



技業LOG
ネットワーク事業部 技術開発部 システム開発担当 ストレージチームの高橋です。分散ファイルシステム、とりわけGlusterFSに対する取り組みを開始して早5年目。現在は自社および他社の複数のサービスに導入されており、将来的な導入の検討も複数のプロジェクトで行われています。
私の所属するチームは、これらに対する技術支援、技術提供を行ってきました。今回は、GlusterFSの概要と、その分散アルゴリズム「Elastic Hash Algorithm」について解説を行います。
GlusterFSの概要
GlusterFSは、オープンソースの分散ファイルシステムです。NFS又はFUSEを利用したPOSIX準拠のインタフェースをもつNASとしての利用が可能で、バージョン3.3からはAmazon S3ライクなREST APIにも対応します。ファイルストレージとオブジェクトストレージの2種類を提供可能な汎用性の高さは、OSSの分散FSの中でもユニークであると思います。
一方、すべての分散ストレージに共通の特徴、それはスケーラビリティです。GlusterFSはElastic Hash Algorithm (以下EHA) というアルゴリズムを使ってデータの分散とノンストップでのスケールアウトを実現していますが、英語 / 日本語ともに文献が十分とは言えません。本記事ではこのアルゴリズムをできるだけ分かりやすく解説したいと思います。
Elastic Hash Algorithm以前
EHAの解説を始める前に、それが実装される以前について少しだけお話したいと思います。GlusterFSにEHAが導入されたのは、バージョン3.1になってからでした。それ以前のバージョン3.0までは、ALU (Adaptive Least Usage)、NUFA、Random、Custom、RR (Round Robin)といったI/Oスケジューラを使ってデータを分散していました。この中で一番賢いのはALUですが、いずれにしてもノンストップでスケールアウトすることができない、すなわち追加したノードを認識するために一瞬の断が発生する (マウントポイントを再マウントすることで新しい設定を読み込むため)という弱点がありました。
Elastic Hash Algorithm
GlusterFS 3.1以降は、設定・管理用デーモンであるglusterd、そしてクライアントデーモンであるglusterfsdとが連携して、EHAを用いたノンストップでのスケールアウトを実現しています。
お待たせしました。ここからEHAに関して、分散ハッシュテーブルをモデルに解説していきます。
Hash Algorithm
ハッシュアルゴリズムについては、皆さんご存知の通りになります。EHAも通常時は単なる分散ハッシュアルゴリズムです。以下に例を示します。なお、単純化のため、ここではハッシュ値のレンジを0~1199とします。
図1. 初期状態 (例)
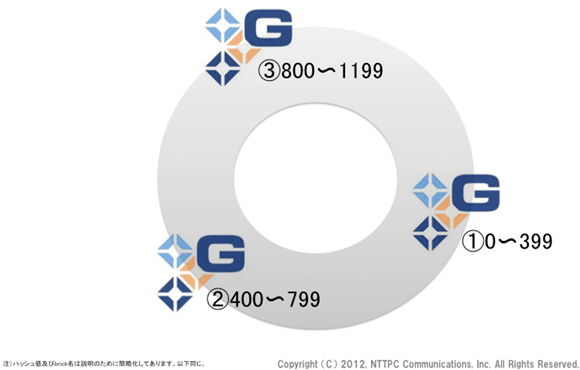
