



技業LOG
若手社員による技業挑戦LOG
- 技術トレーニング実施レポート -
本記事は、NTTPCの若手社員育成施策である「トレーナー施策」の参加者が、実施した技術トレーニングの内容を紹介しています。
参加者にはトレーナーがアサインされ、課題設定からシステム構築、発表という一連の流れを経験しました。
この取り組みによって、部署をまたいだつながりの形成やコミュニケーションの活性化、技術力の向上などが促されることを目指しています。
目次
はじめに:おいしいコーヒーとは?
皆さんはコーヒーがお好きでしょうか。
朝起きてからの1杯、仕事中に気合を入れるための1杯、おやつと一緒に1杯、コーヒーはあらゆる形で私達の日常で消費されています。近年では、お気に入りの喫茶店に通い詰めたり、焙煎直後の豆を購入し家で挽きたてを楽しんだりと、より多くの人が品質の良いコーヒーを求めるようになりました。
しかし、そんなコーヒーの風味に影響を与える"欠点豆"と呼ばれる豆がいくつか存在します。これらのコーヒー豆は、生育や保管状態が影響して変質を起こしているため、焙煎時の熱の伝わり方に影響が出たり、不快な酸味を出したりと厄介な存在です。
焙煎前にこれらの豆を取り除く作業(ピッキング)を行う店舗も存在しますが、豆全体の約10%存在すると言われる欠点豆を目視で判別し、手で取り除くというのは途方もない作業です。

設定した目標はコーヒー豆を見分ける"目"
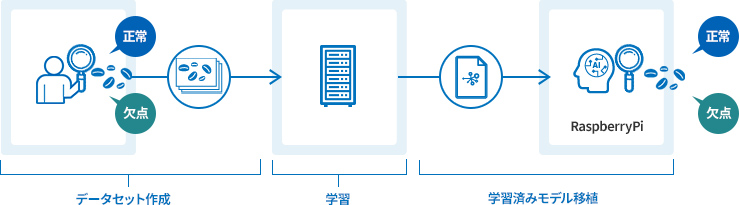
上記の問題を解決するため、人手を介さないコーヒー豆の自動ピッキングの仕組みを考えます。実現のためには、正常豆と欠点豆を仕分ける"目"と"手"が必要になりますが、今回は深層学習によってコーヒー豆を見分けられる"目"の作成を目指します。
また、自動ピッキングは小型の仕分け機で行うことを想定し、Raspberry Pi(ラズベリー パイ)のようなマイコン上で動作するような形とします。手順は次の通りです。
- データセットの作成
- 処理能力が高い環境で学習を実施
- 学習済みモデルを実稼働端末(Raspberry Pi)に移植
データセットを作成してみる
1. 撮影
はじめに、データセット作成のため焙煎前のコーヒー豆(生豆)の撮影を行います。今回は生豆から正常豆400粒、欠点豆400粒を抽出し、合計800粒を撮影対象とします。次に、この中から10粒を無作為に取り出し、生豆の表と裏を撮影します。この操作を2周行うことで、最終的に10粒の生豆が写った画像を320枚用意します。生豆は白色に近いことから、撮影時は背景に黒色のボードを使用することで輪郭を判別しやすくします。

