



技業LOG
NTTPCの生成AI業務変革LOG
- 活用事例/技術調査レポート -
本記事では、NTTPCが取り組む生成AIの活用事例や技術調査レポートをご紹介します。生成AIの導入により、私たちの業務やサービスの質が飛躍的に向上し、業務効率化や新たな価値創造を実現しています。
本記事を通じて、当社の生成AI活用の具体的な取り組み内容や技術的な調査結果を詳しくお伝えし、業務変革に対する積極的な姿勢を示すことで、お客さまの信頼と関心を得て、共に成長できるパートナーであることを目指しています。
目次
-
・
-
・
-
・
-
・
-
・
-
・
はじめに
OpenAIがChatGPTを発表したのが、2022年11月末。各社の開発の競争は激しく、生成AIの性能は日進月歩で進化しています。
今回は、従来とは異なる特徴を持つOpenAI o1シリーズについてご紹介します。また、ユースケースとして、東大の入試数学を解かせてみた結果を共有します。なお、本記事は2025年1月の検証結果です。
生成AIの得意なことと苦手なこと
生成AIは様々なことができますが、その中でも得手不得手があります。例として、次のようなものが挙げられます。
生成AIが得意なことの例
- 文章の要約やリライト
- アイデア出し
- プログラミング
生成AIが苦手なことの例
- 計算
- 複雑な論理
従来の生成AIは考えているわけではなく、次に来る単語を確率的に推測しているだけなので、論理が不得意であると考えられます。これらの苦手なことを克服したのが、今回取り上げるOpenAI o1シリーズです。
OpenAI o1とは
「考える」モデル
OpenAI o1は推論するモデルです。OpenAIは“o1 thinks before it answers”[1]と述べています。プロンプトにもよりますが、応答まで数十秒から1分以上かかることもあります。
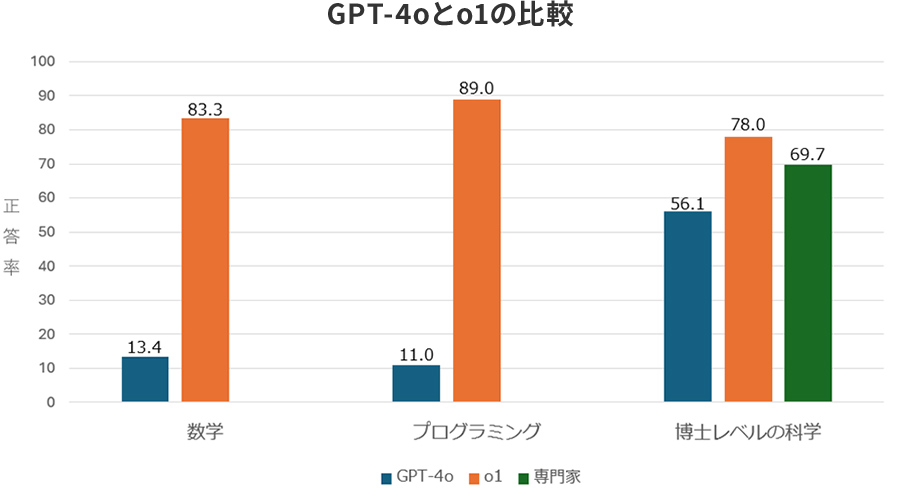
次のグラフ[2]は、既存モデルであるOpenAI GPT-4oとo1の性能を比較したものです。数学やプログラミングにおいて、o1シリーズの顕著な進歩が確認できます。特に、博士レベルの科学に関しては、専門家の人間を超える成績を残しています。
-
[1]OpenAI, “Learning to reason with LLMs”, 2024年9月12日
-
[2][1]をもとに筆者作成
論理性があることの例
「論理性がある」と言ってもイメージしづらいと思うので、例を2つ出したいと思います。
従来のモデルに答えられない質問として
- 「9.9と9.11、どっちが数字として大きい?」
- 「Strawberryにrは何個ある?」
があります。
OpenAI GPT-4oは間違えますが、OpenAI o1は正しく答えられます。
GPT-4oの誤った回答

