


技業LOG
はじめに
今やITリソースには、モニタリングは欠かせない
弊社ではInfoSphere®やMaster'sONE®などのネットワークサービスを提供しており、お客さまへより安定したサービスを提供するためにモニタリングシステムを用いたネットワークインフラの監視を行っています。
当然ながらインフラの運用上、モニタリングシステムは非常に重要なコンポーネントです。稼働中のシステムの障害やその予兆を検知したり、お客さまのサービス品質が低下していないか確認、その他トラブルシューティングに利用、また将来的な設備投資の判断に必要となる根拠情報(トラフィック情報)を把握したり...様々な用途のため運用上欠かせないものとなっています。
今回、このモニタリングシステムについて現状の運用を改善し、より高度な運用を目指すべく検討・PoCを行ったため、その内容について共有致します。
現モニタリングシステムを用いた運用上の課題と実現したいこと
- 監視登録やWEBページ作成について手動ベース運用のため自動化したい
- 過去のトラフィック情報を細かい粒度で参照したい
- アラート発生時のEメール通知によりメールボックス逼迫の抑制、かついい感じにアラート黙認化したい
- SNMPで取れないMetricsを取得するためのツールを個別に作成しているため、取得方法を共通化・シンプル化したい
- トラフィック情報を加工/計算したAI的なことやってみたい
- 監視システムや監視定義を全てコード化し、冪等性の担保されたシステムとしたい
- 外部システム(社内システムや顧客システム)とAPI連携しデータ公開可能としたい
システム構成案
上記課題の解決に向け、モニタリングシステムについて下記構成を検討しました。
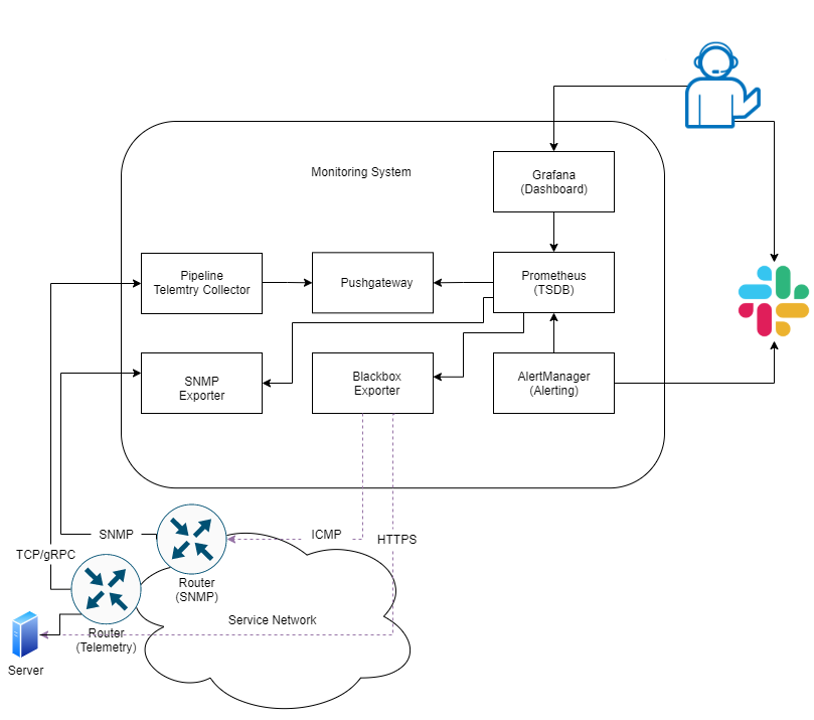
検討したモニタリングシステム構成
これらは全てOSS(オープンソースソフトウェア)を用いており、「Prometheus」を中心としてGrafana(Dashboard)やPipeline(Telemetry Collector)が含まれています。
Prometheusはサーバーやクラウド、ネットワークなど様々なシステムやアプリケーションに対応した次世代監視システムです。Prometheus自身の主機能はTSDB(時系列データベース)ですが、「Exporter」と呼ばれるプラグイン的なソフトウェアを利用し監視対象のデバイスからMetricsを取得します。Exporterは様々なものが存在し、要求や用途に応じたものを選択して利用することが可能です。
参考:https://prometheus.io/docs/instrumenting/exporters/
またPrometheus及びExporterは全てWEB API経由で連携するため、拡張性が高く、スケーラブルな作りとなっています。
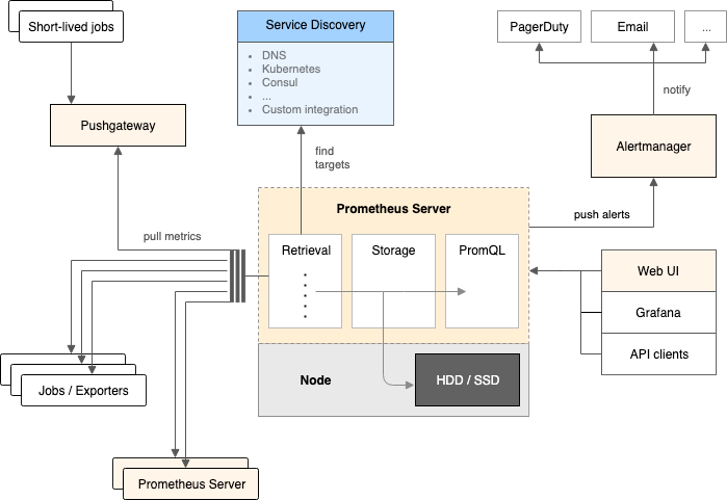
Prometheus Architecture Overview
https://github.com/prometheus/prometheusより
Telemetryとは?