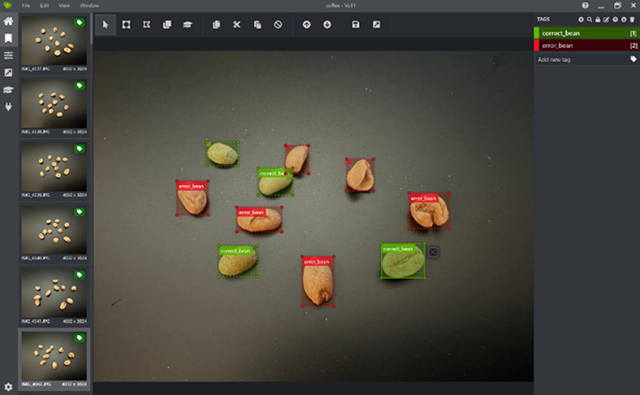
2. アノテーション
続いて、撮影した320枚に対してアノテーション作業を行います。アノテーションツールとして、Microsoft製のVoTTを使用し、10粒×320枚の合計3,200粒の判別を実施します。"欠け"や"虫食い"など、欠点豆になる要因は様々ありますが、今回は学習データ数が少なかったので、十分な学習は困難と考え、分類は単純に「正常豆」と「欠点豆」の2値とし、欠点豆内での種類分けは行いません。また、この後の学習で扱うモデルを想定し、Pascal VOC形式で結果を出力します。
| 分類 | 個数 | ラベル |
|---|---|---|
| 正常豆 | 1,600 | correct_bean |
| 欠点豆 | 1,600 | error_bean |
| 豆の状態 | 正常 | 異常 | |||||
|---|---|---|---|---|---|---|---|
| ラベル | correct_bean | error_bean | |||||
| 内訳 | 正常 | 欠け | 貝殻 | 生育異常 | 発酵 | 虫食い | ピーベリー |
実際に学習させてみる
1. 学習環境
Raspberry Piのようなマイコンで学習まで行うことは困難なので、処理能力に富んだ高性能GPUなどを具備した環境で学習を行い、学習済みモデルをマイコンに移植する方法を取ります。
今回は学習環境として、Google社が提供するGoogle Colabolatoryを使用します。このサービスは、Pythonベースで対話形式の処理が可能な機械学習 / データ分析の環境で、機械学習に適した高性能GPU(Tesla K80)を含む計算リソースを最大12時間まで無料で利用可能となっています。また、GoogleDriveを経由したデータのInput / Outputが可能なため、サービス利用にあたって煩雑なデータのやり取りは必要ありません。
学習には、物体検出系の機械学習モデルであるYolov5(You only look once ver5)を使用します。今回、このモデルを選定した理由は2点あります。1点目は、Yoloモデルの推論処理が他のモデルと比較して高速であり、マイコンでのリアルタイム処理を想定した場合に適している点。2点目は、モデルの構築や自作データセットでの学習の手順が、多くの人によって検証されているため、データセット作成などの作業に時間を多く割くことができる点です。
2. 学習方法
初めに作成したデータセットを、学習に使用する訓練データ(training data)と、モデルの評価に使用する検証データ(validation data)に分割します。今回はそれぞれ269枚と45枚とし、残り6枚は学習後モデルに入力して結果を確認する画像とします。
学習の際の設定として、Yolov5学習モデルをmedium、バッチサイズは16、エポック数は300とし、オプティマイザーはSGDを使用します。次の画像は、Google Colabolatoryにおける学習準備の様子で、ページ上でコーディングとデータセットの配置をしたのち、3時間の学習を経て学習済みモデルと学習結果を表すグラフ群が出力される様子です。
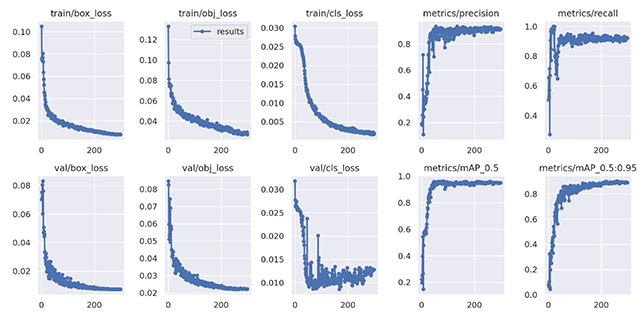
グラフからは、正解(矩形範囲や分類)からのズレを示すLoss(損失値)や学習モデルの精度を表すmAPが、学習を進めていくにつれてそれぞれ収束しているのが分かります。これらの評価指標の説明や学習グラフの考察については、説明が長くなってしまうため今回は省略します。
3. 学習結果
そして、学習済みモデルに対してデータセットから抜いていた画像を入力し、結果を見てみます。
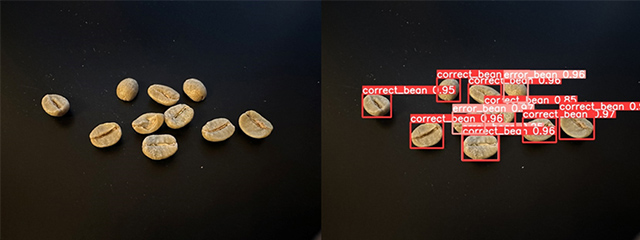
まず、識別結果の例として、正常豆と異常豆2枚の出力結果を示します。赤いラベルが付与されたものが正常豆(correct_bean)で、ピンクのラベルが付与されたものが異常豆(error_bean)です。また、ラベルの右側にある数値は、そのラベルの識別結果がどの程度正しいかを学習済みモデルが予測したものになります。

