



Cassandraの概要
Cassandraは2007年 Facebook社のエンジニアによって開発されました。
その後Apache Software Foundation のプロジェクトとなり、成長を続け2017年2月にバージョン3.10がリリースされました。
NoSQLというと、少し取りつきにくいイメージもありますが、Cassandraは テーブルにデータを格納しCQLというSQLのようなクエリ言語を利用してデータのやりとりをすることができるため、直観的にはリレーショナルDBを使っているかのように操作ができます。
Cassandraは、複数台でクラスターを組んで分散DBを作成し、スケールアウトすることが容易にできる構造になっています。また処理性能も構成するノード数に比例します。
そのためサーバー管理者としては、比較的安価にスケーラビリティを確保できます。
性能処理のベンチマークについては次のサイトに掲載されているので参照してください。
- 参照:
ここからは主な特長毎に紹介します。
(1) 分散システム
Cassandraは、Amazon DynamoDB の技術を受けた造りでネットワーク分断性と可用性に強い構成に焦点をあてており、システムとして処理能力が足りなくなるとサーバー台数を追加させてスケールアウトしやすい構造になっています。そのため複数あるサーバーのそれぞれを起動するだけで自動的にクラスターを組むことができるようにCassandraでは次のような仕組みを取り入れています。 [※4, ※5, ※6]
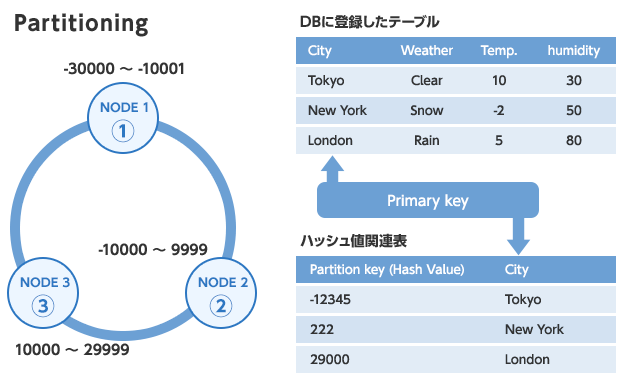
■Partitioning
データをクラスター内で各ノードに分散配布する仕組みです。
Consistent Hashingによりクラスター内の各ノードにトークンを配布しそのトークンに紐づくデータを各ノードに分散して収納しますまたレプリケーションで作成したデータも異なるノードに自動配置します。
■Gossip Protocol
クラスター内の各ノード間の通信プロトコルです。
クラスター内のノード間の通信は基本的にはP2P通信です。
このP2P通信をする際にGossip Protocolを使い各ノードは、他のノードと読み書きする情報の交換や各ノードの状態等の情報を取得し判断します
これらの仕組みによりCassandraでクラスターを組むためには、同じクラスター名とseed_node*のIPアドレスを設定ファイル(cassandra.yaml)に書き込んでCassandraを起動するだけで自動的にクラスターが組まれます。
- *seed_node:
Cassandraの起動後など該当のクラスターにスムーズに取り込まれてP2Pで通信を始めるために最初に接続するクラスター内の代表サーバー
(2) データ保存
Cassandraでのデータ保存は、主にmemtableというメモリー上の空間とSSTableというディスク上の領域を利用します。
データの書き込み時は、最初にmemtableに書き込みますが、ここが一杯になった時はmemtableの全ての内容をSSTableへ書き込みます。
読み出し時は、まずmemtableを参照し、ここにない場合はSSTableから該当データを取り出します。
Cassandraでのデータ削除時は、実際には削除はされずtombstoneという印がつきます。
一定期間経過後にcompactionというSSTableをまとめて整理する作業を行う時に削除されます。
(3) クラスター内でのデータ整合性
クラスター内でのデータ読み書きと各ノードが保持するデータの整合性についてです。
Cassandraでは外部システムからクラスターで保持しているDBへの読み書きの問い合わせのある場合は問い合わせを受け取ったノードがcoordinatorという役割を負い、クラスター内の該当するノードへデータの読み書きの問い合わせを行います。
この時 Consistency Level に基づいてどのノードへ接続するのか動きが変わります。
詳細な設定値等は次のサイトに記述があるのでご参照ください。
- 参照:
動作の違いについて大まかに比較すると、Consistency Levelが「ONE」なっている時は、coordinatorになったノードから直近一つのノードにのみ接続がありますが「ALL」に設定されている時は、関連するすべてのノードへ接続し該当の処理が終わるまでDBシステムとしての処理は終わりません。
Cassandraは、クラスター内で各サーバーの保持するデータの整合性が一時的に一致せずともそのうち整合性がとれれば良いEventual Consistencyという概念で出来上がっています。