GlusterFSにおいて、1つのクラスタストレージ領域をボリュームと呼びます。ボリュームを構成する各ノードに割り当てられたデータ格納領域をbrickと呼びます (ノード名とファイルシステム上のパスとのペアで表現)。また、登録されたノードの集合を一般的にクラスタと呼びます。
GlusterFSのbrickをピアとし、分散ハッシュテーブル (以下DHT)にマッピングします。このボリュームでは、①②③の3つのbrickに対し均等なレンジでハッシュ値のレンジを割り当てています。データは、これらのbrickのいずれか1つに格納されます。それをハッシュ計算で決定します。
図2. ファイルの入力 (ハッシュ値の計算)
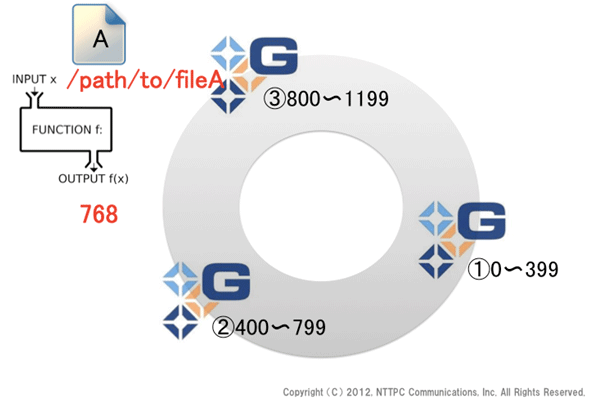
このボリュームに、fileAを格納することとします。ボリューム内での絶対パスは/path/to/fileAです。ハッシュ関数にかけた結果、ハッシュ値は768となりました (あくまで例です)。この数値に対応するbrickにfileAを格納します。
図3. ファイルの入力 (brickへの格納)
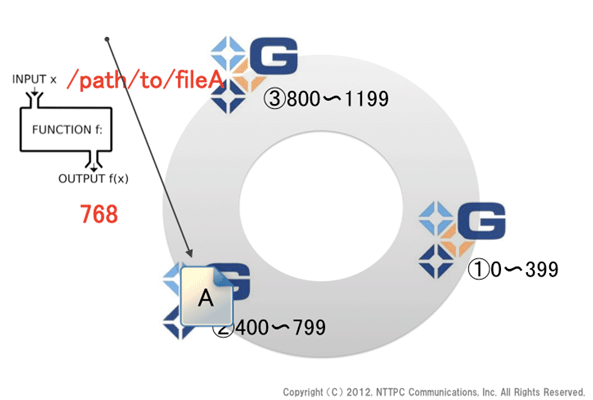
ハッシュ値から、brick②へ格納されました。brick②がこのボリュームに対して/path/to/brickというパスを提供しているとすると、brick②のローカルファイルシステム上では、fileAの絶対パスは/path/to/brick/path/to/fileAになります。一方、このボリュームをマウントしたクライアントからは、/path/to/mountpoint/path/to/fileAといった形で認識することになります。
ElasticなHash Algorithm
以上は何の変哲も無いHashing Algorithmです。ではどうElastic (伸縮性のある≒スケーラビリティのある)なのか。それを、brick追加によるボリューム拡張シーケンスで確認していきましょう。
図4. brick追加直後の状態(1)
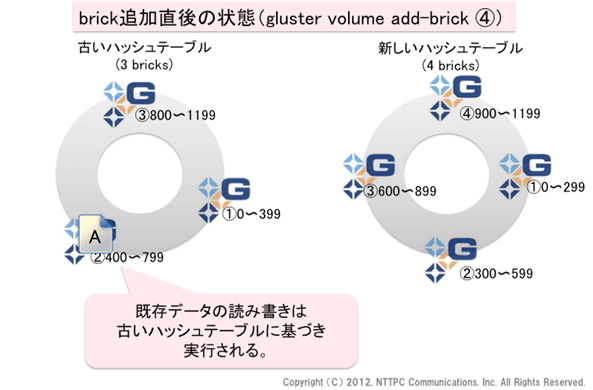
gluster volume add-brick コマンドで、新たなbrick ④を追加します (ボリューム名とbrick名が引数として必要です)。すると、このボリュームは、内部的に2つのハッシュテーブルを持つことになります。図4において、左側がbrick追加前のハッシュテーブル、右側がbrick追加後のハッシュテーブルです。最終的には右側に統一するのですが、それはデータの再配置が完了した後になります。
図5. brick追加直後の状態(2)
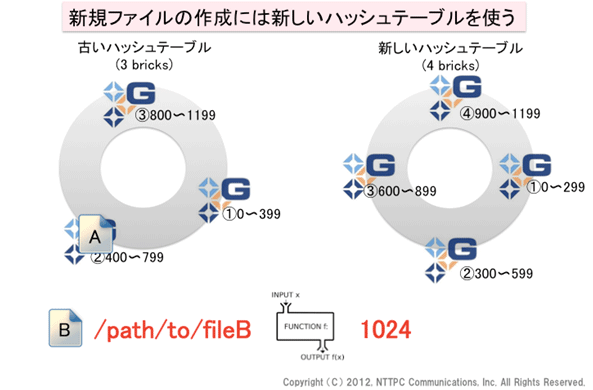
データの再配置は、gluster volume rebalance コマンドで開始します (ボリューム名やstart等の引数が必要です)。ここではまだこれを実行していません。既存データへの読み書きの際は、古いテーブルを使用します。
fileAは既にbrick②に格納されているので、fileBを格納してみます。ハッシュ値は1024と出ましたが、古いテーブルだとbrick③、新しいテーブルだとbrick④が該当します。どちらが使われるのでしょうか?
