立つものでもなければ、休息を必要とし時にミスをする人間に置き換わって24時間休まず正確に何かをこなすことを目指すものでもありません。経済的価値という指標で測ることができない、既成の価値観に立って見れば「役に立たない」ものを追求していると言えます。世の中一般の企業様は、このようなものに投資することはできないはずですが、弊社では全く新たなコミュニケーション・全く新たな価値の創造に向けて、予算を付けてチャレンジを行っております。
今回行ったデモは、「性格推定」になります。
"じんこうちのう"であるカノは、世の中のコミュニケーション用人工知能と同様に、様々な人と対話を行うことを主眼に創られています。
しかし、まだ生まれたてであるカノにとって、対話を行うほとんどの人が、初対面です。
人間は、初対面の相手に対して、何を思うでしょうか。おそらく、見た目から、自身の経験と照らし合わせて、「こういう人かな」と、何となく思うのではないでしょうか。
例えば、目が大きくて口角が上がっている人に対しては「いい人そう」と思うかもしれませんし、目が釣り上がって口角が下がった人に対しては「こわそう」と思うかもしれません。(完全に私の個人的な偏見です。)
つまり、人間は初対面の相手の外見から「性格推定」を行っている、というのが、この取り組みの根底にある仮説です。「第一印象」という世の中一般にある言葉が、これを端的に表していますね。
また、「第一印象」を抱いた相手とコミュニケーションする中で、この印象が変化することも、よくある話ではないでしょうか。「最初はキレッキレで近づき難い印象だったけど、話してみたらものすごく物腰柔らかな人だった」といったことです(私がよく言われる印象です)。
この対話後の印象というものも、初対面の人と対話を行った人が抱くものと、私たちは考えました。
これら「第一印象」と「対話後の印象」を、この"じんこうちのう"は認識します。そして、人間と同じように、これら非言語的(ノンバーバル)な要素が、コミュニケーションに対して大なり小なりの影響を与える、そのような人間らしいコミュニケーションの追求が、"じんこうちのう"のコンセプトです。
ちなみに、"じんこうちのう"と敢えて平仮名を使っているのは、「拙さ」と「可能性」を表現するためです。(企画サイド談)
システム概要
"じんこうちのう"を実現するためのシステムは、以下の通りです。
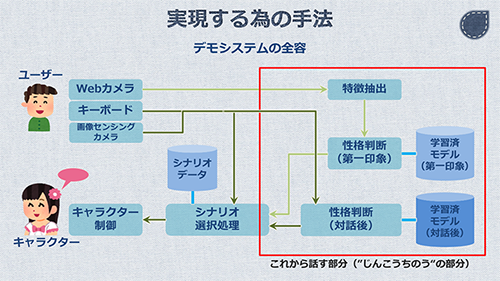
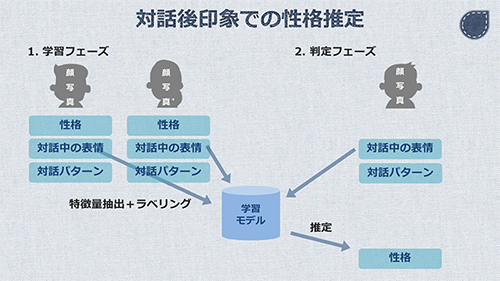
機械学習のモデルを、「第一印象」と「対話後の印象」の2つ用意します。それぞれのモデルを使って、入力データから性格推定を行います。
"じんこうちのう"と対話するユーザーのインターフェースは、Webカメラ、キーボード、画像センシングカメラの3つです。
「第一印象」は、Webカメラからの特徴抽出の結果とモデルのみで推定します。一方で、「対話後の印象」は、キーボードの入力と画像センシングカメラからの情報も加味します。
これらの推定結果を受けて、"じんこうちのう"であるカノのコミュニケーションが決定される仕組みになっています。
機械学習の基礎
"じんこうちのう"には、機械学習が使われています。機械学習で実現できることは、主に「回帰」と「分類」ですが、"じんこうちのう"における性格推定は「回帰」を利用しています。