次に掲載する5枚の画像は、左が入力画像、右が出力画像です。出力画像には豆の範囲を示す矩形と、それが正常豆 / 異常豆どちらに属すかを示すラベルが表示されています。結果としては、正常豆と欠点豆が高い精度で分別できていることが確認できました。欠けた豆や発酵した豆を欠点豆として検出できているほか、4枚目では小さな虫食い穴も見分けて欠損豆と認識できています。




実際の分別機では、コーヒー豆がベルトコンベアを流れているような撮影条件を想定しています。この条件の検証のため、追加として豆を流し見する動画を撮影し連続画像に分割、学習済みモデルに入力して判別を行います。結果としては次のようになり、画面中央に位置する豆の分類精度は良いですが、画面の隅に写る豆については精度が低くなるような結果となっています。

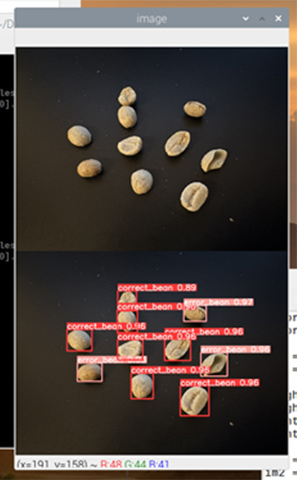
学習済みモデルをRaspberry Piに移植してみる
最後に、学習済みモデルをRaspberry Piに移植し、画像判別を行います。今回はRaspberry Pi上にYolov5の環境を構築し、静止画像を入力して判別が可能かを確認します。出力結果では、移植した学習済みモデルが正常に動作していることが分かります。
考察
今回の取り組みについて考察していきます。3点の改善ポイントがあったと考えています。
まず、撮影についてです。今回は撮影カメラとして利便性の面から、筆者自身の保有するiPhone14Proを利用していました。しかし、カメラによって画素数、ノイズ、色収差、歪曲収差などの特性に違いがあるため、使用するカメラは本番を想定した機器の使用が望ましく、マイコンに取り付けが可能なカメラを選定して撮影すべきでした。
また、撮影対象の豆の割合として正常豆:欠点豆を1:1としていましたが、実際の欠点豆混入率の10%で撮影を実施すべきでした。そのほかにも、撮影角度や背景素材などは、なるべく本番を想定して詳細に設定する必要があったと考えます。
続いて、アノテーションについてです。今回の正常豆と欠点豆の判別は筆者自身で実施しているため、プロレベルの判別はできていません。コーヒー豆を普段から見ている専門の方の観点もあるでしょうし、学習用データが最も重要であるため、アノテーションを実施する人自身の豆を見るスキルも高くあるべきです。
最後に、学習とモデル移植についてです。学習については、リアルタイム処理を考え低画質高精度のモデル作成を目指す必要があると考えます。そのためには、学習用画像の解像度を下げる、ノイズを入れるなどの処理をし、厳しい条件での学習も効果が期待できます。また、マイコンとしてRaspberry Piではなく、機械学習に特化したJetsonの方が今回想定する使用条件に適しているといえます。
とはいえこの取り組みを通して、大がかりなシステム構築を要するイメージのある深層学習が、近年はなるべくお金をかけずとも、やりたいことを実現できる環境が整っていることを実感しました。実際にかかった金額はRaspberry Piの調達に4万円程度で、コーディングおよび機械学習環境に対して費用は一切かかっていません。
まとめ
今回は、コーヒーの風味に影響を与える欠点豆の自動ピッキングの仕組みを考え、正常豆と欠点豆を仕分ける"目"の作成を目指しました。実環境ではマイコンによる判別が行われることを想定し、作成したデータセットを外部の処理リソースを用いて学習させ、Raspberry Piへの学習モデル移植を行いました。
"目"の構築については、Raspberry Pi上での画像の分類ができることを確認できましたが、リアルタイム処理を考慮したデータセット作成やマイコンの選定が必要であるほか、実際に生豆の仕分けを行う"手"となる機構の構築も必要となるため、おいしいコーヒーを飲むための道のりはまだまだ遠そうです。
-
※「Raspberry Pi」はRaspberry Pi Ltdの商標です。
-
※Microsoftは、米国 Microsoft Corporation およびその関連会社の商標です。
-
※iPhoneの商標は、アイホン株式会社のライセンスに基づき使用されています。
技業LOG
NTTPCのサービスについても、ぜひご覧ください