上記構成図の中に「Telemetry」というキーワードが出てきました。今回はネットワーク監視におけるテレメトリーの意味で、レガシーなモニタリング技術であるSNMPに取って変わるかもしれない次世代モニタリング技術として注目されています。
| 項目 | SNMP(Get/Walk) | Telemetry |
|---|---|---|
| 特徴 | ポーリング型、SNMP Serverからのリクエストに基づきSNMP AgentがMetricsを返す | プッシュ型、デバイスは継続的にTelemetry CollectorへMetricsを送信し続ける |
| トランスポート | UDP | UDP/TCP/gRPC |
| エンコーディング | BER(Basic Encoding Rules) | GPB(Google Protocol Buffers)、JSON |
| データモデル | ASN.1(標準MIB、プライベートMIB) | OpenConfig、Vendor Native |
表.SNMPとTelemetryの比較
古くから運用されているSNMPはシンプルなアーキテクチャで気軽に利用することが出来ますが、一方で取得するmetricsが多くなると応答時間が長くなりパフォーマンスが低下する問題があり、取得可能なmetricsも限られます。
そこで昨今、大規模環境で効率的な運用を行うことを目的としてOTTを始めとした様々な事業者にてTelemetryの導入検討あるいは既に導入が進んでいる状況です。今回のPoCではまずはTelemetryを触って理解を深めることを目的とし、SNMPと並行してTelemetryを使用してみることとします。
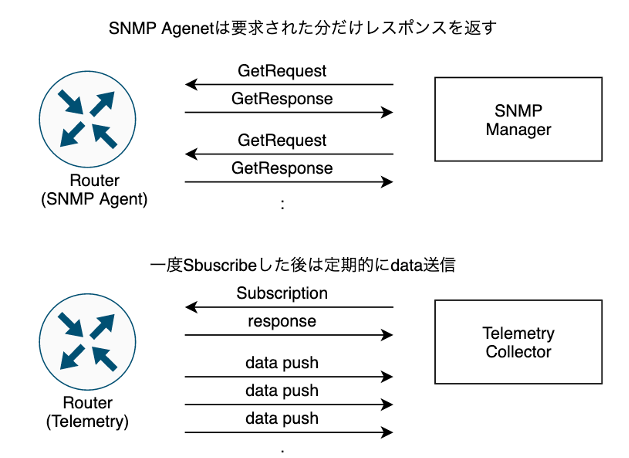
図.SNMPとTelemetryの動作概要
PoC環境の構築
今回行ったPoC環境の構築手順を紹介します。
今回はこのモニタリングシステムのPoC(Proof of Concept)では弊社が代理店として機器販売を行っているCisco社製ルーターASR9000とIXIA社製の100GE対応トラフィックジェネレーターXGS2を利用して環境構築しました。
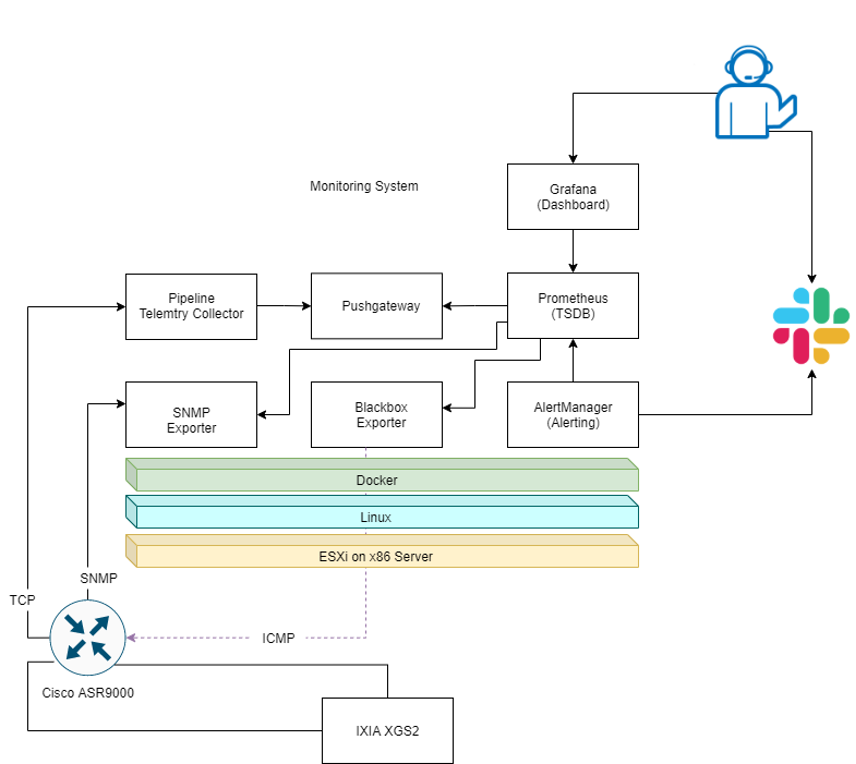
PoC環境
| ハードウェア | ソフトウェア | 用途 |
|---|---|---|
| X86 Server | VMWare ESXi7.0 / CentOS7 | モニタリングシステム |
| Cisco ASR9000 | IOS-XR 7.1.3 64-bit | 監視対象デバイス |
| IXIA XGS2 | IxNetwork 9.00 | トラフィックジェネレーター |
これから下記1.〜7.にてMonitoring Systemとルーター(ASR9000)の設定を行い、その後Grafanaにてdashboard作成、最後にIXIAでトラフィックをかけて検証を行う流れとなります。
① Pipelineコンテナイメージのビルド
Cisco社のTelemetryに対応したCollectorがOSSとして公開されており、ASR9000からのTelemetry data受信のために当ソフトウェアを利用します。
https://github.com/cisco/bigmuddy-network-telemetry-pipeline
今回、モニタリングシステム上のコンポーネントは全てDocker Containerとして動作させるため、pipeline付属のDockerfileを元に、事前にイメージビルドします。
