AI開発の現場では、クラウドの継続課金とオンプレミスの構築負荷という二択に悩まされてきました。NVIDIA DGX Sparkは、2,000億パラメータのAIモデルを「手元のデスク」で動かすという第三の選択肢を提示します。省電力・ミニサイズのパーソナルコンピューターでありながら、生成AI/LLM推論環境として高い性能を発揮します。本記事では、従来のAI環境が抱える課題を整理し、DGX Sparkがどのように解決するのか、そして導入時に考慮すべきポイントを体系的に解説します。
なお、NVIDIAエリートパートナーであるNTTPCではDGX Sparkの販売・検証を行っています。導入をご検討の方は、お気軽にご相談ください。
DGX Sparkとは何か ― 手元で動くハイエンドコンピューティング
DGX Sparkは、NVIDIAが2025年春のGTCで発表した、次世代の高性能コンピューティングシステムで、Grace Blackwell Superchipを搭載し、AIの設計・学習・推論をすべてローカルで完結できる「デスクに置けるスーパーコンピューター」と位置づけられています。
これまでのAI開発はクラウドやデータセンターに依存し、コストやリソースの制約がボトルネックとなる場合がありました。DGX Sparkは、そうした制約を超え、個人や小規模チームでもフルGPU環境でAIを自由に試せることを目的に設計されています。
また、本製品は必要に応じてスケールできる計算基盤です。PoCやモデル検証をローカルで迅速に実行し、必要に応じて2台を接続して拡張することができます。
なぜDGX Sparkが必要なのか ― 従来のAI開発環境が抱える課題
AI開発の現場では、GPUリソースの確保や運用コスト、環境構築の複雑さなど、現実的な制約がアイデアを形にするスピードを左右します。クラウド、オンプレミス、ワークステーションはそれぞれに利点がありますが、開発フェーズ全体を俯瞰すると、共通する課題も少なくありません。ここでは、DGX Sparkのようなソリューションが求められる背景として、開発者や研究者が直面しうる代表的な課題を整理します。
【ハードウェアの課題】性能限界と導入コストの壁
オンプレミス環境でAI開発を行う場合、GPUリソースの確保と運用には専門的な知見が求められます。GPUカードの増設に伴う冷却や電力供給の設計、ファームウェアの管理といった要素が複雑に絡み合い、IT部門の負荷が増大する傾向がみられます。
また、AIモデルの大規模化に伴い、既存のワークステーションでは性能が追いつかないという場面も増えつつあります。高性能なGPUサーバーを導入するには高額な初期投資と、継続的な保守・運用コストが必要となり、特に小規模チームや研究機関にとっては大きなハードルとなっています。
【クラウドの課題】コスト課金と柔軟性のジレンマ
GPUクラウドは初期投資を抑え、必要な時にリソースを確保できるという大きな利点があります。しかしその一方で、継続的な利用や試行錯誤を前提とした開発においては、時間課金モデルがコスト面の負担となるケースも少なくありません。また、GPUインスタンスの確保状況、利用規約の変更、あるいはリージョン間のデータ転送コストなど、組織運用上のリスクを考慮する必要が生じることもあります。
特に、生成AIモデルやRAGシステムの検証をクラウド環境で繰り返し行う際に、「コストを気にせず、もう少し試行錯誤したい」というニーズと現実の運用との間で、バランスを取る必要に迫られることがあります。
関連事例:GPUサーバーオンプレミス導入で加速するクリエイティブ×機械学習の創作支援機能研究|ペイントアプリ「CLIP STUDIO PAINT」を手がけるセルシスの挑戦|AIとDXの新しいミカタ。
【データ管理の課題】セキュリティとコンプライアンスの制約
