

RDBエンジニアのための10分でわかるDocumentDB
【技業LOG】技術者が紹介するNTTPCのテクノロジー

ソフトウェアエンジニア(Webアプリケーション)
大津 三記男
取得資格:PMP(Project Management Professional)/ VMware Certficated Professional on vSphere 5 / Ruby Association Certified Ruby Programmer Gold / ORACLE MASTER Silver Oracle 9i / テクニカルエンジニア(ネットワーク) / LPIC レベル1 / UMTP L1

技業LOG
DocumentDBはMicrosoftのAzure上で利用できるPaaS型のNoSQLデータベースです。以前は個別のサービスとして提供されていましたが、2017年5月からは複数の種類のNoSQLを包括的に提供する「Azure Cosmos DB」の一部となりました。本記事では、OracleやSQL ServerなどのRDBをメインに扱ってきた方を対象に、RDBとの違いやサービスの特徴などをご説明したいと思います。
1. DocumentDBの位置づけ
最初にNoSQLデータベースの中でのDocumentDBの位置づけから説明します。
NoSQLは格納するデータの構造によって幾つかの種類に分類されます。一般的な分類は次の通りです。
| 分類 | 格納できるデータの構造 | データの例 | |
|---|---|---|---|
| KVS | キーバリュー | 1つのキーに対して1つの値だけを持つデータ | { "10003": "佐藤" , "10004": "鈴木" , "10005": "田中" } |
| 列指向 | 1つのキーに対して、不定形の複数の値を持つデータ | { "10003": { "名前":"佐藤", "性別": "男" }, "10004": { "名前":"鈴木", "年齢": 20 , "出身": "埼玉"}, "10005": { "名前":"田中", "出身": "東京" } } |
|
| ドキュメント指向 | JSON形式に代表される階層構造をもったデータ | [ { "学籍番号": "10003", "基本情報": { "名前":"佐藤", "性別": "男" }, "趣味" : [ "映画", "音楽", "ドライブ" ] }, { "学籍番号": "10003", "基本情報": { "名前":"鈴木", "年齢": 20, "出身": "埼玉" }, "テスト結果": { "英語": 80, "国語": 70 } }, { "学籍番号": "10005", "基本情報" : { "名前":"田中", "出身": "東京"}, "サークル": [ "テニス", "スキー" ] } ] |
|
この他にも、グラフ型のデータを格納する「グラフ指向」のNoSQLもあります。
名前のとおりDocumentDBはドキュメント指向のデータベースです。事前にスキーマを決める必要がなく、JSON形式のデータ(ドキュメント)をそのまま格納できることから、RDBや他のNoSQLと比べて自由な構造のデータを扱えます。同じドキュメント指向のデータベースとしてはオープンソースのMongoDB、Couchbase Serverなどがあります。
2. RDBとDocumentDBの比較
次に、アーキテクチャやデータ操作におけるRDBとDocumentDBの違い、RDBに対するDocumentDBの優位性などを説明します。
2.1 アーキテクチャ
RDBにはデータを格納する「テーブル」の他、一連のデータ操作をまとめた「ユーザ定義関数(Function)」や、データの生成・更新のタイミングで自動的に処理を起動する「トリガ(Trigger)」などのスキーマがあります。DocumentDBでも「コレクション」と呼ばれるデータを格納するコンテナの他、RDBと同じユーザ定義関数やトリガなどの機能をリソースとして持ちます。これらの関係を図示すると次のようになります。
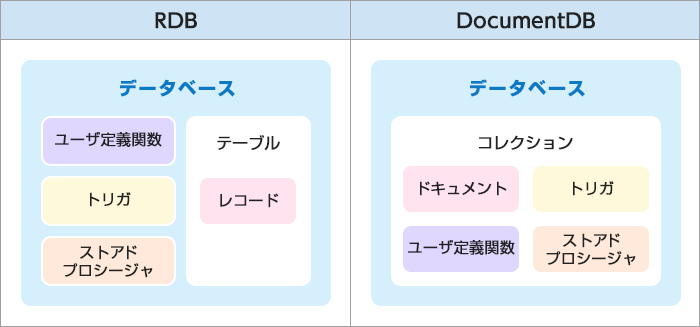
RDBとDocumentDBを比較するとユーザ定義関数やトリガの位置づけが少し異なります。
RDBにおけるこれらのスキーマはテーブルと独立して存在しており、複数のテーブルにまたがった処理が可能です。
それに対して、DocumentDBのユーザ定義関数やトリガはコレクションの中にあります。外部キーなどでお互いの関係を定義できるテーブルと違い、コレクションは互いに独立したリソースであり、ユーザ定義関数やトリガも単一のコレクションのみを対象として動作するため、このような関係になっていると考えられます。
また、RDBとDocumentDBではユーザ定義関数やトリガの実装方法も異なります。RDBではPL/SQLやTransact-SQLなどの独自言語を使いますが、DocumentDBではJavaScriptで記述できます。汎用的な言語で記述できることから、RDBと比較して実装のハードルは低いと言えます。
2.2 インデックス
RDBでは、主キーや一意キーには自動的にインデックスが作成されますが、それ以外は明示的に作成する必要があります。
DocumentDBの場合、ドキュメント全体に自動的にインデックスが作成されるのがデフォルトの動作です。ただ、自動的に作られるのは便利な反面、インデックス作成に伴うオーバーヘッドやストレージ領域の消費という点では好ましくありません。