# git clone https://github.com/cisco/bigmuddy-network-telemetry-pipeline.git
# cd bigmuddy-network-telemetry-pipeline/docker/
# docker build -t <Docker-HUB-ID>/pipeline:<バージョン情報> .
# docker image ls
② Dockerコンフィグ
Docker Container作成のためにdocker-composeを利用します。
Docker環境やdocker-composeのインストール手順は省略します。
なお、比較的新しいバージョンではpipelineとの接続性が取れなかったためpushgatewayのみバージョン指定でv0.3.1を用いています。
またファイルやディレクトリの配置はこちらの通りです。
./nw-monitoring
├── README.md
├── docker-compose.yml
├── grafana/
│ ├── grafana.env # grafanaのコンフィグ
├── prometheus/
│ ├── prometheus.yml # prometehusのコンフィグ
│ ├── alert.rules # alert ruleファイル
│ └── data/ # 永続化ストレージ用フォルダ
├── alertmanager/
│ └── config.yml # alertmanagerのコンフィグ
├── snmp-exporter/
│ ├── snmp.yml # snmp-exporterのコンフィグ
│ └── target_iosxr.yml # サービスディスカバリー用ファイル
└── pipeline/
├── metrics.json # Metricsのコンフィグ
└── pipeline.conf # pipelineのコンフィグ
モニタリングシステム内のディレクトリ構造
docker-compose.yml
version: '2'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus/alert.rules:/etc/prometheus/alert.rules
- ./snmp-exporter/target_iosxr.yml:/etc/prometheus/target_iosxr.yml
ports:
- 9090:9090
command:
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/etc/Prometheus/data
- --storage.tsdb.retention.time=365d
restart: always
pushgateway:
image: prom/pushgateway:v0.3.1
container_name: pushgateway
ports:
- 9091:9091
restart: always
alertmanager:
image: prom/alertmanager
container_name: alertmanager
volumes:
- ./alertmanager:/etc/alertmanager
command: "--config.file=/etc/alertmanager/config.yaml"
ports:
- 9093:9093
restart: always
grafana:
image: grafana/grafana
container_name: grafana
env_file:
- ./grafana/grafana.env
ports:
- 3000:3000
restart: always
snmp-exporter:
image: prom/snmp-exporter
container_name: snmp-exporter
volumes:
- ./snmp-exporter/snmp.yml:/etc/snmp_exporter/snmp.yml
ports:
- 9116:9116
pipeline:
image: <Docker-HUB-ID>/pipeline:<バージョン情報>
container_name: pipeline
volumes:
- ./pipeline/pipeline.conf:/data/pipeline.conf
- ./pipeline/metrics.json:/data/metrics.json
ports:
- 8989:8989
- 5432:5432
restart: always
node-exporter:
image: quay.io/prometheus/node-exporter
container_name: node-exporter
ports:
- 9100:9100
volumes:
- /proc:/host/proc
- /sys:/host/sys
- /:/rootfs
restart: always
③ prometheusのコンフィグ
prometehus.yml
global:
scrape_interval: 30s
scrape_timeout: 10s
evaluation_interval: 10s
external_labels:
monitor: 'bb-monitor'
rule_files:
- /etc/prometheus/alert.rules
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- <サーバーの自IP>:9093
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['<サーバーの自IP>:9090'
- job_name: 'pushgateway'
static_configs:
- targets: ['<サーバーの自IP>:9091']
- job_name: 'snmp-exporter_iosxr'
file_sd_configs:
- files:
- '/etc/prometheus/target_iosxr.yml'
metrics_path: /snmp
params:
module: [iosxr]
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: <サーバーの自IP>:9116 # The SNMP exporter's real hostname:port.
- job_name: 'node-exporter'
static_configs:
- targets: ['<サーバーの自IP>9100']
- job_name: pipeline
static_configs:
- targets: ['<サーバーの自IP>:8989']
Intervalやtimeoutの設定は非常に重要な設計事項のため、今後より詳細な検討動作確認を実施しブラッシュアップする予定です。
より詳細な内容はこちらをご覧ください。
https://prometheus.io/docs/prometheus/latest/configuration/configuration/
alert.rules
groups:
- name: instance watch
rules:
- alert: instance_down
expr: up == 0
for: 5m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
- name: telemetry_test
rules:
- alert: RSP-CPU_1min
expr: total_cpu_one_minute{exported_instance="pipelinemetrics_10077693279896574474"} > 20
for: 1m
labels:
severity: critical
annotations:
description: "{{ $labels.instance }}s CPU load ishigh (current vlaue: {{ $value }})"
summary: "{{ $labels.instance }}s CPU Load is high"
- alert: Inbound_Traffic_High
expr: irate(bytes_received{exported_instance="pipelinemetrics_17490127550022736183"}[1m])*8 > 100000000
for: 1m
labels:
severity: critical
annotations:
description: "{{ $labels }}s traffic high (current vlaue: {{ $value }})"
summary: "{{ $labels }}s traffic high"
pushgatewayがpipelineから受信したmetricsのexported_instanceはprometheusにて確認した結果を入力してください。
より詳細な内容はこちらをご覧ください。
https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
④ alertmanagerのコンフィグ
global:
slack_api_url: 'https://hooks.slack.com/services/XXX/YYY' ### SlackのAPI URL
http_config:
proxy_url: 'http://<Proxy-Server-IP>:<Port>' ### Proxy利用時のみ
route:
receiver: 'slack'
receivers:
- name: 'slack'
slack_configs:
- channel: '<チャンネル名>'
- send_resolved: true
- text: 'alerting!!!'