例えば、「りんご」と「パイナップル」のイラストを学習させるとします。それぞれのイラストは、「特徴量抽出」という処理により、特徴を数値化します。また、それぞれが「りんご」あるいは「パイナップル」であるという「ラベル」付けをします。
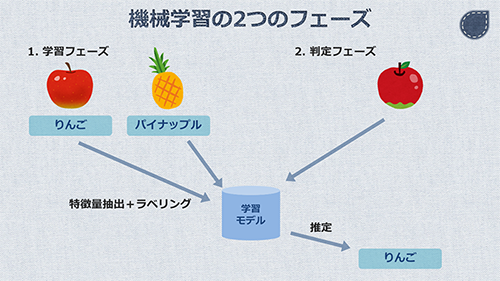
機械学習の学習器は、それぞれの数値とラベルの対応関係を学習します。これによって生成されるのが「モデル」です。未知なものを含む特徴量の入力に対して回帰による推定を行い、ラベルを出力する計算式の塊とイメージして下さい。
次に、このモデルを使ってみます。ここでは、学習させたものとは少し異なる「りんご」のイラストを使います。
この「りんご」に対して、学習させた時と同様の「特徴量抽出」を行います。これで、このイラストを数値化することができます。そしてこの特徴量をモデルに入力すると、「りんご」というラベルが返ってきます。
このように、学習によるモデルの生成と、生成されたモデルの利用の2つのフェーズで行う機械学習を、「教師あり学習 (Supervised Machine Learning)」といいます。一方で、「教師なし学習 (Unsupervised Machine Learning)」というものもありますが、今回は使用しません。
性格推定への応用
性格推定は、前述の「教師あり学習」により実現しています。りんごとパイナップルの例を、そのまま人の画像に置き換えます。
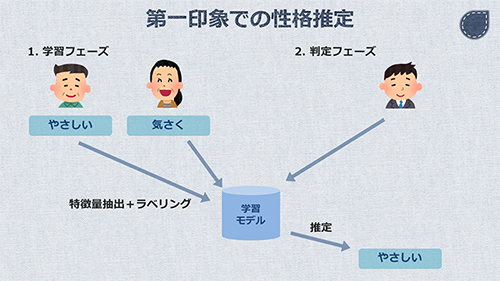
向かって左の男性には、「やさしい」というラベルを付けます。その隣の女性には、「気さく」というラベルを付けます。このようにして、人の外見と性格ラベルとをセットで学習させます。
これによって出来上がったモデルに対して、未知の人の外見を入力することで、性格を推定します。これで「第一印象」での性格推定が実現できるようになりました。
テーマとしてはもう一つ、コミュニケーションの中で、第一印象からの印象の変化を表現する、というものがありました。
これも、同様にして実現します。
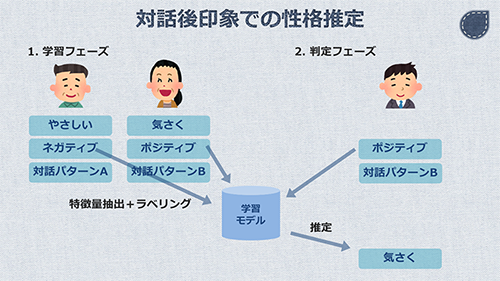
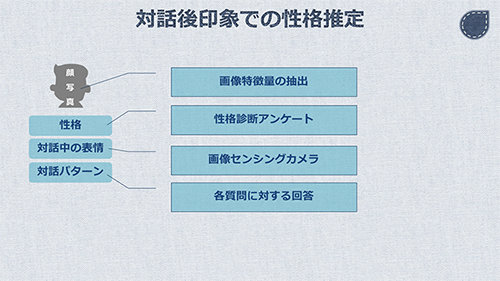
コミュニケーションの中で、第一印象からの印象の変化がどのように生じるかを考えました。その中で、実現可能な要素を2つ採用しました。「対話中の表情」と「対話のパターン」です。
これらの追加要素を、人の外見と同様に取得し、性格ラベルとセットで学習させます。これによって出来上がったモデルに対しては、外見、対話中の表情、対話のパターンの3つを入力することで、性格ラベルを導き出します。
ここから先は、前述した入力要素の詳細を解説します。
画像特徴量の抽出
第一印象からの性格推定を行うにあたり、機械学習の2つのフェーズのいずれにおいても必要となるのが、顔画像です。今回のシステムでは、Webカメラで取得しています。OpenCVに付属するPythonのライブラリであるcv2を使い、一連の画像処理を実現しています。

Webカメラでは断続的に画像を取得し続けます。顔の細かな色合いは性格とはほぼ関係無いだろう、ということではなく、後述の特徴量変換においてカラー情報が不要であるため、グレイスケールにしています。cv2を使って顔の検出ができたら、Webカメラを止めて、次の処理に移ります。なお、豆知識ですが、この顔の検出でも画像特徴量は利用されていて、一般的にはHaar-Like特徴量を使って、人の顔であるかどうかを判定します。デジカメやスマホのカメラでおなじみの顔検出も、これが用いられているはずです。