リレーショナルDBでは、整合性の完全一致が必須ですが、Cassandraでは、Tunable Consistency という考え方でConsistency Levelを調整することにより変更もほぼない大量のデータを解析で処理する時などはConsistency Levelを下げることで処理能力を上げたりデータの最新性が必要な場合はConsistency Levelを上げるなど柔軟に設定することができます。
(4) 冗長性
Cassandraは、クラスター内の全てのノードが同等の役割を持ち自律して動作します。
さらに同じデータが同一のノードに重なることなくデータのレプリケーションが行われるため単一障害点(SPOF)もなく継続して運用することができます。
障害から復帰した場合も、障害中に他のサーバーで更新情報として受け取った内容はHinted Handoffの機構によって受け取ったサーバーで一時的に保存し、障害をおこしたサーバーが復旧後に該当サーバーへその情報を流し込み最新情報にアップデートします。
またRead Repairの機構で読み取り時に他のノードと比較して古い情報の場合アップデートを行う機構がついており各サーバー内でのデータの状態をできる限り最新に保ちます。
他にnodetoolなどの管理ツールを用いて手動で他のサーバーとの誤差を修正することやバックアップの管理をすることができます。
(5) データ構造
Cassandraのデータベース内で保持するデータは、key-value store型(KVS)のテーブル(table)に登録する形式でデータの位置を行と列で指定して操作できます。
テーブルは複数作れますが、テーブル間のリレーションはありません。
複数作成したテーブルは、キースペース(keyspace)という単位でまとめます。
NoSQLのデータベースでは、最初にデータのテーブル等の構成情報を定義するschemaを作る必要がないものが一般的ですがCassandraはデータの投入前に最初にテーブルとキースペースの定義をschemaとして作成する必要があります。
そしてそれらの操作は、CQLといわれるSQLに似たつくりのクエリ言語で操作できます。
詳細部分ではデータモデルがリレーショナルDBと違う部分があるため完全にSQLと同じというわけにはいきませんが"select"や"insert" 等のコマンドでデータ操作できるためリレーショナルDBを知っていると違いや利用について想像がつきやすいと思います。
Cassandraのインストール
Cassandraについて動作の概要がわかったところでCassandraのインストールです。
今回は、圧縮ファイルからインストールをして簡易なデータを投入するところまで実施します。
起動を目的にしているためログファイルやデータベースのデータなどもすべて圧縮ファイルを解凍したディレクトリ内にファイルが収まります。
サーバー構成を次の通り作成します
Cassandraのサーバー 3台 (CentOS 7)
ホスト名: cassandra1, cassandra2, cassandra3
(1) Cassandra インストールとクラスター作成
①インストールパッケージ取得
次よりCassandraパッケージを各サーバーでダウンロードします
http://archive.apache.org/dist/cassandra/3.10/apache-cassandra-3.10-bin.tar.gz
②tarを解凍して以下におきます
移動先ディレクトリ
/usr/local/
- ※解凍したディレクトリ名が長いので短い名前でシンボリックリンクを張ります
[root@cassandra2 ~]# ln -s /usr/local/apache-cassandra-3.10 /usr/local/cassandra [root@cassandra2 ~]# [root@cassandra2 ~]# ls -ld /usr/local/*cassandra* drwxr-xr-x 10 root root 4096 Feb 6 15:50 /usr/local/apache-cassandra-3.10 lrwxrwxrwx 1 root root 32 Feb 6 15:56 /usr/local/cassandra -> /usr/local/apache-cassandra-3.10 [root@cassandra2 ~]#
これで /var/usr/local/cassandra と指定することでCassandraのディレクトリにアクセスできます。
③Javaのインストール