より詳細な内容はこちらをご覧ください。
https://prometheus.io/docs/alerting/latest/configuration/
⑤ snmp-exporterのコンフィグ
snmp.yml
iosxr:
walk:
- 1.3.6.1.2.1.31.1.1.1.6
- 1.3.6.1.2.1.31.1.1.1.10
- 1.3.6.1.2.1.31.1.1.1.8
- 1.3.6.1.2.1.31.1.1.1.12
- 1.3.6.1.2.1.31.1.1.1.9
- 1.3.6.1.2.1.31.1.1.1.13
- 1.3.6.1.2.1.31.1.1.1.1
- 1.3.6.1.4.1.9.9.109.1.1.1.1.6
- 1.3.6.1.4.1.9.9.109.1.1.1.1.7
- 1.3.6.1.4.1.9.9.109.1.1.1.1.8
- 1.3.6.1.4.1.9.9.221.1.1.1.1.18
- 1.3.6.1.4.1.9.9.221.1.1.1.1.20
metrics:
- name: ifHCInOctets
oid: 1.3.6.1.2.1.31.1.1.1.6
type: counter
help: The total number of octets transmitted out of the interface, including framing
characters - 1.3.6.1.2.1.31.1.1.1.6
indexes:
- labelname: ifName
type: gauge
lookups:
- labels:
- ifName
labelname: ifName
oid: 1.3.6.1.2.1.31.1.1.1.1
type: DisplayString
- name: ifHCOutOctets
oid: 1.3.6.1.2.1.31.1.1.1.10
type: counter
help: The total number of octets transmitted out of the interface, including framing
characters - 1.3.6.1.2.1.31.1.1.1.10
indexes:
- labelname: ifName
type: gauge
lookups:
- labels:
- ifName
labelname: ifName
oid: 1.3.6.1.2.1.31.1.1.1.1
type: DisplayString
- name: cpmCPUTotal5secRev
oid: 1.3.6.1.4.1.9.9.109.1.1.1.1.6
type: gauge
help: The overall CPU busy percentage in the last 5 second period - 1.3.6.1.4.1.9.9.109.1.1.1.1.6
indexes:
- labelname: cpmCPUTotalIndex
type: gauge
- name: cpmCPUTotal1minRev
oid: 1.3.6.1.4.1.9.9.109.1.1.1.1.7
type: gauge
help: The overall CPU busy percentage in the last 1 minute period - 1.3.6.1.4.1.9.9.109.1.1.1.1.7
indexes:
- labelname: cpmCPUTotalIndex
type: gauge
- name: cpmCPUTotal5minRev
oid: 1.3.6.1.4.1.9.9.109.1.1.1.1.8
type: gauge
help: The overall CPU busy percentage in the last 5 minute period - 1.3.6.1.4.1.9.9.109.1.1.1.1.8
indexes:
- labelname: cpmCPUTotalIndex
type: gauge
- name: cempMemPoolHCUsed
oid: 1.3.6.1.4.1.9.9.221.1.1.1.1.18
type: counter
help: Indicates the number of bytes from the memory pool that are currently in
use by applications on the physical entity - 1.3.6.1.4.1.9.9.221.1.1.1.1.18
indexes:
- labelname: entPhysicalIndex
type: gauge
- labelname: cempMemPoolIndex
type: gauge
- name: cempMemPoolHCFree
oid: 1.3.6.1.4.1.9.9.221.1.1.1.1.20
type: counter
help: Indicates the number of bytes from the memory pool that are currently unused
on the physical entity - 1.3.6.1.4.1.9.9.221.1.1.1.1.20
indexes:
- labelname: entPhysicalIndex
type: gauge
- labelname: cempMemPoolIndex
type: gauge
version: 2
auth:
community: <SNMP Communicaty名>
<SNMP Community名>の箇所は適宜書き換えてください
snmp-exporterのコンフィグ(今回はsnmp.yml)はGeneratorを利用して簡単に生成することが出来ます。本ブログでは紹介しませんが、詳しくはこちらのGithubをご覧ください。
https://github.com/prometheus/snmp_exporter/tree/master/generator
target_iosxr.yml
- targets:
- <監視対象1のIP/ホスト名>
- <監視対象2のIP/ホスト名>
⑥ pipelineのコンフィグ
metrics.json
<公式のものをそのまま利用するため省略します>
参考:https://github.com/cisco/bigmuddy-network-telemetry-pipeline/blob/master/docker/metrics.json
pipeline.conf
[default]
id = pipeline
metamonitoring_prometheus_resource = /metrics
metamonitoring_prometheus_server = :8989
[mymetrics]
stage = xport_input
type = tcp
encap = st
listen = :5432
[metrics_prometheus]
stage = xport_output
type = metrics
file = /data/metrics.json
datachanneldepth = 1000
output = prometheus
pushgw = <Serverの自IP>:9091
jobname = telemetry
今回gRPCでの動作確認が取れず、transportはTCPを選択しました
⑦ Docker Containerの起動
docker-compose.ymlが存在するディレクトリにて入りContainerを起動し、各Containerの状態を確認します。
# sudo docker-compose up -d
# sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4d05cb9cb75d XX/pipeline:<Version> "/pipeline -log=/dat..." 2 hours ago Up 2 hours 0.0.0.0:5432->5432/tcp, 0.0.0.0:8989->8989/tcp pipeline
442bafeffde3 quay.io/prometheus/node-exporter "/bin/node_exporter" 2 hours ago Up 2 hours 0.0.0.0:9100->9100/tcp node-exporter
bb9dcacb34df grafana/grafana "/run.sh" 2 hours ago Up 2 hours 0.0.0.0:3000->3000/tcp grafana
bb16ea0cc21b prom/alertmanager "/bin/alertmanager -..." 2 hours ago Up 2 hours 0.0.0.0:9093->9093/tcp alertmanager
9ef55267166b prom/snmp-exporter "/bin/snmp_exporter ..." 2 hours ago Up 2 hours 0.0.0.0:9116->9116/tcp snmp-exporter
d813d157c0e8 prom/pushgateway:v0.3.1 "/bin/pushgateway" 2 hours ago Up 2 hours 0.0.0.0:9091->9091/tcp pushgateway
37df50870cbb prom/prometheus "/bin/prometheus --w..." 2 hours ago Up 2 hours 0.0.0.0:9090->9090/tcp prometheus
⑧ 監視対象(IOS-XRのコンフィグ)
下記コンフィグを投入します。
SNMP用として一般的なコンフィグを投入します。
snmp-server vrf MgmtEth #非VRF環境の場合vrf指定は不要
!
snmp-server community <SNMP Community名> RO IPv4
snmp-server ifindex persist
<SNMP Community名>の箇所は適宜書き換えてください
Telemetry用のコンフィグを投入します。エンコーディングやプロトコルを指定し、モニタリング対象としたいsensor-pathを明示的に設定する点がSNMPと異なります。
telemetry model-driven
destination-group DGroup1
vrf MgmtEth #非VRF環境の場合vrf指定は不要
address-family ipv4 <ServerのIP> port 5432
encoding self-describing-gpb
protocol tcp
!
!
sensor-group SGroup1
sensor-path Cisco-IOS-XR-wdsysmon-fd-oper:system-monitoring/cpu-utilization
sensor-path Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counters
!
subscription Sub1
sensor-group-id SGroup1 sample-interval 10000
destination-id DGroup1
source-interface MgmtEth0/RSP0/CPU0/0
!
