



Hopper アーキテクチャ

概要
Ampareモデルの後継となる次世代GPUアーキテクチャ「Hopper」ベースのNVIDIA H100 Tensor コア GPUは、大規模言語モデル (LLM)におけるパフォーマンスを前世代比30倍に高速化。現在飛躍的な発展を遂げる生成AI(ジェネレーティブAI)の活用領域においても、業界の一歩先を行く性能を発揮します。
H100 は80GB GPUメモリ、第4世代のTensorコアを搭載し、3,026 teraFLOPSのFP8 Tensor コア性能を誇ります。専用のTransformer Engineを利用することで、兆単位のパラメーターを持つ言語モデルを実装できます。
さらに、「H100 NVL」では、94GB HBM3 メモリ GPUを2基組み合わせ、合計188GBのメモリを搭載。メモリ帯域幅は計7.8TBpsとなり、大規模AIモデルに求められるメモリ容量/帯域の拡張を実現しています。
GPUとGPUを毎秒900Gbpsで相互接続する第4世代NVLink、ノード全体でGPU間の通信を加速する NVLINK Switch System、PCIe Gen5、NVIDIA Magnum IO™ ソフトウェアの組み合わせにより、エンタープライズ用途はもとより、大規模な統合 GPU クラスタに至るまで、幅広い拡張性を提供します。
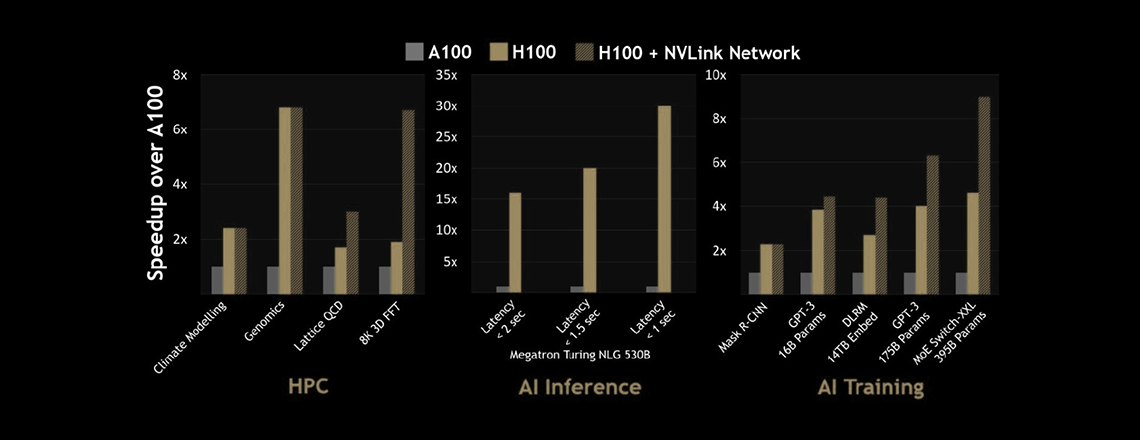
前モデル(A100)との性能比較
特長
大規模言語モデル(LLM)における最大のパフォーマンスを発揮
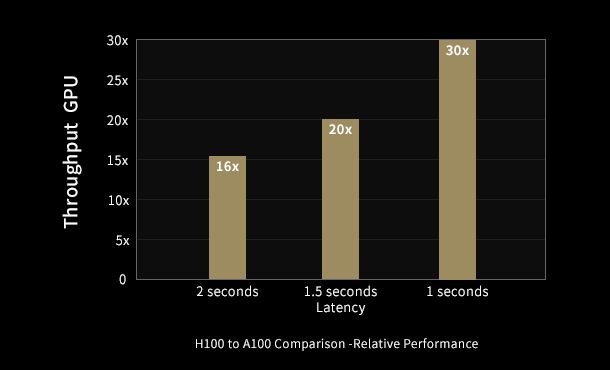
前世代のA100と比べて最大30倍の推論性能を発揮し、遅延を最小限に抑えています。
第4世代のTensorコアは、ムーアの法則を超えるパフォーマンス向上を継続的に提供し、多くのパラメーターを持つ大規模な言語モデルであっても、精度を維持しながらメモリ消費を削減して性能を向上します。
生成できるものは画像、動画、楽曲等、プログラムのコード、文章など多岐にわたり、クリエイティブな成果物を生み出せる点が特徴です。
FP8(8ビット浮動小数点演算)
前世代のA100ではFP16(16ビット浮動小数点演算)での処理を行っていましたが、H100では新たにFP8(8ビット浮動小数点演算)を採用することで、4000TFLOPSという非常に高い演算性能を実現しました。これはA100の処理性能の約6倍にのぼります。
また、FP16では2000TFLOPS、TF32で1000TFLOPS、FP64で60TFLOPSとなっており、いずれもA100の3倍のパフォーマンスを誇ります。