次のコマンドで Java をインストールします。
# yum install java
④設定ファイル (cassandra.yaml) の編集
/usr/local/cassandra/conf/cassandra.yaml について各サーバにおいて以下を変更します。
変更前) - seeds: "127.0.0.1" 変更後) ①ホスト名が cassandra1の場合: - seeds: "<cassandra1のIPアドレス>" ②ホスト名が cassandra1以外の場合: - seeds: "<cassandra1のIPアドレス>,<自ホストのIPアドレス>"
変更前) listen_address: localhost 変更後) listen_address: <自ホストのIPアドレス>
変更前) rpc_address: localhost 変更後) rpc_address: <自ホストのIPアドレス>
⑤Cassandra 起動スクリプトの作成
- ※起動がスムーズになるように起動スクリプトを作ります。
[root@cassandra2 ~]# cat /etc/init.d/cassandra
#!/bin/sh
case "$1" in
start)
/usr/local/cassandra/bin/cassandra -R -p /var/run/cassandra.pid > /dev/null 2>&1
echo "Start Cassandra"
;;
stop)
kill `cat /var/run/cassandra.pid`
echo "Stopped Cassandra"
;;
*)
echo "Usage: $0 {start|stop}"
exit 1
esac
exit 0
[root@cassandra2 ~]#
⑥Cassandra 起動
各サーバーでCassandraを起動します
[root@cassandra2 init.d]# /etc/init.d/cassandra start Start Cassandra [root@cassandra2 init.d]#
⑦起動状態の確認
全てのサーバーでCassandraを起動後、nodetoolを利用して次のように3台分について表示され、各行左端にある「Status」と「State」の項目が3台全てで 「UN」 となっているとクラスターの完成です。
[root@cassandra3 conf]# /usr/local/cassandra/bin/nodetool status Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 172.16.0.106 69.9 KiB 256 69.9% 7fb097a8-d959-4c6e-a8da-69487d422f94 rack1 UN 172.16.0.107 87.4 KiB 256 70.5% 5a72bfe8-16f9-46da-be75-98d42c17c439 rack1 UN 172.16.0.108 106.41 KiB 256 59.6% 16c3feb9-597b-4957-9917-1c61048c7223 rack1 [root@cassandra3 conf]#
(2)データの投入
今回は(表1)ように気象情報という仮定でデータを作ってみました
(※データは、DB投入デモ用に架空の設定で作成されています)
(表1)
| 都市 | 湿度 % | 気温 ℃ | 風向 | 風速 m/s |
| 札幌 | 55 | 2 | 北西 | 1 |
| 東京 | 27 | 15 | 北 | 2 |
| 大阪 | 43 | 11 | 北東 | 3 |
| 福岡 | 28 | 11 | 南西 | 4 |
| 那覇 | 47 | 19 | 東 | 5 |
(表1) にあるデータを次の手順で投入します。
- ①schemaの作成
- ②データ投入
- ③内容確認
①schemaの作成
キースペースの作成ではreplicationの方法と数を指定できますが、今回は「SimpleStrategy」 で3つにしました。
テーブルの作成は、(表1)の各項目名を英語に変換しました。
(都市⇒city, 湿度⇒humidity, 気温⇒temperature, 風向⇒wind_direction, 風速⇒wind_speed)
そして「city」をprimary key に指定して作成しました。
[root@cassandra1 bin]# ./cqlsh 172.16.0.106
Connected to Test Cluster at 172.16.0.106:9042.