- ※Interfaceなどネットワーク部分のコンフィグは省略します
設定投入後、既に起動済のpipeline containerとの間でセッションが確立されたら、SubscriptionがActiveとなっていることを確認します。今回はtransportとしてTCPを利用しているため、Destinationにてtcp: 1となっています。
RP/0/RSP0/CPU0:A9k-TEST#show telemetry model-driven summary
Sun Feb 7 13:49:31.764 JST
Subscriptions Total: 1 Active: 1 Paused: 0
Destination Groups Total: 1
Destinations grpc-tls: 0 grpc-nontls: 0 tcp: 1 udp: 0
dialin: 0 Active: 1 Sessions: 1 Connecting: 0
Sensor Groups Total: 1
Num of Unique Sensor Paths : 2
Sensor Paths Total: 2 Active: 2 Not Resolved: 0
Max Sensor Paths : 1000
Metrics収集状況の確認(SNMP)
これまでの設定によりmetrics収集が開始されました。Prometheusにて正常にmetrics収集できているか、WEB GUIにて確認を行います。
https://<Sever IP>:9090
PrometehusのWEB GUIは非常にシンプルな作りとなっています。
まずはSNMPでトラフィックデータが取得出来ているか確認します。Graph画面にて"ifHCInOctets{instance="<Router IP>",ifName="HundredGigE0/0/0/20"}"と入力しExecuteボタンを押すとValueがカウントアップしていることから正常にSNMPでデータ取得できていることが確認出来ました。
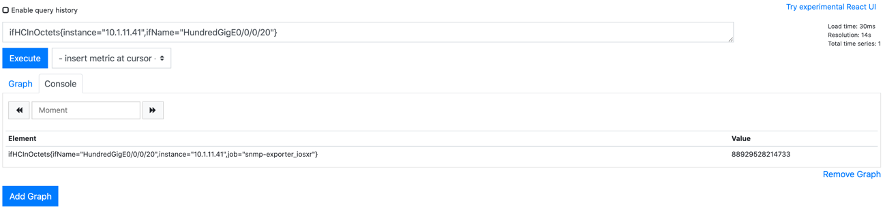
このifHCInOctestsはIFで受信した総バイト数を表示する64bit対応OIDで、標準MIBで定義されています。
RFC2863では以下が記述されています。
/// RFC 2863より抜粋 ///
ifHCInOctets OBJECT-TYPE
SYNTAX Counter64
MAX-ACCESS read-only
STATUS current
DESCRIPTION
"The total number of octets received on the interface,
including framing characters. This object is a 64-bit
version of ifInOctets.
Discontinuities in the value of this counter can occur at
re-initialization of the management system, and at other
times as indicated by the value of
ifCounterDiscontinuityTime."
::= { ifXEntry 6 }
https://tools.ietf.org/html/rfc2863
Metrics収集状況の確認(Telemetry)
続いてTelemetryでの確認を行います。同じくGraph画面にて" bytes_received{interface_name="HundredGigE0/0/0/20"}"と入力しExecuteボタン押すと、こちらも正常にデータ取得出来ているようです。
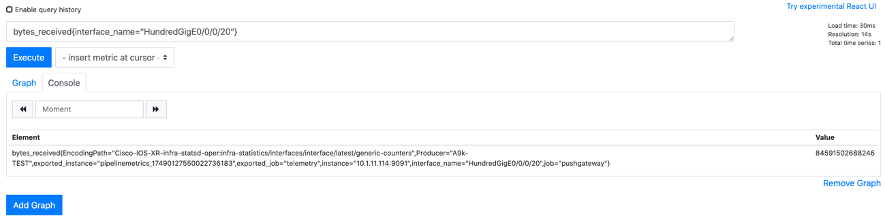
今回利用した"bytes_received"はCisco独自(Vendor Native)のデータモデルとして定義されたオブジェクトであり、SNMP MIBのifHCInOctestsとほぼ同義であることが分かります。なおこちらはGithubにて公開されています。
leaf bytes-received {
type uint64;
units "byte";
description
"Total Bytes received";
}
なお、同データモデル(Cisco-IOS-XR-infra-statsd-oper.yang)をpyangというツールで確認するとbytes_received以外にも様々なオブジェクトが定義されていることが分かります。
macbookpro$ pyang -f tree Cisco-IOS-XR-infra-statsd-oper.yang --tree-path infra-statistics/interfaces/interface/latest/generic-counters
module: Cisco-IOS-XR-infra-statsd-oper
+--ro infra-statistics
+--ro interfaces
+--ro interface* [interface-name]
+--ro latest
+--ro generic-counters
+--ro packets-received? uint64
+--ro bytes-received? uint64
+--ro packets-sent? uint64
+--ro bytes-sent? uint64
+--ro multicast-packets-received? uint64
+--ro broadcast-packets-received? uint64
+--ro multicast-packets-sent? uint64
+--ro broadcast-packets-sent? uint64
+--ro output-drops? uint32
+--ro output-queue-drops? uint32
+--ro input-drops? uint32
+--ro input-queue-drops? uint32
+--ro runt-packets-received? uint32
+--ro giant-packets-received? uint32
+--ro throttled-packets-received? uint32
+--ro parity-packets-received? uint32
+--ro unknown-protocol-packets-received? uint32
+--ro input-errors? uint32
+--ro crc-errors? uint32
+--ro input-overruns? uint32
+--ro framing-errors-received? uint32
+--ro input-ignored-packets? uint32
+--ro input-aborts? uint32
+--ro output-errors? uint32
+--ro output-underruns? uint32
+--ro output-buffer-failures? uint32
+--ro output-buffers-swapped-out? uint32
+--ro applique? uint32
+--ro resets? uint32
+--ro carrier-transitions? uint32
+--ro availability-flag? uint32
+--ro last-data-time? uint32
+--ro seconds-since-last-clear-counters? uint32
+--ro last-discontinuity-time? uint32
+--ro seconds-since-packet-received? uint32
+--ro seconds-since-packet-sent? uint32 "Total Bytes received";
今回はVendor Nativeなデータモデルを利用して検証していますが、もちろんnon Vendor Nativeなモデルも存在し、それはOpenConfigとして定義され、同じくgithubにて公開されています。
container counters {
description
"A collection of interface-related statistics objects.";
leaf in-octets {
type oc-yang:counter64;
description
"The total number of octets received on the interface,
including framing characters.