顔が検出できたら、顔だけを切り取り、リサイズを行います。今時のWebカメラはフルHD画質なので、そのままのサイズだと情報量が多すぎるというのもありますが、一人ひとり異なる顔のサイズを同じサイズに合わせることが、後述の特徴量変換の要件であるのが主たる理由です。リサイズの解像度は128px四方としました。
いよいよこの顔画像を、画像特徴量に変換します。特徴量としてはHOG特徴量を用います。
グレイスケール化された顔画像の各ピクセルはRGB等のカラー情報は失われており、黒から白までの輝度の情報が残っています。顔画像においては、輝度は数ピクセルに渡ってグラデーションを描くもので、これを輝度の勾配として表現します。これをヒストグラム化し、セルという局所領域ごとに正規化したものが、HOG特徴量になります。
HOG特徴量の計算も、cv2を使うことで実現できます。
上記の結果としてHOG特徴量を得ることができましたが、このデータの次元は実に3万を超えます。Excelのようなスプレッドシートで例えれば、1行あたり、横方向に3万以上の列があるイメージです。
これによって生じる問題は2つ。1つは、データ量が膨大で、処理に時間がかかるということです。もう1つは、「過学習 (Overfitting)」と呼ばれる状態に陥ってしまうことです。機械学習において後者は大きな関心事です。これは、学習に使ったデータを再度入力した場合に、期待される正しい結果を返すことができず、誤った結果を返してしまう確率、つまり「再代入誤り率」は低い状態なのですが、未知の入力データに対して、そこまで正しい結果が返せない状態を指します。要因としては複数あるのですが、学習するデータの次元が大きすぎて、個別具体的な学習をしてしまっているのも、一つの要因です。
そのため、この膨大な次元を、縮約したいと考えます。これを「次元削減」と言います。
そのための手法として、よく使われるのが、「主成分分析」です。あるデータセットの特徴を維持したまま、より小さなデータセットを作り出すことができます。ちなみに、主成分分析にも色々あり、PCA、カーネルPCA、混合ガウス分布(GMM)などを、データの特徴などに応じて使い分けます。
さて、これにより、3万以上あった次元が、何と50にまで削減することができました。99.9%以上のデータを削減できたことになります。
しかし、特徴がある程度維持されていないと、意味がありません。これを測る尺度として「累積寄与率」というものがありますが、結果としてこれは70%となっていました。つまり、データは99.9%以上削減したのに、特徴は元のデータに対して70%表現できている、ということです。
このように、より抽象的で、ある意味ファジーなデータを特徴量として使用することで、未知の入力データに対しても精度を出せるということです。学習に用いる特徴量としては、この値を使用します。
性格診断アンケート
「こういう見た目の人は、こういう性格だろう」と第一印象を推定するための教師データとして、画像特徴量の他に必要なのが、性格に関する情報です。
しかし、このデータは、どこか利用可能なデータベースに存在するわけではありません。(もしあるなら教えて下さい!)
