



技業LOG
皆さま、はじめまして。本サイトにお越しくださり、誠にありがとうございます。私は、NTTPCコミュニケーションズ(以下、NTTPC)の高橋敬祐と申します。
このシリーズコラムでは、幅広い技術テーマを対象に、先進的なテクノロジーや市場動向、研究開発の取組みなど、開発者や技術者の皆さまが楽しんでお読みになれる記事を随時、更新していきたいと思います。お付き合いくだされば幸いです。
初回となる今回は、主に分散システムや仮想化の話、その中でも特に「ストレージ」の話をしたいと思います。まずは、「分散ストレージ」というものについて、知識を整理しておきたいと思います。
「グリッド・コンピューティング」から、始まった
「グリッド・コンピューティング」という言葉を聞いたことはあるでしょうか。
散在する計算機をつなぎ合わせ、リソースを集約的に管理し、必要に応じて切り分けたり、あるいは巨大で強力な計算機として利用したい、といったニーズに応えるための仕組みです。これを実現するために、専用のミドルウェアが用いられます。すなわち、ネットワークを経由してハードウェアを束ねるための、ソフトウェアによるソリューションであると言えるでしょう。
「グリッド・コンピューティング」というと、研究分野というイメージ、例えば、物理系の研究機関が計算のために行うとか、「SETI@home」や「UDがん研究プロジェクト」(※1)のように、個人の遊休計算機資源を大規模な研究に提供するといったイメージがあるかもしれません。確かに、CPUリソースを集約して得た数百テラ~数ペタFLOPS(※2)という計算能力を必要としているのは、主に自然科学の研究分野でしょう。
しかし、エンタープライズでの利用も確実に進んでいます。具体的には、GoogleやFacebookに代表される、収集したデータの解析を競争力の源泉としている企業が、分散コンピューティングという形で導入しています。「Hadoop®」を導入している企業も同様です。今日においては、「グリッド・コンピューティング」はコモディティ化しつつあります。
- ※1「UDがん研究プロジェクト」では、累計参加国数:228ヶ国、参加人数:全世界で1,341,217人、接続端末数:3,734,757台、累積解析時間:505,049年97日15時間14分34秒という規模での計算を実現しました。参考::http://komura.fc2web.com/tekito/bookmark/another_page/ud.html
- ※2「Floating-point Operations Per Second」。1秒間に浮動小数点演算が何回できるかを表す単位。パソコンの最新かつ最高峰のCPUは224ギガFLOPS、スーパーコンピュータの2013年1月における世界1位は33ペタFLOPS。ペタはテラの1000倍、テラはギガの1000倍
「グリッド・コンピューティング」のもつ、2つの側面
「グリッド・コンピューティング」には2つの側面があります。 1つの問題に対する計算(コンピューティング)を複数のコンピュータで手分けして実行する「コンピューティング・グリッド」と、計算のために必要となる膨大なデータを複数のコンピュータで手分けして保管する「データ・グリッド」です。
前者は、分割可能な計算問題を手分けして解き、それぞれの結果を突き合わせることで、結果を出します。一人で順に計算するよりも短時間で結果が出ることは、容易に想像ができるでしょう。
後者は、1台のストレージでは収まり切らない容量のデータを保管すること、さらに進んで、計算に必要なデータを上手く配置することで、前者を支援又は実現します。
「グリッド・コンピューティング」のもつ2つの側面
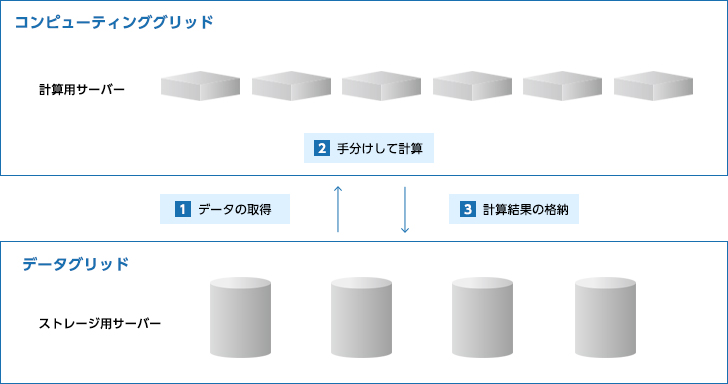
今日の「コンピューティング・グリッド」は「データ・グリッド」無しでは成り立ちませんが、「データ・グリッド」は「コンピューティング・グリッド」が無くても成立します。この「データ・グリッド」こそ、いわゆる「分散ストレージ」の根幹となる考え方なのです。
分散ストレージ
分散ストレージという言葉には、権威的な定義があるわけではありません。ここでは便宜上、「データ・グリッドを実現するストレージ・システム」としておきます。
