




インタビュー
人工知能による「ニューラル機械翻訳」は
パラダイムシフトを起こせるか?
GPUの演算アーキテクチャを採用した
機械翻訳技術の未来像。
一般財団法人 日本特許情報機構 ( 以下、Japio ) は特許情報の専門機関として、全世界を対象に特許・商標分野の調査、申請、出願等の情報サービスを提供している。より高精度な翻訳技術を追及するため、人工知能に特化した「知財AI研究センター」を設立し、GPUの演算アーキテクチャを使用した「ニューラル機械翻訳」の研究開発を推進している。ニューラル機械翻訳はパラダイムシフトをおこすと言われているが、そう現実は簡単ではないようだ。従来技術の「統計翻訳」と新技術の「ニューラル機械翻訳」。この両者をいかに使い分け、いかに翻訳精度を高めるか…。機械翻訳の最前線に立つJapioに話を伺った。

一般財団法人 日本特許情報機構
営業推進部長
髙橋 氏

一般財団法人 日本特許情報機構
特許情報研究所
知財AI研究センター 主幹
大塩 氏
「機械翻訳」を活用して各国公報の日本語検索を実現
Japioの沿革や事業内容をご紹介ください。

髙橋 1970年に特許法が改正されて、日本においても諸外国と同様に公開制度が取り入れられました[*1]。そのため審査が終わって権利が確定した特許公報だけではなく、年間数十万件にもおよぶ出願を公開公報として情報提供する必要が生じました。その役割を担う専門機関として1971年に設立されたのが、前身となる財団法人 日本特許情報センター ( 以下、Japatic ) です。その後1985年に、社団法人 発明協会 ( 現・一般社団法人 発明推進協会 ) の特許情報サービス部門とJapaticとの統合によってJapioが誕生し、国内初の特許情報オンライン検索システム「PATOLIS」などのサービスを提供してきました。
「PATOLIS」は2001年に民間へと譲渡されましたが、公知例調査などを目的に各国の特許を参照したいというニーズは根強く、そこで立ち上げたのが現在の民間向け事業の中心となっている「Japio 世界特許情報全文検索サービス」です。米国、EPC ( 欧州特許条約 ) 加盟国、PCT ( 国際特許制度 ) 加盟国、中国、韓国などおよそ100ヶ国の特許情報を日本語や英語で横断的に検索できるサービスを、企業や特許事務所に提供しています。
海外特許の日本語検索はどのように実現しているのですか?
髙橋 外国語の公報はそのままでは日本語での検索ができません。そこで、まずは各国の公報類を集め、「機械翻訳」を行って日本語化し、独自のデータベースに蓄積および検索する仕組みを構築しています。
当初、英日および日英の機械翻訳には、文章を文法的に解析したのち語順を変換する「ルールベース翻訳 ( RBMT:Rule Base Machine Translation ) 」を用いており、技術用語の訳出が正確となるよう、延べ500万語以上を収録した36分野の専門辞書をJapioにて独自に構築しておりました。
技術用語辞書を準備できていない他の言語については、原文と翻訳文のペアである「対訳コーパス」を大量に学習させて統計モデルを作成し、そのモデルに従って翻訳を行う「統計翻訳 ( SMT:Statistical Machine Translation ) 」という技術を用いています。最近では、英日翻訳もRBMTより未知語が少ないSMT方式に移行しています。
[*1] 旧法においては特許出願とともに審査が行われていたが、1970年の法改正 ( 1971年施行 ) で、出願から1年6か月後
に出願内容を公開する「出願公開制度」と、出願人からの請求に応じて審査を行う「審査請求制度」が導入された。
AI専任組織でニューラル機械翻訳の研究開発を推進