o1の正しい回答

これらから、o1シリーズがこれまでとは違うモデルであることが理解できると思います。
東大数学を解かせてみた
OpneAI o1シリーズに東大数学を解かせてみた結果を共有します。
東大数学にした理由
そもそもなぜ東大数学にしたのか、ですが、主に以次の3点の理由からです。
- プログラミングではo1シリーズとOpenAI GPT-4oの差を見出しにくい
- 2011年から国立情報学研究所で進められていた、AIが東大に合格することを目標とする「東ロボくん」で取り組まれてきたテーマである
- 日本経済新聞の記事で大規模な特集が組まれていたので、旧モデルとの差が比較しやすい
検証の前提
日本経済新聞とAIベンチャーのライフプロンプト社による検証結果によると、2024年の東大理系数学を解かせた結果は、OpenAI GPT-4 Turbo(GPT-4oの1世代前のモデル)とGPT-4oの比較で「80点満点の文系数学は10点から21点に、120点満点の理系数学は0点から24点にそれぞれ上がっていた」[3]としています。
今回は問題文(※)だけをそのまま入力し、同じ問題(東京大学2024年度数学(理科)第1問から第6問の6問[4])を用いて検証しました。用いたモデルはo1 pro(o1よりも長く思考するモデル)とo1、o1-mini(o1の小型版)、GPT-4oの4つです。正解は河合塾の解答例[5]で確認しました。
-
※
例えば、次のような問題が出ます。何から始めたらいいかすらわからないほど難しいですね。
2024年度数学(理科)第5問
座標空間内に3点A(1,0,0), B(0,1,0), C(0,0,1)をとり、Dを線分ACの中点とする。三角形ABDの周および内部をx軸の周りに1回転させて得られる立体の体積を求めよ。
<東京大学2024年度数学(理科)から第5問のみ抜粋>
-
[3]日本経済新聞, 「ChatGPT、東大数学3カ月で0→24点 見せた「伸びしろ」」, 2024年6月26日
-
[4]東京大学, 「令和6(2024)年度第2次学力試験 数学(理科)」, 2024年
-
[5]河合塾, 「東京大学 前期 | 国公立大二次試験・私立大入試 解答速報 | 大学入試解答速報| 数学(理科)」, 2024年
検証結果
表にまとめた結果は次の通りです。
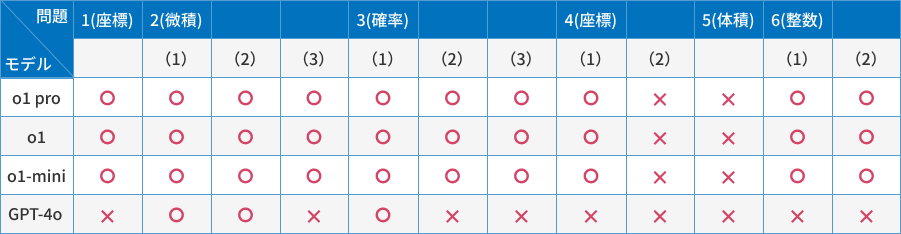
実際の入試では部分点もあるので、ここで正確な点数を明示することはできませんが、o1シリーズとGPT-4oの差が顕著でした。GPT-4oは小問を数個正解しただけにとどまったものの、o1シリーズは4(2)と5以外はすべて正解しました。
今回の検証においては、o1シリーズのo1 proとo1、o1-miniの3つで差がない一方、不正解の後に誤っていることを指摘すると、o1 proとo1は正解を導き出しました(問題文のみを与える、という条件をそろえるため上の表では不正解としています)。しかし、o1-miniはヒントを与えても、正解できませんでした。ここにモデル間の差を感じました。また、o1シリーズはモデル間の思考時間の隔たりが大きかったです。o1 proは約10分、o1は約2分、o1-miniは約30秒でした。
2025年1月末にOpenAI o3-miniシリーズがリリースされました。o3-miniシリーズはo1シリーズの後継となるモデルです。ChatGPTで利用可能なo3-miniとo3-mini-highを用いて、同様の検証を行いました。その結果は次の通りです。
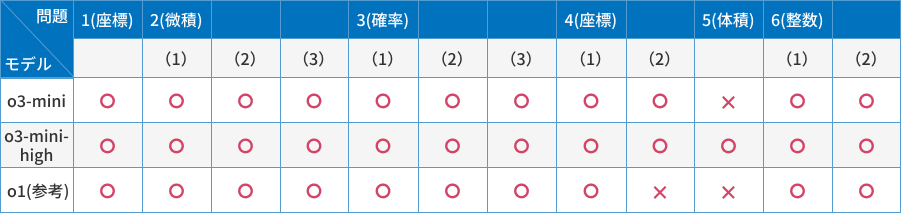
o3-miniはo1シリーズいずれも正解できなかった4(2)を正しく回答できました。そして、o3-mini-highは全問正解を達成しました。
また、思考時間はo1よりも短く、o3-miniが約30秒、o3-mini-highが約1分でした。思考時間が短くなり、かつAPIの料金も下がって、そして回答の精度は上がっている。まさに驚異的と言えます。
おわりに
OpenAIの「考える」モデル、OpenAI o1シリーズについて紹介し、ユースケースとして東大数学を解かせて、結果の差を確認しました。
従来とは異なるすさまじいモデルですが、使いどころが難しいというのもまた事実です。o1の思考力を活用できるような問いを人間が立てられるのか、が今後重要になってくるかもしれません。
今後も生成AIの最新の動向をキャッチアップしていきたいと思います。
最後まで読んでいただき、ありがとうございました。
技業LOG
NTTPCのサービスについても、ぜひご覧ください