図6. 新規ファイルの作成には新しいハッシュテーブルを使う
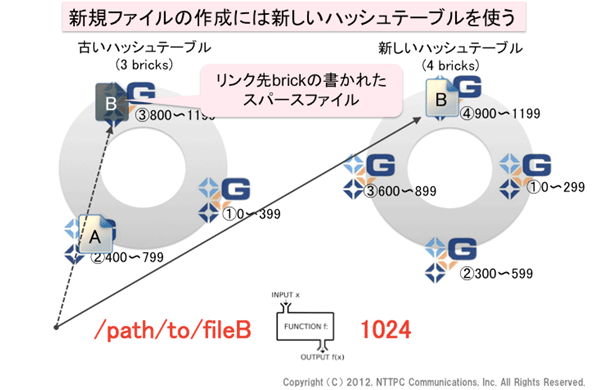
新旧2つのハッシュテーブルを持っていますが、新規ファイル作成には新しいハッシュテーブルを使います。ですので、ファイルはbrick④に格納されます。しかし、古いハッシュテーブルを使ってアクセスされるとbrick③にアクセスされてしまいます。そこにfileBはありません。
そこで、brick③の同じパスに、スパースファイルを生成します。このファイルには拡張属性にリンク先のbrick名が記録されていて、ファイルの実体に対するポインタ的な役割を果たします。
図7. rebalanceを実行(1)
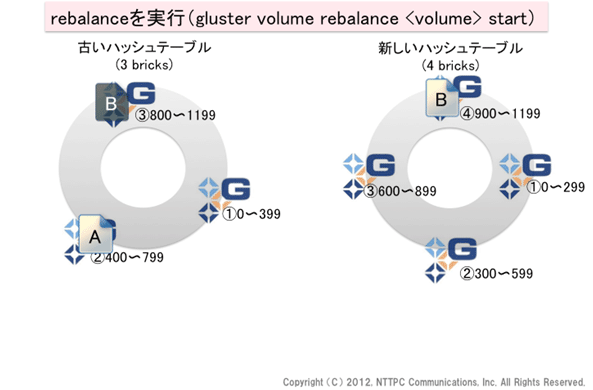
さて、ここでファイルの再配置を行います。メタデータサーバーが無いファイルベースの分散ストレージ全般に言えることですが、データの分散配置にハッシュアルゴリズムを使用する以上、ピア数の変更に伴うデータの再配置は避けられません。
図8. rebalanceを実行(2)
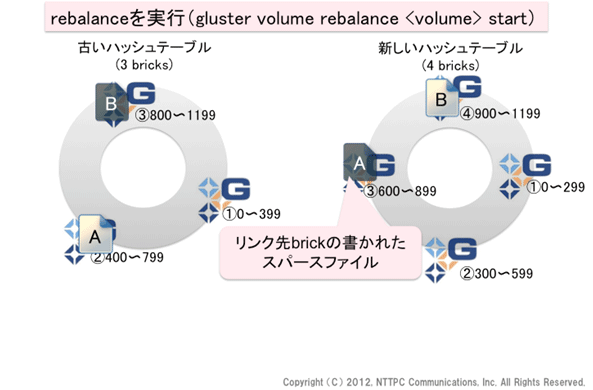
rebalanceをスタートすると、まずすべてのファイルについてハッシュ値が計算され、データ移動の要否が検討されます。fileAのハッシュ値は768でしたので、古いテーブルではbrick②に格納されていましたが、新しいテーブルではbrick③に格納されることになります。再配置が必要なデータについては、移動先brickにスパースファイルが生成されます。このスパースファイルも拡張属性にリンク先brickの情報が記録されていて、新しいテーブルを使って移動前のデータにアクセスしようとした場合でも、データの実体にアクセスできるようになっています。
図9. rebalanceを実行中(1)
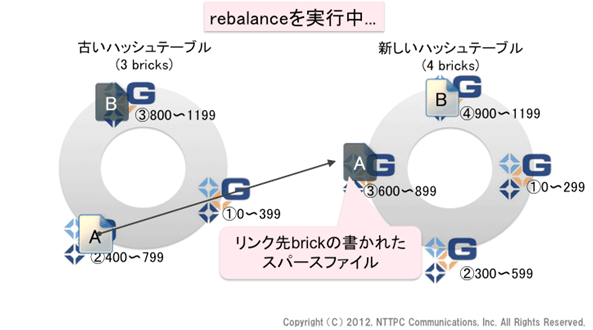
そして、brick②にあるfileAをbrick③へとコピーします。
図10. rebalanceを実行中(2)
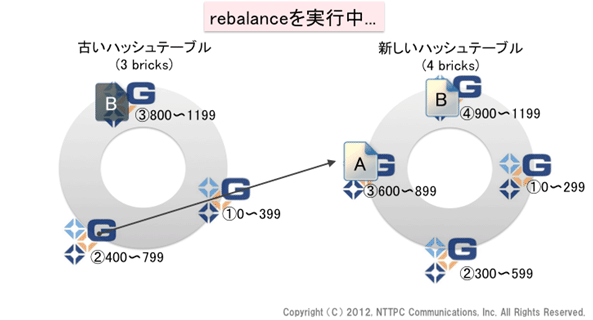
コピーが完了しました。brick②からfileAを、brick③からスパースファイルを、それぞれ削除します。