分散ストレージが共通で持つ機能は、「データの分散配置」です。これがどういうことかと言うと、「データを複数のコンピュータに分散して配置する」ということです。 例えば、コンピュータAとBで構成された分散ストレージに、データ1とデータ2を保存した場合に、データ1がコンピュータBに、データ2がコンピュータAに、それぞれ格納されるといった具合です。これはあくまで例であり、データ1もデータ2もコンピュータAに格納される場合もありますし、それぞれのデータが分割されて、データ1とデータ2のそれぞれ半分がコンピュータAに、それぞれのデータの残り半分がコンピュータBに格納される場合もあります。
分散
データを格納するノードを複数持ち、クライアントからは透過的にアクセスできる仕組み。これにより、ノードを追加することでボリュームの容量を拡張することができる。また、ノードの数が増加するに従い、トータルでのスループットを高めることができる。
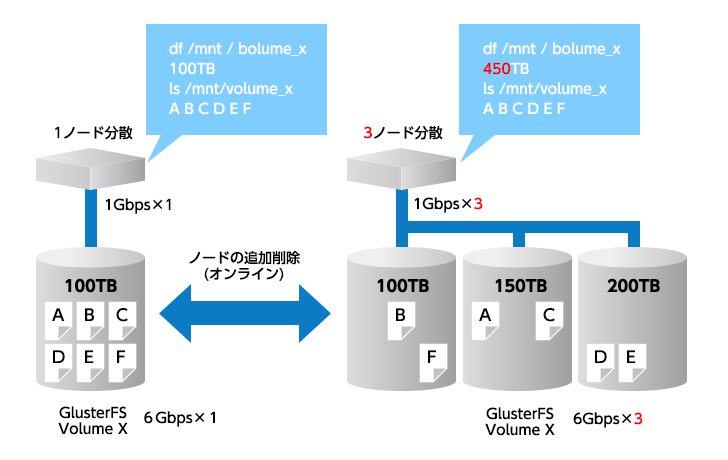
これで、コンピュータを追加すればするほど、多くのデータが格納できるようになります。しかし、これだけでは不十分です。先の例で言えば、データ1の所在をユーザ側で管理し、データに応じて接続先を手動で変えるのでは、あまりに不便です。
そこで、分散ストレージのユーザは、分散ストレージ上のデータに対して、単一のインタフェースでアクセスできるようになっています。これを、「ユーザはデータに対して透過的にアクセスできる」と言います。
例えば、ユーザはコンピュータBにあるデータ1に対してアクセスする時も、コンピュータAにあるデータ2に対してアクセスする時も、分散ストレージのミドルウェアが提供する単一のインタフェースにアクセスさえすれば、コンピュータA及びBを意識することなく、データ1及び2にアクセスすることができるのです。
そうなると、コンピュータA及びBのそれぞれの容量の合計値となる容量のストレージを、ユーザは単一のインタフェースで利用することができます。これが、分散ストレージの基本的な機能です。
データの冗長化
分散ストレージには、仕組み上の欠点があります。
それは、複数のコンピュータで構成されるため、パーツの総数が多く、従って故障点が多いということです。
分かりやすいのは、ネットワークとハードディスクでしょう。ネットワークが切れたら、その先にあるデータにはアクセスできなくなってしまいますし、データが格納されているハードディスクが故障しても同様です。
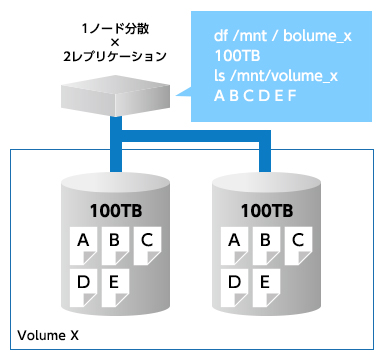
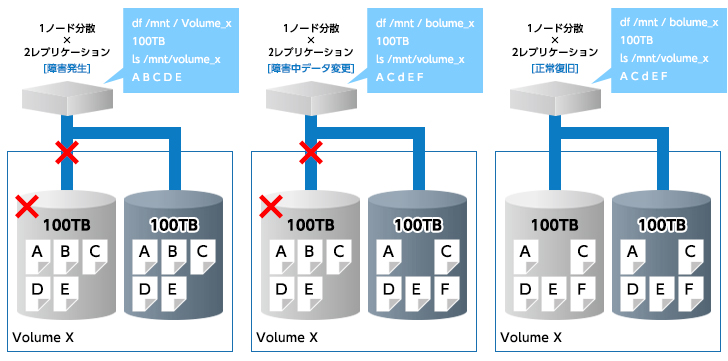
そのため、ほとんど全ての分散ストレージには、データを冗長化する機能が実装されています。単にデータを複製するものは、「レプリケーション」と呼ばれます。RAIDで例えると、RAID 1に相当します。また、よりインテリジェントな冗長化方法として、データをアルゴリズムで分割して符号を付けることで、同等以上の冗長性を少ないデータ量で実現することもできます。これは「Erasure Code」と呼ばれます。RAIDで例えると、RAID 5や6に相当します。
これらのお陰で、ネットワークの切断やハードディスクの故障が起きても、ユーザはデータにアクセスすることが可能なのです。
もちろん、多重に故障が起きた場合には、アクセスできなくなるケースはあり得ます。しかしながら、分散ストレージのアーキテクチャにもよりますが、単一のコンピュータやストレージ装置でストレージを組む場合とは異なり、単一障害点を完全に排除することも可能であるため、運用設計の負担が軽減され、結果として人的コストの削減につながるケースもあります。
データの修復
一部ノードが障害から復旧した際にデータが自動的に正しい状態へと修復される。
分散ストレージの種類
さて、分散ストレージと一口に言っても、実にさまざまなものがあります。 ただ、大きな括りとしては、分散データベースとは分けて考えたいと思います。データベースは、汎用的なストレージがもつ検索性能の限界に端を発するソリューションであり、分散データベースはその延長であるためです。
分散ストレージ、それは、大きく分けて3種類です。「分散ブロックストレージ」、「分散ファイルシステム」、「(分散)オブジェクトストレージ」です。