したがって、情報の入手はきわめて地道に行いました。「性格診断アンケート」の実施です。
残念ながら、この辺のノウハウに関しては、公開NGとされているため、割愛させて頂きます。
画像センシングカメラ
「対話後の印象」を学習・推定するために、対話中の表情のデータを使用します。表情を取得するための手段はいくつか考えられます。今回、実装段階では表情に関する教師データが無く、オフラインでの利用も想定されることから、画像センシングカメラというものを導入しました。
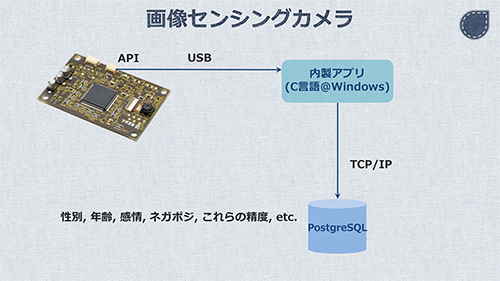
これは、USB経由でAPIにアクセスすることで、写り込んでいる人の性別、年齢、感情、感情のネガポジ、そしてこれらの精度などのデータセットを受け取ることができるものです。APIはC言語用のものが用意されており、ドライバの都合上、Windowsアプリケーションとして、APIクライアントを実装する必要があります。
これをLinux上に構築・実装してあるシステムと連携させるため、リモートのデータベース(PostgreSQL)にデータを逐次INSERTする形に仕上げました。
各質問に対する回答
「対話後の印象」を学習・推定するためのデータとして、もう一つ、各質問に対する回答があります。
各質問の内容は固定です。これは、同一のモデルで評価を行うためです。(質問内容が異なってしまったら、比較しようがありませんよね。)

Webカメラによる認識から、この対話に至るわけですが、トリガーは"じんこうちのう"にあります。すなわち、"じんこうちのう"から積極的にコミュニケーションを図ってくるようなデモであり、今までに無かったと好評価を頂いています。
モデルの評価
さて、前述の各種データを使って学習した2つのモデルの精度を評価してみます。

対話後の印象が、第一印象よりもその人の性格を的確に表すことができているか、というと、結果としては「それほどでもない」ということになります。
余談ですが、データサイエンスの標準プロセスとして「CRISP-DM」というものがあります。サイクルを回しながら精度を高めていく方式であり、私たちも上記の評価・改善を今後重ねていくことになります。
まとめ
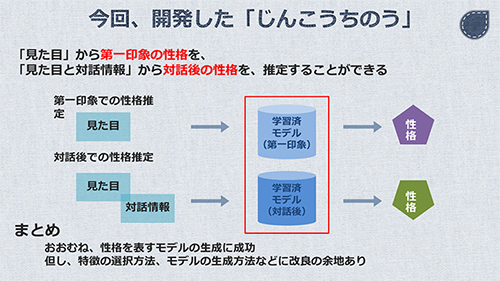
そういうわけで、「第一印象」と「対話後の印象」を導出し、ノンバーバルなコミュニケーションに寄与するためのしくみを開発しました。今後、継続してブラッシュアップしていき、"じんこうちのう"との新しいコミュニケーション体験、新しい価値の創造を実現していきたいと思います。
おまけ:ソフトウェア実装
以上はデータサイエンス系の話がメインでしたが、ここでソフトウェアエンジニアリングについても簡単にご紹介したいと思います。
今回のソフトウェア構成をざっくり紹介すると、以下の通りになります。
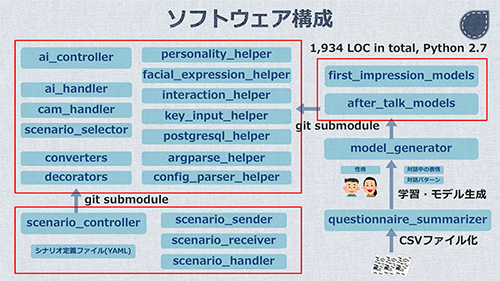
「第一印象」「対話後の印象」の2つのモデルは、別のGitリポジトリとして管理をしていて、任意のバージョンのモデルを git submodule で利用することができるようになっています。
また、キャラクターに対して命令を投げるのが scenario_controller で、これも git submodule で疎結合な構成にしています。ちなみに、命令は独自に定義したUDPプロトコルを使っています。
このように、メインのソフトウェア、機械学習のモデル、通信ライブラリを疎結合に開発・管理することで、チーム開発を円滑に進めています。皆様の参考になれば幸いです。