TRANSFORMER ENGINE
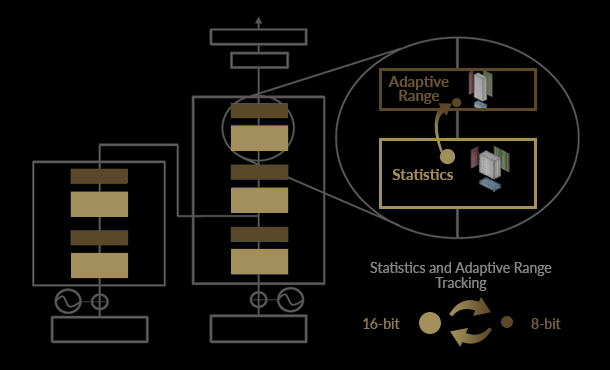
H100では、FP8 と FP16 の精度を混在させることができます。さらなる高速化・正確性を実現できるAIモデルにはFP8を適用し、それ以外はFP16を利用するといったように、それぞれのワークロードに適したものを使い分けることが可能です。
演算結果の統計情報を基に、GPUが自動的にFP8/FP16を使い分けるため、フレームワーク側が選択する必要はありません。
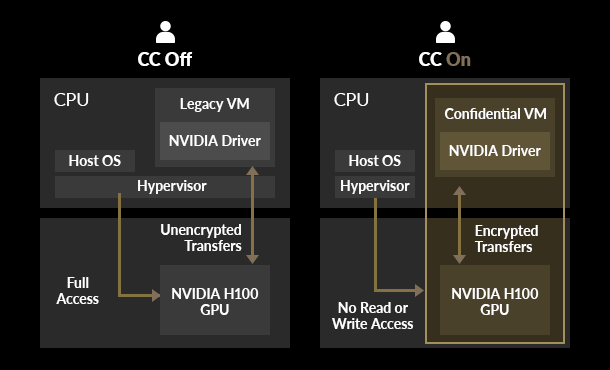
CONFIDENTIAL COMPUTING
世界で初めて、CPU と H100 GPU の間のデータ転送をPCIe ラインレートで暗号化し、GPUが使用中のデータ・ワークロードの機密性と完全性を守るセキュリティ機能を実装しました。
ホストOSやハイパーバイザーなど、許可しないユーザがデータを覗き見たり、ユーザの意図しない変更が加えられるリスクから保護します。
第2世代MIG(マルチインスタンスGPU)
A100で実装されたマルチインスタンス GPU (MIG) 機能では、1枚のGPUを最大7つのインスタンスに分離することができます。それぞれのインスタンスにメモリ・キャッシュ・GPUコアを割り当てられ、異なるユーザ・用途で利用することが可能です。
H100ではMIG機能をさらに強化。他のインスタンスの影響を受けることなく、よりセキュアにマルチテナント/マルチユーザー構成を利用できます。
DPX命令
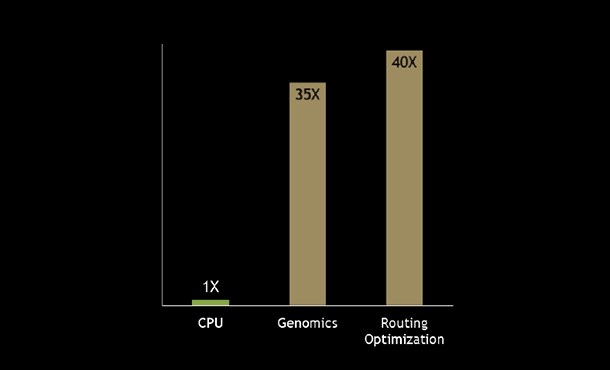
動的プログラミングは、複雑な再帰的問題を単純な小問題に分割して計算する手法です。他の手法に比べ、短時間で幾何級数的な難問を解決することができるため、最短な配送ルートの割り出し、病理診断などさまざまな産業で活用されています。
H100では、DPX 命令で動的プログラミングの計算速度をさらに向上します。 CPUと比較すると 40 倍、A100と比べても 7 倍の演算スピードを実現。
NVIDIA H200 Tensor Core GPU
HBM3e GPUメモリを初めて搭載したNVIDIA H200 GPUは、生成AIやLLM (大規模言語モデル)のトレーニングにおいて革新的なパフォーマンスを発揮します。
旧世代のNVIDIA H100 GPUと比べ、 LLM推論においては約2倍、HPC解析では110倍の性能向上を実現します。