rebalance処理は、まだ終了していません。ここで新規ファイルが作成されたら、どうなるでしょうか?ハッシュ値384のfileCを生成してみます。
図11. rebalanceを実行中(3)
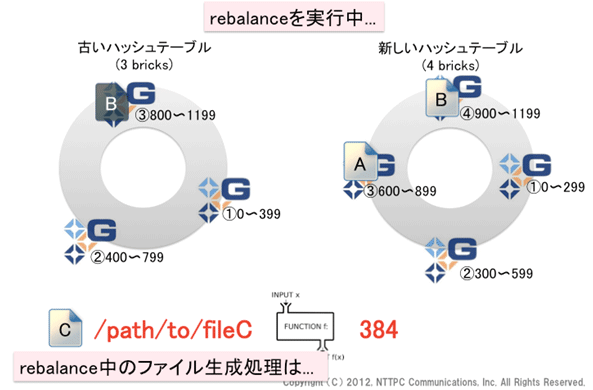
図12. rebalanceを実行中(4)
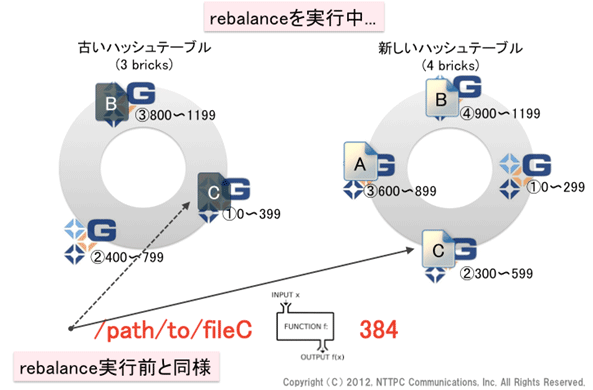
先ほどadd-brick後にfileBを生成しましたが、rebalance完了前であれば、fileCの新規作成に関しても動作は同じです。
さて、ここでrebalanceが完了しました。
図13. rebalance完了(1)
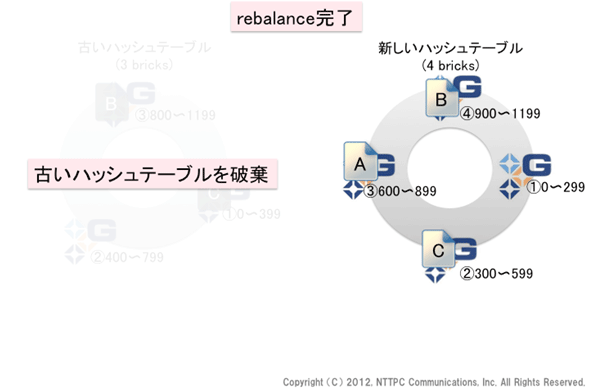
古い分散ハッシュテーブルが破棄されます。これからは新しいハッシュテーブルのみが使用されます。
実際のハッシュテーブルとファイルとの関係を示すと、次の図の通りです。
図14. rebalance完了(2)
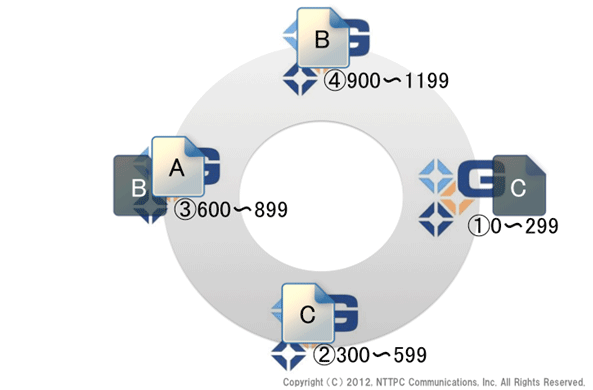
何と、スパースファイルが残ってしまっています。rebalanceに用いるスパースファイルはその処理の中で削除されたのですが、rebalanceの中で便宜的に生成されたスパースファイルは、削除対象にはなりません。
もちろん、このハッシュテーブルを使用する限りは、常にファイルの実体にアクセスすることになるため、残ってしまったスパースファイルにアクセスすることはありません。また、クライアントのマウントポイントにも表示はされません。ですので、ユーザ側から見た不都合は特にありません。
ただ、スパースファイルは0バイトといえどinodeを消費します。そのため、このスパースファイルが異常なまでに大量生成されると、inode数が枯渇する危険性が無いとは言えません。システムによっては、brick側でファイルシステムのフォーマット時にinodeサイズを小さくしてその数を増やしたり、監視項目にinode数を含めると良いでしょう。
特殊なケースでの振る舞い
以上がElasticなアルゴリズムに関する解説でした。もう一つ、ハッシュベースで分散させるファイルストレージにつきものの問題である「データの偏りとディスク・フル」を、GlusterFSがEHAの中でどのように解決しているかを解説します。
一番最初に登場した分散ハッシュテーブルで、brick②にデータが偏ってしまい、ディスク・フルとなってしまったケースを想定します (極端な例です)。