Discontinuities in the value of this counter can occur
at re-initialization of the management system, and at
other times as indicated by the value of
'last-clear'.";
reference
"RFC 2863: The Interfaces Group MIB - ifHCInOctets";
}
なお、これらCiscoのVendor Native ModelやOpenConfigはTelemetryのために専用で作られたモデルではありません。ネットワーク機器やソフトウェア内の管理や設定のために作られたモデルであり、TelemetryだけではなくNETCONFを用いた機器設定などでも利用することが出来ます。なお申し訳ございませんが今回のブログではデータモデル(YANG)のについては解説を省略いたします。
Grafanaの初期設定
続いてGrafanaダッシュボードの設定です。
https://<Sever IP>:3000 にてGrafanaへアクセスします。
ログイン設定をした後、GrafanaからPrometehusを参照するためのデータソース設定を行います。
Configuration > Data SoucesにてTime series databasesを選択し、"Prometheus"をクリックします。
HTTP URLヘhttp://<Server IP>:Portを入力したのち、"Save&Test"を押してdata sources is workingと出力されれば成功です。
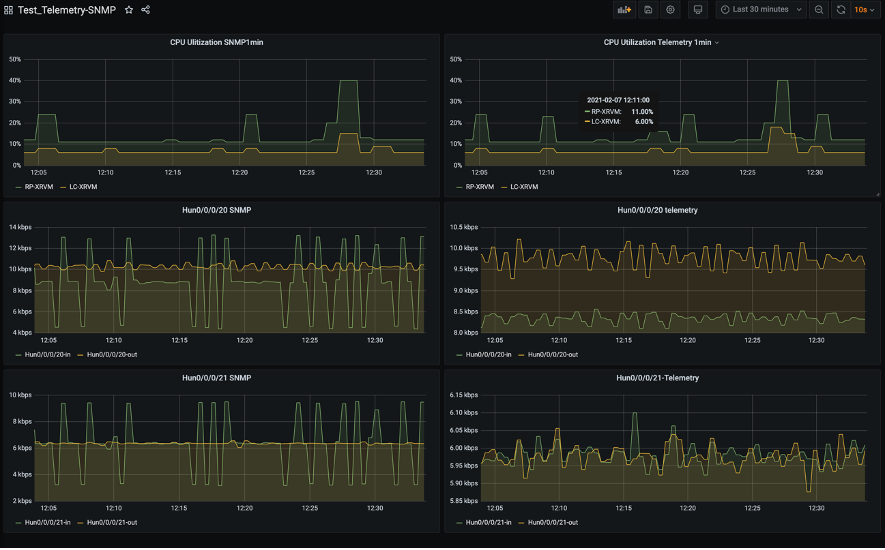
ダッシュボードを作ってみた
まずは手始めにダッシュボードを作ってみました。左列3つはSNMPで取得したもの、右列3つはTelemetryで取得したものを表示しています。いずれも左右(SNMP/Telemetry)で単一のルーターの同CPU/IFに関するmetricsをそれぞれ取得しています。
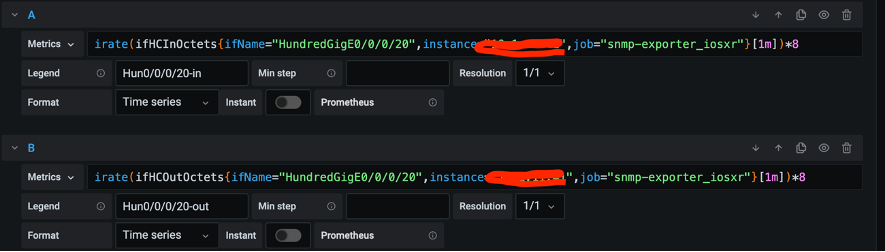
CPU(SNMP)のMetrics設定はこんな感じです。先ほどのPrometheus WEB GUIで表示された結果を参考にMetrics設定を行いました。ifHCInOctestsとifHCOutOctestsを利用してデータを取得しています。