分散データストア
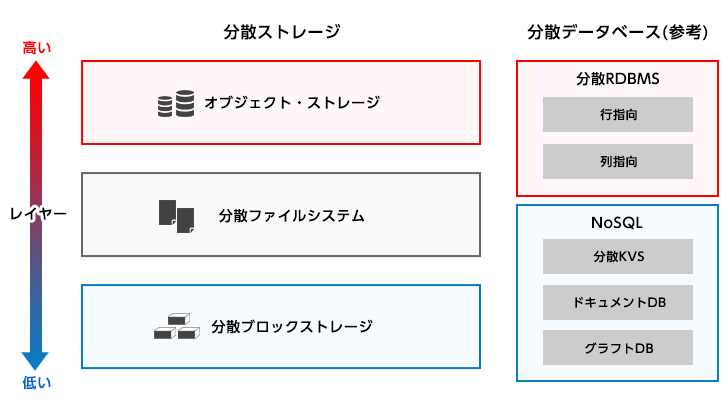
「分散ブロックストレージ」は、ロー(生の)デバイスであるブロックデバイスを、分散ストレージとして実装したものです。
OSからは単一のブロックデバイスとして認識されますが、裏側では複数のコンピュータに分散しています。SATAやSASなどのブロックデバイスに対して、OSはSCSIの命令を使ってブロックやセクタといったレベルでデータの操作をするため、iSCSIならまだしも、分散が必須要件であり、冗長化も必要となる分散ブロックストレージは、とても高度な技術です。
メジャーな実装としては、「Red Hat® Global File System」、「Ceph」、「Sheepdog」などが挙げられます。
「分散ファイルシステム」は、先に挙げた3種類の分散ストレージの中で、カバーする領域が最も広くなっています。
ファイルシステムはOSがデータをファイルとして管理する仕組みですが、狭義においては、この層で実装された分散ストレージということになります。広義では、他の分散ブロックストレージやオブジェクトストレージのことも分散ファイルシステムと呼ぶこともありますが、ここではこれらを区別するために、狭義の分散ファイルシステムという意味合いで、この言葉を使います。
「データの分散配置」と最も相性が良いのは、この層でしょう。分散ファイルシステムは、OSに代わって、どのファイルをどこに分散配置するかを管理します。
ところで、「UNIX」には「すべてをファイルとして表現する」という思想があり、その系譜にあるOSはPOSIXという標準的なインタフェースを持っています。ユーザは、POSIX準拠のインタフェースを使って、ファイルにアクセスします。
「分散ファイルシステム」も同様で、POSIX準拠のインタフェースでファイルにアクセスするものが主流です。そしてこれは、FUSE (Filesystem in USEr space) で実装されるケースが多いです。FUSEについては、この場では解説しませんが、「ファイルシステムでない何かに対してファイルシステムのようにアクセスできるようにするもの」と考えると分かりやすいと思います。FUSEを導入すれば、分散ファイルシステムの開発者は、ミドルウェアとしての実装に専念できるのです。
「分散ファイルシステム」のメジャーな実装としては、「GlusterFS」、「Lustre」、「Coda」などがあります。
最後に、「オブジェクトストレージ」の紹介です。これは、他の2つとは異なり、OSや「UNIX」の思想とは完全に切り離された概念です。データはオブジェクトとして存在し、POSIXとは異なるAPIでアクセスされます。
メジャーな実装としては、「Amazon S3™」や「OpenStack® Swift」で、これらはオブジェクトをHTTPのRESTで表現しています。
いかがでしたでしょうか? 先にも挙げましたが、「分散ファイルシステム」の代表的な実装として、「GlusterFS」があります。次回以降は、この「GlusterFS」に関して、詳細を追っていきたいと思います。
おすすめ記事
お気軽にご相談ください
- ※Hadoop は、Apacheソフトウェア財団の米国及びその他の国における登録商標です。
- ※Google および Google ロゴは、Google Inc.の商標または登録商標です。
- ※Facebook およびFacebook ロゴは Facebook,Inc.の商標または登録商標です。
- ※Red Hat、RPMおよびRed Hatをベースとしたすべての商標とロゴは、Red Hat, Inc.の米国およびその他の国における登録商標または商標です。
- ※UNIX は、X/Open Co.,Ltd.社の米国およびその他の国での商標です。
- ※Amazon Web Services、“Powered by Amazon Web Services”ロゴ、および Amazon S3は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。
- ※OpenStack の商標とロゴは、OpenStack Foundation の商標または商標登録です。