医療・金融・製造業などの分野では、機密データを外部クラウドに転送することへの懸念や、厳格なデータガバナンス・法規制への対応が求められます。患者情報、金融取引データ、製造ノウハウといった機密性の高い情報を用いたAI開発では、データの保管場所や管理方法に関する厳格な制約が課されることが一般的です。
また、AI開発のプロセスでは、目的やフェーズに応じて複数の環境を使い分けることが一般的です。例えば、「クラウドで学習し、オンプレで検証、ローカルで推論する」といったケースでは、環境ごとにライブラリやドライバのバージョンが異なり、開発の再現性を担保することが難しくなるという問題が発生することがあります。
環境間のデータ転送やアクセス権の設定といった付帯作業も、開発サイクルを長期化させる一因となり得ます。結果として、開発スピードを上げたいチームほど、セキュリティ要件への対応と環境の差異を吸収するための管理業務に時間を費やしてしまうという、非効率な構造に陥る可能性も指摘されています。
関連事例:【GPU×研究】生命科学研究を加速させるGPUコンピューティング ~NVIDIA H100 NVL搭載サーバーの導入で、大規模なゲノム解析や分子シミュレーションを後押し~|AIとDXの新しいミカタ。
これらの課題は、特にAI開発の初期段階において「アイデアをすぐに試す」ことを難しくしており、DGX Sparkはこうしたボトルネックを解消するための一つの方向性を示しています。

DGX Sparkによる解決策 ― 手元で完結するAI開発
前章で整理したように、従来のAI開発はクラウド、オンプレ、ローカルの間で分断され、コストやスピードの面で多くの制約を抱えていました。DGX Sparkは、AIの企画・実験・検証・推論のすべてを「1台のデスクトップ」で完結させることで、その構造的な課題に対応します。
課題と解決策の対応表
| 課題カテゴリ | 具体的な課題 | DGX Sparkによる解決策 |
| ハードウェア | 高額な初期投資と運用コスト | 1台から始められる低コストなスモールスタートと長期的なコスト効率の向上 |
| 専門知識が必要な構築・管理 | コンパクトな構築済みで環境で即座に実行可能 | |
| 性能限界による拡張性の制約 | 複数台接続による段階的な拡張 | |
| クラウド | 継続利用での課金負担 | ローカルで課金を気にせず開発 |
| 通信遅延への懸念 | ローカルで低レイテンシを実現 | |
| インスタンス確保の不確実性 | 専用GPUで安定したリソース確保とカスタマイズ | |
| データ管理 | 機密データのクラウド転送への懸念 | 機密データをローカルで保護 |
| 環境差異による再現性の低下 | シームレスなクラウド移行 |
【ハードウェアの課題】導入コストを抑えた柔軟なAI基盤
DGX Sparkは、「1台から始められるAIインフラ」というコンセプトを実現します。筐体は非常にコンパクトで、一般的なオフィスやラボにも設置可能です。高額な初期投資を抑えながらも、AI開発環境をすぐに整備することが可能です。
クラウドの継続的な時間課金と比較すると、長期的なコスト効率にも優れており、継続的にAI開発を行う組織では、運用コストの予測性向上や総所有コスト(TCO)の削減が期待できます。GPUとCPUを同一ユニットに統合したGrace Blackwell Superchipを搭載しており、データ転送のボトルネックを最小化しています。高負荷なAI処理を手元で実行できるため、専門的なインフラ構築の負荷を大幅に軽減します。
さらに、複数台をネットワーク接続することでクラスタ構成を組むことも可能です。これにより、スモールスタートからスケールアップへと段階的に導入できます。