TrafficのMetrics設定はこちらです。Bytes_receivedとbytes_sentを利用してデータを取得しています。
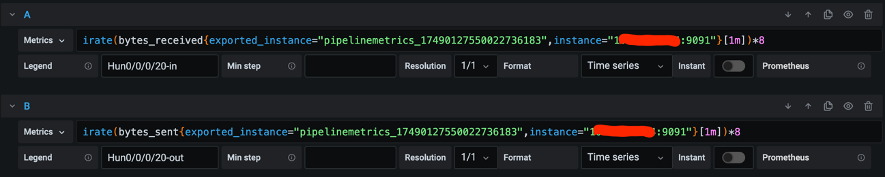
なお、これらはいずれも対象metricsがbyte形式のためPromQLというPrometheus独自のクエリ言語のirate関数を使用しbit per sec形式へ変換してグラフ化しました。
rate/irate関数は平均値算出のためバーストトラフィック(グラフの瞬間的なスパイク)を検出できない場合が想定され、まだまだ運用的な改善が必要と考えています。
動作確認①IXIAでトラフィックを生成し、ルーターにトラフィック負荷をかけてみた
今回はルーターにトラフィック負荷をかけるため、IxNetworkというアプリケーションを利用しました。
まずはデバイスの設定を行い、使用プロトコルを定義し、VLAN番号やIPv4アドレスの設定を行います。
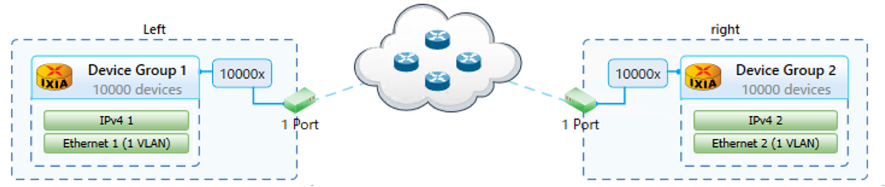
図.ネットワークトポロジー
続いてトラフィックの設定を行います。まずは500Mbpsのトラフィックが双方向で流れるよう設定します。下記図では物理IF(100GE)のため0.5%を設定しています。
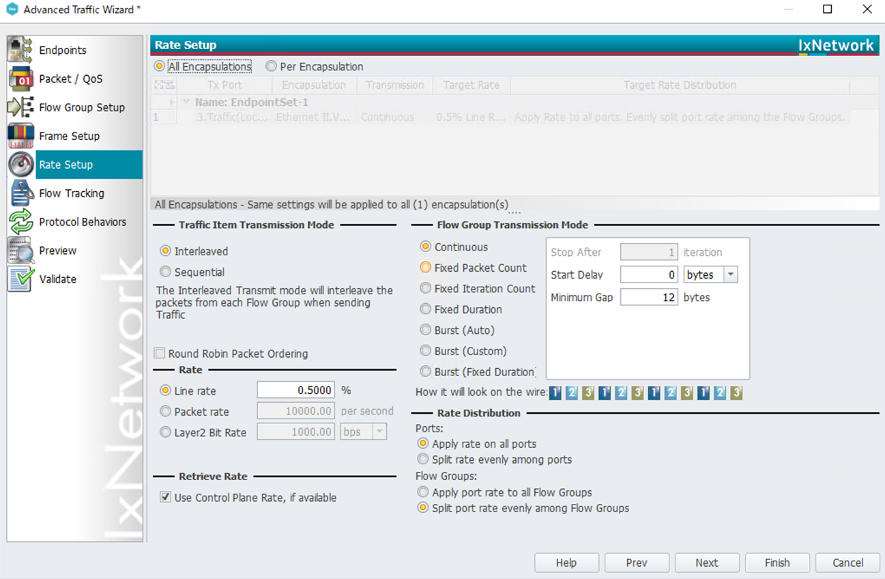
図.トラフィック設定
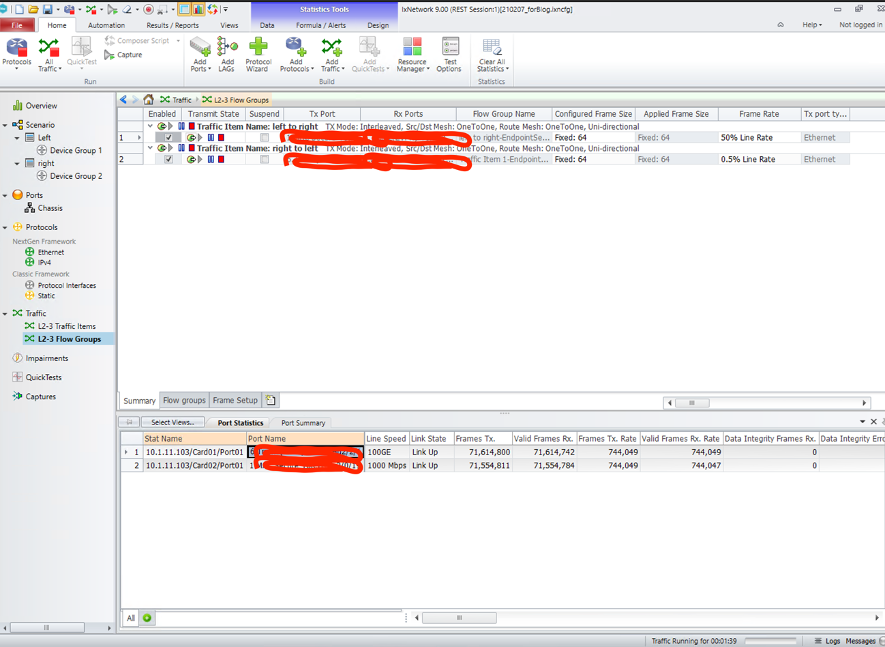
設定が終わったためトラフィック送信開始します。Port StatisticsにてRX/TX共にカウントアップしていることが分かります。
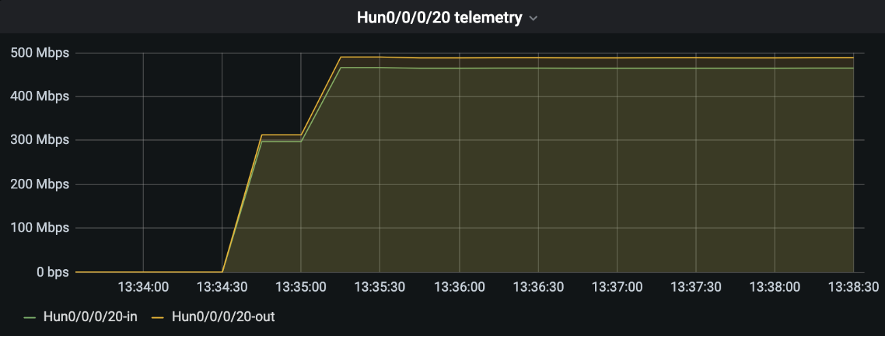
トラフィック送信開始したのでGrafanaで確認、双方向で500Mbps流れていることが確認できます!
動作確認②高トラフィックを検出し、Slackにアラートメッセージを出してみた
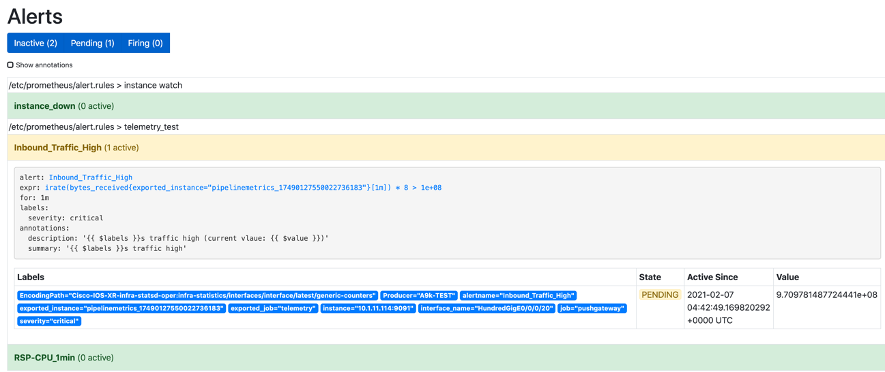
今回のPrometheus/alertmanagerについて「1Gbps超えトラフィックが1分間継続していることを検出した場合、異常判定しSlackへアラート通知設定する」よう設定しています。
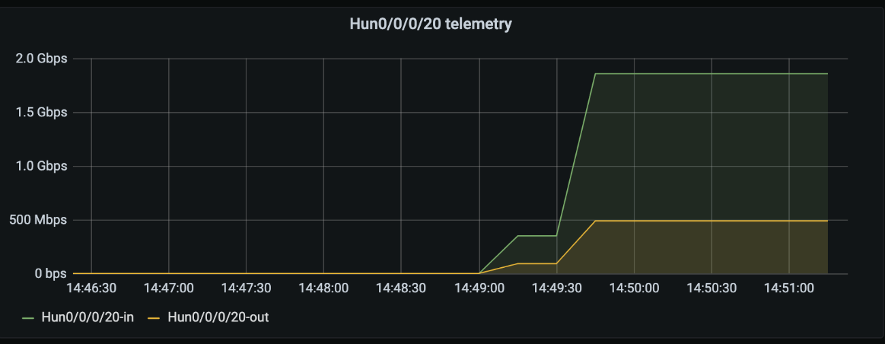
よってこのアラート動作が期待通り動作するか確認するため、片方のトラフィックを500Mbpsから2Gbpsへ変更します。果たして動作するでしょうか?