NVIDIA H200 Tensor Core GPU
| 項目 | 仕様 |
| メモリ | ・141GB |
| メモリ帯域幅 | ・4.8TB/s |
| パフォーマンス | ・倍精度 (FP64):34TFLOPS ・単精度(FP32):67TFLOPS ・半精度(FP16 Tensor Core):1,979TFLOPS* ・TF32 Tensor Core:989TFLOPS* ・FP8 Tensor Core:3,958TFLOPS* |
| フォームファクター | ・SXM |
| マルチインスタンスGPU(MIG) | ・最大7つのMIGに分割可能 ※1インスタンスあたりのメモリ容量:16.5GB |
| インターコネクト | ・NVIDIA NVLink®:900GB/s ・PCIe Gen5: 128GB/s |
| 最大電力消費 | ・700W |
* 本数値は、スパース行列演算機能を適用した場合の理論上の最大性能を示しています。
実際のアプリケーションで取得したベンチマーク結果や、スパース方式等が異なる環境では数値が変動します。
NVIDIA GH200 Grace Hopper Superchip
NVIDIA Hopper™ベースの H100 GPUとArmベースのNVIDIA Grace™ 72コア CPUを、NVIDIA NVLink®-C2C インターコネクトテクノロジを用いて1基のコアに統合したモデル。8ペタFLOPSのAIパフォーマンスを誇り、生成AIやLLM (大規模言語モデル)のトレーニングにおいて革新的なパフォーマンスを発揮します。
従来の PCIe Gen5 レーンと比較して 7 倍広い最大 900 GB/秒の総帯域幅を実現。NVIDIA NVLink🄬システムに対応し、複数のGH200を高速・低遅延に接続することが可能です。

NVIDIA GH200 Grace Hopper Superchip
| カテゴリ | 項目 | 仕様 |
| CPU | 総CPUコア | ・72 Arm Neoverse V2 コア |
| L1キャッシュ | ・64KB i-cache + 64KB d-cache | |
| L2キャッシュ | ・1MB/コア | |
| L3キャッシュ | ・117MB | |
| メモリ | ・480GB | |
| メモリ帯域幅 | ・512GB/s | |
| PCIe接続 | ・PCIe Gen5 ×4レーン | |
| GPU | メモリ | ・HBM3 :96GB ・HBM3e:144GB |
| メモリ帯域幅 | ・HBM3 :4TB/s ・HBM3e:4.9TB/s |
|
| パフォーマンス | ・倍精度 (FP64) : 34TFLOPS ・単精度 (FP32) : 67TFLOPS ・半精度 (FP16 Tensor Core) : 1,979TFLOPS* | 990TFLOPS ・FP8 Tensor Core:3,958TFLOPS* | 1,979TFLOPS ・Bfloat16 Tensor Core : 1,979TFLOPS* | 990TFLOPS ・INT8 Tensor Core:3,958TOPS* | 1,979TOPS |
|
| 共通 | NVLink-C2C CPU-GPU接続帯域幅 |
・900GB/s |
| 最大電力消費 | ・450W~1,000W | |
| サーマルソリューション | ・空冷 / 水冷 |
* 本数値は、スパース行列演算機能を適用した場合の理論上の最大性能を示しています。
実際のアプリケーションで取得したベンチマーク結果や、スパース方式等が異なる環境では数値が変動します。
HGX H100
DGX H100のOEMモデル。Hopperアーキテクチャを採用した「NVIDIA H100 GPU」を4基または8基搭載可能な、SXM5/Gen5対応ラックマウント型GPUスーパーコンピューター。
NVLinkおよびNVSwitchによるGPUダイレクト通信で高速・高度な演算性能を発揮します。
NIC、メモリ容量、搭載CPU、ストレージなど、スペックは要件に合わせて任意にカスタマイズが可能です。

DGX H100 / HGX H100条件比較
| DGX H100 | HGX H100 | ||
|---|---|---|---|
| 価格 | 営業担当へお問い合わせください。 【適用可能な特価プログラム】 ・アカデミック ・NVIDIA Inception Parter |
見積シミュレーター | |
| サーバ仕様 | ユニットサイズ | 10U | 8U |
| 定格消費電力 | 11.3kVA | 10.3kVA (搭載構成により変動) | |
| NVSwitch | 対応 | 対応 | |
| NVLink | 対応 | 対応 | |
| 構成- GPU/CPU/メモリ/ディスク/NIC等 |
アプライアンス (変更不可) | カスタマイズ可 | |
| 保守/サポート | ・3-5年オンサイト保守(※) ・NVIDIAテクニカルサポート ※GPU/CPUのみ。他パーツはクロスシップ |
・1-5年オンサイト保守 or センドバック保守(※) ・SUpermicroテクニカルサポート ※保守年数、保守レベルは選択可能 |
|
| ソフトウェア | NVIDIA AI Enterprise | ◎ | 有償オプション |
| NVIDIA Base Command | ◎ | × | |
| NVIDIA Bright Cluster Manager | ◎ | 有償オプション | |
| OS | Ubuntu Linux OS | 自由選択可 |