・1台でRAG構築・モデル推論の検証
・2台を接続して大規模モデル(例:Llama 3.1 405Bなど)の分散推論
・研究・教育環境でのハンズオン利用
上記のように、組織規模や目的に応じた柔軟な展開が可能です。
【クラウドの課題】コスト効率的な開発とスケーラビリティ
DGX Sparkは、モデルの学習やファインチューニング、推論をローカルで行えるため、クラウドの課金を気にすることなく、迅速な試行錯誤が可能になります。
また、ローカルでデータ処理を完結させることで、クラウドとの通信遅延を排除し、低レイテンシなAI処理を実現します。リアルタイム性が求められる推論や、大容量データの反復的な処理においても、ストレスなく開発を進められます。
さらに、専有GPUを持つことで、クラウドで問題になりがちなインスタンス確保の不確実性から解放されます。開発専用GPUサーバーを手元に置いておくことで、必要なタイミングでいつでもリソースを利用でき、NVIDIA AI AI EnterpriseやNVIDIA NIM™など、主要なAIソフトウェアスタックも活用できます。
日常的な実験や推論検証はDGX Sparkでローカル実行し、大規模モデルの学習や本番デプロイが必要になった場合はNVIDIA DGX B200などの大規模サーバーへ移行するといった柔軟な運用が可能です。
【データ管理の課題】ローカル完結とクラウド連携の両立
DGX Sparkは、機密データを外部クラウドに転送せず、ローカル環境で完結したAI開発を実現します。医療・金融・製造業などの厳格なデータガバナンスや法規制が求められる分野において、データ主権を確保しながら高度なAI開発が可能になります。患者情報、金融取引データ、製造ノウハウといった機密性の高いデータを、組織の管理下に置いたまま、最先端のAI技術を活用できます。
DGX Sparkの性能と機能 ― 開発を加速する技術仕様
DGX Sparkは、デスクトップサイズながらAIスーパーコンピューター並みの性能を発揮し、AI開発者、研究者、データサイエンティストのあらゆるワークロードに対応します。以降ではその性能と機能の特徴をご紹介します。
1. FP4精度で最大1ペタFLOPSのAI性能
NVIDIA GB10 Superchip(Grace Blackwell アーキテクチャ)を搭載し、FP4精度で最大1ペタFLOPSのAI処理能力を実現します。高速なモデル開発と推論により、開発サイクルを大幅に短縮できます。
2. 128GBの統合システムメモリ
大容量のコヒーレント統合システムメモリを搭載。GPUとCPUが統合されたメモリ空間により、データ転送のボトルネックを最小化し、効率的なAI処理を実現します。
3. 大規模モデルのローカル推論に対応
DGX Sparkは、2,000億パラメータのローカル推論と開発に対応しています。さらに、2台接続で最大4,050 億パラメータモデルの推論も可能です。これにより、DeepSeek、Meta Llama 3.1 405B、Google Gemmaなどの主要な大規模言語モデルを、クラウドに依存せず手元で実行できます。
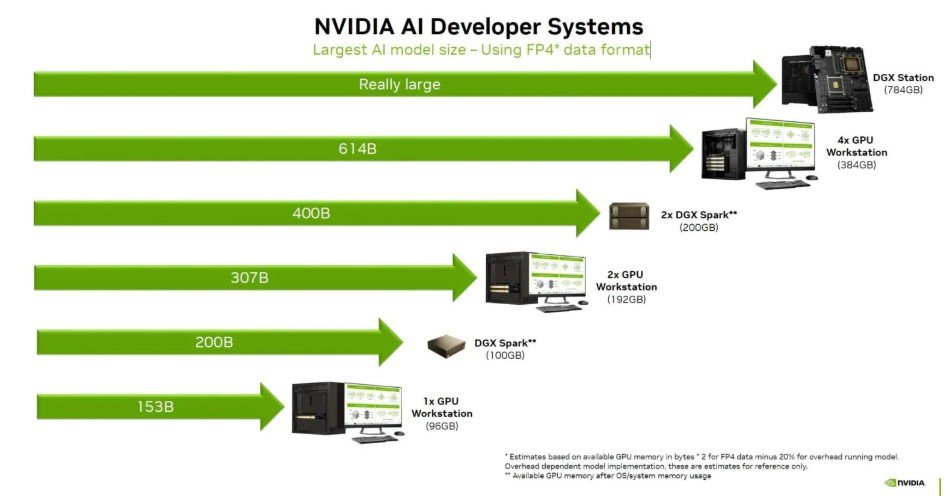
NVIDIA DGX Station/Workstation/Spark 構成における最大モデル規模比較(FP4精度)
4. あらゆるAIワークロードに対応
DGX Sparkは、研究開発から実運用まで、幅広いAIワークロードに対応できる柔軟性を備えています。単一の筐体で、モデル開発から推論、データ分析、エッジAIまでを一貫して実行可能です。
【AIワークロード例】
| プロトタイピング | AIモデルとアプリケーションの開発、テスト、検証を手元で迅速に実行できます。 |