そこで、オーバーヘッドやストレージ領域を最適化するために、インデックス作成のポリシーを変更することも可能です。主な設定項目は、インデックスを作成するパス、作成するインデックスの種類(ハッシュ、範囲)です。DocumentDBでは、ドキュメントの書き込み・読み込みに対する待機時間がSLAで保証されているため、インデックスを調整してもパフォーマンスには大きく影響しません。しかし、DocumentDBにおける課金の基準となる独自単位「RU(要求単位)」を最適化することはできます。適切にポリシーを設定すればRUを小さくでき、DocumentDBの課金を低く抑えることも可能です。
2.3 データの操作
RDBでは主にSQL文を使ってデータの参照・更新を行います。
DocumentDBでは次の方法でリソースの参照・更新を行うことが可能です。
-
REST API
DocumentDBでは各リソースに対するRESTfulなアクセスをサポートしています。URIで操作対象のリソース、HTTPメソッドで操作種別を指定し、事前に取得した認証トークンや各種属性情報をHTTPヘッダに付加した上でリクエストを行います。これらの処理を自前で実装するのは大変ですが、各プログラミング言語向けに提供されているクライアントSDKを使えば、RESTアクセスをラッピングしたクラスによって、リソースの参照・更新が簡単にできるようになっています。
-
DocumentDB SQL(SQLクエリ)
REST APIでは単一ドキュメントの取得しかできませんが、DocumentDB SQLを使えばSQLライクな記述で複数のドキュメントを検索・取得できます。
DocumentDB SQLは独自のSQLクエリですが、一般的なSQL文と似た記法で、where句やorder by句を使え、算術関数や文字列関数などの各種関数も用意されています。ユーザ定義関数を呼び出すこともできるので、事前に定義しておけば複雑な正規表現による検索も実現可能です。
なお、DocumentDB SQLで使えるのはselect文だけです。insert文やupdate文はありません。リソースの生成や更新などの操作は、REST APIやクライアントSDKを使う必要があります。
2.4 DocumentDBの優位性
ドキュメント指向のDocumentDBにおける大きなメリットは、スキーマレスで、JSON形式のデータをそのまま格納できることです。
昨今は、一般公開されているWebサービス(APIサービス)と連携するシステムや、複数のサービスが連携するマイクロサービス型のシステムなど、JSON形式のデータを扱う機会が多くなっています。
JSONデータには可変長の配列やハッシュデータが含まれており、構造が深くネストしている場合もあります。このようなデータをRDBに格納する場合、利用するデータを取捨選択し、その関連性や多重度を検討した上でテーブルを定義する必要があります。また、JSONの中で利用したいデータが増えたり、JSONのデータ構造が変わったりすると、それに合わせてテーブル定義も見直さなければいけません。カラムの追加程度ならいいですが、テーブルの分割となるとシステムへの影響も大きくなります。それに対してDocumentDBであれば、初期のテーブル定義も、その後の見直しも必要ありません。
JSONデータを扱うシステムを構築する場合、初期に要件を固めるウォータフォール型の開発ならRDBでも問題はないかもしれません。しかし、仕様変更の頻度が高くなるアジャイル型の開発の場合、DocumentDBのほうが開発スピードを早くできる可能性が高くなります。
3. データの保護
最後にDocumentDBにおけるデータ保護機能として、レプリケートとバックアップについて説明します。
3.1 レプリケート
DocumentDBでは、同じリージョン内の複数レプリカにリソースを保存します。プライマリのレプリカに障害が発生してもセカンダリのレプリカに透過的にフェイルオーバーするため、99.99%という高い可用性が保証されています。
さらに、他のリージョンにレプリケーションする設定も可能なので、簡単にグローバルな分散データベースを実現できます。
3.2 バックアップ
バックアップは約4時間毎に自動的に取得され、最新の2つのバージョンがBlobストレージに保存されます。Blobストレージのgeo冗長ストレージを使えば、他のリージョンにデータをレプリケートできるので、ディザスタリカバリーにも対応可能です。
自動バックアップされているデータを使えば8時間以内の状態まではデータを戻すことができます。ただ、現時点(2017年7月)では、バックアップからのリストアを自分たちで行うことはできません。Azureのサポートに別途依頼が必要となります。
また、スケジュールの指定や任意のタイミングでバックアップする機能も提供されていません。もし必要な場合には、Azure Data Factoryなどの他のサービスを活用するなどして、独自にバックアップの仕組みを作る必要があります。
4. まとめ
本記事ではRDBと比較しながらDocumentDBの特徴などを紹介しました。
JSONを扱うシステムをアジャイル型で開発する場合、ドキュメント指向データベースは有力な選択肢となります。また、他のオープンソースのソフトウェアと比較して、AzureのDocumentDBは簡単に利用を開始できるうえ、自動レプリケートや自動バックアップなどの機能が充実しており運用負担も軽減できます。書き込み・読み込みの待機時間がSLAで保障されているためパフォーマンス面でも安心です。
ただ、実際の利用にあたって課題が全くないわけではありません。特に大量のデータを扱うようになると、課金の基準となるRU(要求単位)に悩まされることが多くなります。書き込み・読み込みのデータ量を運用前にシミュレートしておかないと、運用後にRUの上限を超えることでエラーが多発したり、想定以上の運用費用が必要になってしまいます。
それらの課題点も理解したうえでDocumentDBを有効に活用していただければと思います。