機械学習への取り組みについて教えてください。
髙橋 「Japio 世界特許情報全文検索サービス」の機能と質を継続的に高めていくには、精度の高い機械翻訳技術を常に追求していかなければなりません。その一環として、人工知能や深層学習の活用に取り組んでおり、最新の「ニューラル機械翻訳」 ( NMT:Neural Machine Translation ) を中心に技術検証を進めています。2018年2月1日には研究開発をさらに加速するための専任組織として「知財AI研究センター」を設立しました。
大塩 NMTはインターネットの翻訳サービスとしてすでに実用化が始まっていることからもわかるように、自然で読みやすい文章が生成されるという特長があり、機械翻訳のパラダイムをシフトさせるとも言われています。しかし一方では、技術用語の訳出に難があるなどの課題が知られており、高精度な特許翻訳に応用するにはさまざまな検証や改良が必要です。知財AI研究センターでは、GPUの演算アーキテクチャを使って、NMTとSMTの翻訳品質の違いやそれぞれの特性などの技術検証・評価を進めています。
統計翻訳とニューラル機械翻訳にはどのような違いがあるのでしょうか?
大塩 一般的な傾向としては、技術用語の訳出の正確さではSMTのほうが優れていますが、文章の流暢さではNMTのほうが優れています。ただしNMTには、文の一部が無視されてしまう訳抜けや、同じフレーズが繰り返される重複訳が発生するという問題が知られていて、正確性を保証するには原文との照らし合わせが必要です。また、NMTは特許公報に多い未知語 ( これまでに学習したことがなくベクトルが作られていない単語 ) が苦手です。
なるほど、用語の正確性と文章としての流暢さを両立するのが課題なのですね。
大塩 そのとおりです。ただし、目的によって何を課題とするかは異なります。「Japio 世界特許情報全文検索サービス」のようなワードベースでの検索サービスには、技術用語の正確性が高いSMTかRBMTのほうが現時点では適していると考えています。
一方で、他言語の出願書類を作成する特許事務所や翻訳会社にとっては、用語の見直しは必要でも訳文にはそれほど手を入れずに済むNMTのほうが扱いやすいといわれています。
Japioではニューラル機械翻訳に関してどのような研究活動を行っているのですか?
大塩 オープンソースで提供されているOpenNMT [ *2 ] などのNMT開発ツールを使いながら、学習させるコーパス数や扱う語彙数を変えたとき、あるいは、ニューラルネットワークの深さを変えたときに、それぞれ翻訳品質はどう変わるか、といった検証を行っています。得られた知見の一例を挙げると、NMTで滑らかな訳文を得るには少なくとも1000万から2000万程度のコーパスを学習させる必要があることがわかってきています。
また、大学や企業の研究者で組織されるアジア太平洋機械翻訳協会 ( AAMT:Asia-Pacific Association for Machine Translation ) [ *3 ] に委託して、NMTを含む機械翻訳精度の向上を目指した「AAMT/Japio特許翻訳研究会」 [ *4 ] を定期的に開催しています。
[*2] OpenNMT:http://opennmt.net/
[*3] アジア太平洋機械翻訳協会:http://www.aamt.info/japanese/
[*4] AAMT/Japio特許翻訳研究会:http://aamtjapio.com/
機械翻訳方式の比較・技術検証に適した、
高速・大容量のGPU基盤を構築
データ処理やシステムの観点で見たときに、SMTとNMTとではどのような違いがありますか?