IXIA(IxNetwork)にて片フローのトラフィックレートを0.5%→2%へ変更します
Grafana上でもHun0/0/0/20-inのみ2Gbpsとなったことを確認しました。
続いてSlackにてアラートメッセージ確認できました!

PrometheusのWEB GUIでもこんな感じで確認することができます。
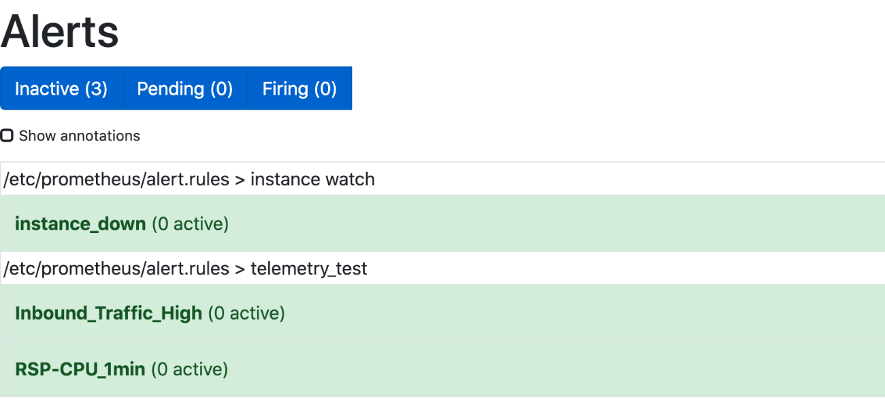
続いてIXIAのトラフィックを停止した後、少ししてからSlackにて回復メッセージを確認しました!

PrometheusのWEB GUIでも特にアラートは上がっていません。緑っぽい画面はなんだか直感的に安心しますね。
今回の成果と今後の取り組み
ここまででGrafanaやPrometheusを用いてSNMPとTelemetryを利用したルーターのmetrics取得を行い、実際の運用を想定した検証を行いました。PoCレベルではありますがなんとか動く状態を作ることが出来ました。
また今回のPoCによって冒頭で掲げた課題感に対してどの解決出来そうか比較してみました。まだまだ前途多難、これは走りながら開発運用を行っていくのもありでは?とも思えてきました。
| 課題 | 今回の成果と今後の取り組み |
|---|---|
| 監視登録やWEBページ作成について 手動ベース運用のため自動化したい |
Service discovery(file_sd)可能な構成を作れたため、 jenkins jobでtarget fileへの追加する機能を作れば楽に登録出来そう。 今後他にもっとシンプルで効率的なdiscovery方法がないのか、 またGrafana Dashboardへの自動登録について手段を模索したい。 |
| 過去のトラフィック情報を細かい粒度で参照したい | 過去のトラフィックを細かい粒度で見れるようになった。 ただしStorage容量肥大化が課題、 PrometheusのFederation機能を駆使しダウンサンプリングを行う、 またThanosを用いた拡張性の高くスケーラブルな設計などを模索したい。 |
| アラート発生時のEメール通知によりメールボックス逼迫化、 いい感じに黙認化したい |
Alertmanagerを利用しEメールではなくSlackを用いた通知を実現。 黙認機能については今後模索。 |
| SNMPで取れないMetricsを取得するためのツールを 個別に作成しているため、取得方法を共通化・シンプル化したい |
SNMPとTelemetry双方で同じ内容のmetricsを取得。 今後TelemetryにてVendor Nativeモデルのmetrics取得出来るよう模索。 |
| トラフィック情報を加工/計算したAI的なことやってみたい | PromQLを用いた簡単な計算を行った。 今後PromQLの線形予測機能(predict_liner)などを利用した トラフィック情報に基づく需要予測など ユースケースや実装方法を模索。 |
| 監視システムや監視定義を全てコード化し、 冪等性の担保されたシステムとしたい |
Monitoring system自体は全てGitでコード管理出来るようになった。 1つ目の課題同様にシンプルかつ効率的に Dashboard as a Codeを実現出来る手段を模索。 |
| 外部システム(社内システムや顧客システム)とAPI連携し データ公開可能としたい |
今回は一切検討を行っていないため 今後検討を進めてUX向上に努めたい。 |
上記以外にも現在検討中、あるいは今後検討検証したいことが沢山あり、機会があれば是非、紹介出来ればと思います。
- より実践的なツール利用法(設定、設計)
- パフォーマンス比較 SNMP vs Telemetry
- SNMP & Telemetry共存方法、使い所の模索
- フローコレクタ連携による異常トラフィックの検出
- ワークフローエンジン連携による自動障害復旧
- AWS AMP(Amazon Managed Service for Prometheus)の活用
最後に
今回は弊社おけるトラフィックモニタリングの検討について、PoCを交えて具体的な環境構築方法と共に紹介しました。
まだまだ前途多難な状況ではありますが、より安定したサービスをお客さまへ提供し続けるため、今後も積極的にこのような取り組みを継続して行なっていきたいと思います。
ご意見やご質問などありましたら是非コメントなどお寄せくださればと思います。
技業LOG
この記事に関連するサービスはこちら
InfoSphere®
障害に強い安定稼働の法人向けインターネットサービス
WebARENA®
社内システムから事業基盤まで。可用性と拡張性に優れたデータセンターサービス
Master'sONE CloudWAN®
SD‒WAN技術を活用し、即時性・柔軟性・拡張性に優れたネットワーク構築・運用を実現
ネットワークテスター / パケットブローカー
ワイヤレスエッジからインターネットコアまでのネットワークテストソリューション、
およびネットワークタップ・可視化ソリューションを提供
おすすめ記事
お気軽にご相談ください
- ※「InfoSphere」「WebARENA」「Master'sONE CloudWAN」は、NTTPCコミュニケーションズの登録商標です。