[cqlsh 5.0.1 | Cassandra 3.10 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cqlsh>
cqlsh> CREATE KEYSPACE testdata WITH REPLICATION = {'class' : 'SimpleStrategy', 'replication_factor': 3};
cqlsh>
cqlsh> CREATE TABLE testdata.weather (city text PRIMARY KEY, temperature int, humidity int, wind_speed int, wind_direction text);
cqlsh>
②データを投入
(表1) のデータをそれぞれ INSERT 文で投入します。
cqlsh> INSERT INTO testdata.weather (city, humidity, temperature, wind_direction, wind_speed) VALUES ('札幌', 55, 2, '北西', 1);
cqlsh> INSERT INTO testdata.weather (city, humidity, temperature, wind_direction, wind_speed) VALUES ('東京', 27, 15, '北', 2);
cqlsh> INSERT INTO testdata.weather (city, humidity, temperature, wind_direction, wind_speed) VALUES ('大阪', 43, 11, '北東', 3);
cqlsh> INSERT INTO testdata.weather (city, humidity, temperature, wind_direction, wind_speed) VALUES ('福岡', 28, 11, '南西', 4);
cqlsh> INSERT INTO testdata.weather (city, humidity, temperature, wind_direction, wind_speed) VALUES ('那覇', 47, 19, '東', 5);
③内容確認
②での登録結果を SELECT文で確認します
cqlsh> SELECT * from testdata.weather; city | humidity | temperature | wind_direction | wind_speed ------+----------+-------------+----------------+------------ 那覇 | 47 | 19 | 東 | 5 大阪 | 43 | 11 | 北東 | 3 東京 | 27 | 15 | 北 | 2 札幌 | 55 | 2 | 北西 | 1 福岡 | 28 | 11 | 南西 | 4 (5 rows) cqlsh>
まとめ
Cassandraについて概要と簡易的なインストールについて紹介しました。
Cassandraは、スケールアウトと可用性に重点を置いた分散システムとしてつくられているため容易に強力なDBシステムをつくることができます。
一方、インストールや運用についてはそれほど特殊な操作はありませんが、リレーショナルDBに比べるとデータモデル等ついて深い部分で違いがあったり、データの整合性についてはConsistency Levelの調整をしたりなどする必要があるため導入には十分な検討が必要です。また商用展開においては、サーバーの物理ディスクの分散や各サーバーへの接続するネットワークの可用性等も考慮する必要があります。
クラスターを組む場合、Cassandraを入れるサーバーが複数必要となります。特に検証等では、サーバーを確保することは難しいことが多いですが、仮想化されたシステムを利用すると便利になります。
今回は圧縮ファイルを利用したインストールでしたが、Dockerでもイメージを提供しているため簡単に同一ホスト内でクラスターを組むことができます。 [※7]
またWebARENAのVPSクラウドなどでは、プライベートセグメントのネットワークで複数のVPSをグループ化して運用することができたりVPSのクローンを作る機能もあったりするため今回紹介しました圧縮ファイルでのインストールにおいても比較的容易にスケールアウトを行う検証を行うことができます。これらの仮想化機能を使うことでサーバー運用における生産性向上にも大きく貢献してくれると思います。
参考資料
- ※1 Cassandra Summit 2016
http://www.datastax.com/company/events/cassandra-summit-2016-recorded-sessions-and-slides
Netflix Recommendations Using Spark + Cassandra
(Prasanna Padmanabhan & Roopa Tangirala, Netflix)
ビデオ:http://www.youtube.com/watch?v=SxU0CJJ2nVE;autoplay=1;rel=0
資料:http://www.slideshare.net/DataStax/netflix-recommendations-using-spark-cassandra - ※2 Cassandra Summit 2014 Japan 資料
Cassandra導入事例と現場視点での苦労したポイント
http://www.slideshare.net/haketa/cassandra-cassandra-summit2014jpn - ※3 DB-engines.com ランキング
http://db-engines.com/en/ranking - ※4 Cassandra Wiki Architecture Overview
https://wiki.apache.org/cassandra/ArchitectureOverview - ※5 Amazon's Dynamo
http://www.allthingsdistributed.com/2007/10/amazons_dynamo.html - ※6 Cassandra - A Decentralized Structured Storage System
https://www.cs.cornell.edu/projects/ladis2009/papers/lakshman-ladis2009.pdf - ※7 docker hub cassandra
https://hub.docker.com/_/cassandra/
技業LOG