図15. 一部brickがディスク・フルの状態
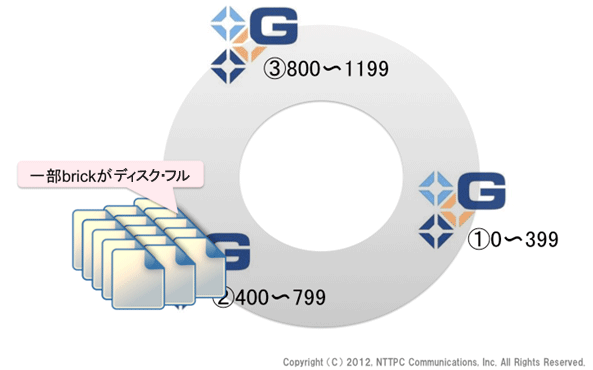
brick②のローカルファイルシステム上でdfコマンドを実行すると、使用率が100%の状態です。ここに、fileAを作成します。ハッシュ値は768ですので、ディスク・フルとなっているbrick②に格納されることになります。
図16. 新規ファイル作成
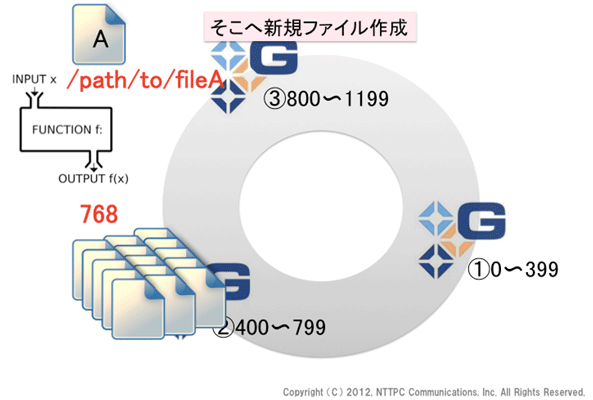
しかし、brick②にはfileAを生成するためのスペースがありません。どうなるのでしょうか。
図17. 実体は書き込み可能なbrickへ
brick②には拡張属性にリンク先情報が書かれたスパースファイルが生成され、実体は別のbrickに格納されます。
そのため、容量の少ないマシンをbrickに割り当てたとしても問題無く動作するというわけです。
まとめ
以上、GlusterFSのElastic Hash Algorithmについて解説を行いました。GlusterFSはEHAを使うことにより無停止でスケールアウトすることが可能ですが、その特徴は新旧分散ハッシュテーブルの共存とリンク先情報を記述したスパースファイルにあります。ご理解できましたでしょうか。
GlusterFSは機能毎にモジュール構造になっており、分散以外にもレプリケーションやストライピングなどのクラスタ機能を持っています。また、オブジェクトストレージのインタフェースも追加されました。今回紹介できなかったこれらの機能に関しては、別の機会に解説できればと思います。
参考文献
- Gluster Community - Gluster Information Wiki
http://www.gluster.org/community/documentation/index.php/Main_Page - Introduction to GlusterFS Webinar - September 2011
http://www.slideshare.net/Gluster/introduction-to-glusterfs-webinar-september-2011 - Keisuke Takahashi's Presentations
http://www.slideshare.net/keithseahus