大塩 SMTは生成される統計辞書 ( 確率付きの対訳辞書 ) のサイズが大きいという特徴があります。たとえば1億ペアのコーパスを与えた場合のデータサイズは100GBを超え、条件を変えた翻訳結果を比較するため世代別ファイルも保存しておかなければなりません。そのため、学習性能および翻訳性能を高めるには、ネットワークストレージではなくて大容量かつ高速なローカルストレージが不可欠になります。また、主メモリの使用量も大きく、256GB以上の容量を使用します。
一方のNMTは、ストレージも主メモリもSMTほどの容量は必要としませんが、その代わりニューラルネットワークの学習に時間がかかるため、数千~万コアレベルの高い並列度を備えたGPU環境が必須になります。
そこで、今回導入したGPUサーバー群は、SMTとNMTのそれぞれの検証に適するように、SSDとHDDとを組み合わせた30TB以上もの大容量ストレージを搭載するなど、当方の要件に合わせてNTTPCコミュニケーションズ ( 以下、NTTPC ) に設計・構築してもらいました。
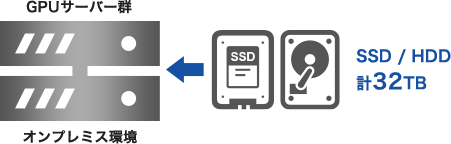
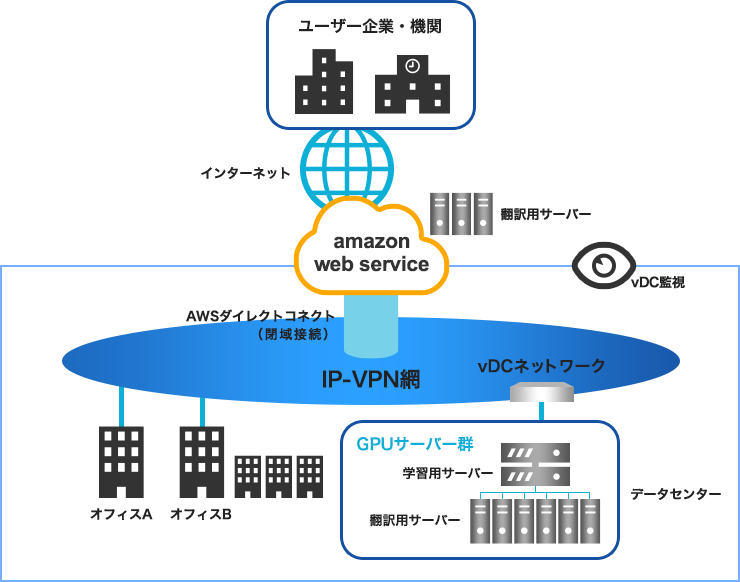
大塩 また、「学習用」サーバーと「翻訳用」サーバーは分けて構築しています。複数台の学習用サーバーは、それぞれが異なった学習モデルやアルゴリズムでパターン検証を行っており、一方の翻訳用サーバーは今後マルチノードにより並列分散処理する構成を考えています。これなら容易に、翻訳リソースの追加や適正配分が可能になります。大量翻訳をするためのGPUリソースが必要なときに必要な分だけ使えるAmazon Web Service ( 以下、AWS ) のGPUインスタンスも試験的に利用しており、オンプレミスとクラウドを組み合わせたいわばハイブリッド型の本格運用に対応できる検証環境を構築しています。AWSへの接続は、NTTPCが提供しているダイレクトコネクトを使用し、閉域接続を行っています。
GPU基盤を構築するにあたり、NTTPCを選定された理由を教えてください。
大塩 先ほども触れたような当方独自のシステム要件を満たすには、構成やスペックの自由度が少ない既成のGPUアプライアンスやクラウドサービスでは限界があります。そこで、当方の要件に適したGPUサーバーを設計/チューニングする必要があったのです。
NTTPCは学術系から一般産業まで幅広い実績があり、先に触れた内部ストレージ等のチューニングに加えて、GPUサーバーの消費電力に合わせたラック構成や計算スループットの高速化、その高いクロック数を維持しながらパフォーマンスを安定化させる排熱設計など、GPUの技術的知見に優れていました。
加えてNTTPCは、GPUサーバーを収容するデータセンターや広帯域ネットワーク、AWSとの閉域接続といった、当方のGPU基盤に必要な環境をすべて提供しているので、さまざまなベンダーに分散発注する手間なくスムーズに構築できるという点が大きな決め手になりました。
髙橋 結果的に、GPU基盤の設計~構築~運用保守まで「一気通貫」で頼め、大塩のチームが本来の研究業務に専念できたことがもっとも重要と考えています。厳しいスケジュールにも応えていただき、とても助かりました。
より精度の高い機械翻訳の実現を目指して

今後の取り組みについてお聞かせください。
大塩 NMTに関しては、技術用語の精度向上、学習の効率化、翻訳対象言語の拡大、翻訳速度の向上などいくつかの課題があり、今回導入したGPUサーバーを活用しながらユーザのニーズに合ったサービスが実現できるように、引き続き研究を進めていきます。具体的な実用化にはまだ至っていませんが、SMTとNMTのそれぞれの欠点を補完するような技術の確立がひとつの目標です。
髙橋 NMT等の技術を活用してユーザが検索しやすく読みやすい「Japio 世界特許情報全文検索サービス」の実現を目指していきます。また、Japioでは特許だけではなく商標も扱っていますので、ロゴやサービスマークなどの図形の検索にもニューラルネットワークなどの機械学習を活用していきたいと考えています。
本日はお忙しいところニューラル機械翻訳への取り組みとGPUの活用について教えてくださりありがとうございました。
最近の記事
技術解説

クラウド vs オンプレミス GPUサーバーの利用コストを徹底比較!
2020.03.17
ユーザーはどのような基準でクラウド、オンプレミスを選択すべきなのか・・・本コラムではコスト面におけるクラウドとオンプレミスの比較について紹介します!クラウドサービスに長年関わったスペシャリストが解説します!
イベントレポート

「InnovationLAB MeetUp #1」を開催しました!
~ 新たなビジネス開発に向けたコラボレーションを ~
2020.03.12
「InnovationLAB MeetUp #1」イベントレポート!AIサービス事業者・AI / IoT関連サービスの導入を検討されている企業さまや学術研究機関の方々などをお招きし、パートナーさまにさらなるアイディア創出やビジネスコラボレーションを促進させるために「InnovationLAB MeetUp #1」を開催しました。