| ファインチューニング | 最大700億個のパラメータのAIモデルをローカルでファインチューニング可能です。 |
| 推論 | 最大2,000億個のパラメータを持つAIモデル(DeepSeek、Meta Llama、Google Gemmaなど)でテスト、検証、推論を実行できます。 |
| データサイエンス | NVIDIA RAPIDSでエンドツーエンドのデータサイエンスワークフローを高速化します。 |
| エッジアプリケーション | IsaacやMetropolisなど、NVIDIAのAIフレームワークを使用したエッジアプリケーション開発が可能です。 |
もし、DGX Sparkを利用していてLLM推論の処理性能が物足りない場合や、DGX Sparkよりも高性能なプロ向けGPUの導入をご検討されているかたは、最新GPUの「NVIDIA RTX PRO 6000 Blackwell」がおすすめです。
LLM推論では、メモリ帯域幅が影響するため、RTX PRO 6000の方がDGX Sparkよりも高速に処理できます。※(参考):RTX PRO 6000のメモリ帯域幅は1,792GB/sで、DGX Sparkの273GB/sの約6.5倍
「NVIDIA RTX PRO 6000 Blackwell」は、前世代のGPU「RTX 6000 Ada」や「L40S」から大幅に性能が向上しており、LLM推論や大規模データ処理、画像解析・3Dレンダリングなど幅広いワークロードにおいて、高いパフォーマンスを発揮します。
5. プリインストール済みAIソフトウェアスタック
NVIDIA Enterpriseを含む、ツール、フレームワーク、ライブラリ、トレーニング済みモデルを含むフルスタックソリューションがプリインストールされています。専門知識不要で、構築作業なしに即座に開発を開始できます。
6. 拡張可能なネットワーキング ― スモールスタートからエンタープライズまで
DGX Sparkは、1台から始めて段階的に拡張できる柔軟性を持っています。小規模な検証から始め、必要に応じて本格的なエンタープライズ環境へとスムーズに移行できます。
1台での活用: PoC、プロトタイピング、個人・小規模チームでの開発に最適。200Bパラメータモデルの推論と開発が可能です。
2台接続での拡張:NVIDIA ConnectX🄬-7ネットワーキングにより、2台のDGX Sparkシステムを接続可能。最大400Bパラメータを持つAIモデルを活用でき、より大規模な開発に対応します。
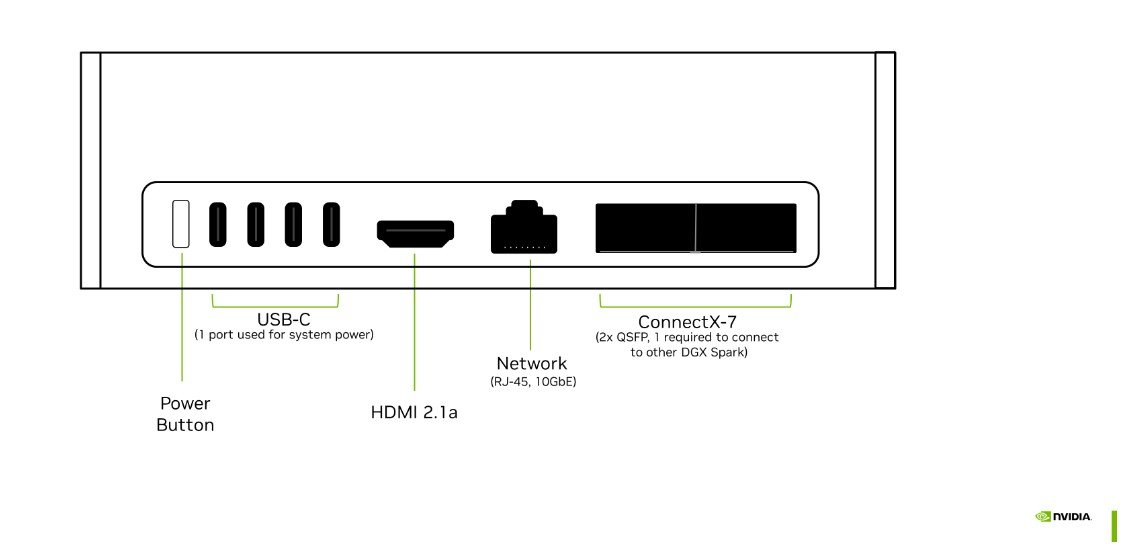
エンタープライズへの拡張: 検証が完了したワークロードは、DGX CloudやDGX Stationへシームレスに移行可能。同一のソフトウェアスタック(CUDA、TensorRT、NIM)により、コードの書き換えなしに本格運用へと展開できます。
このように、DGX Sparkは「小規模からエンタープライズまで」対応できる柔軟な選択肢を提供します。
OEMモデルの選択肢
2025年現在、NVIDIAのDGX SparkプラットフォームをベースにしたOEMモデルが各社から登場しており、代表的なものとしては、ASUSの「Ascent GX10」とDellの「Pro Max with GB10」が挙げられます。
ASUS Ascent GX10
省スペース性と冷却性能を両立したモデルです。デュアルファンによる効率的なエアフロー設計を採用し、長時間稼働でも安定したパフォーマンスを維持します。研究開発やPoCなど、手元で試行錯誤を重ねたい現場に適しています。

ASUS Ascent GX10詳細は下記よりご確認ください

Dell Pro Max with GB10
拡張性と運用性を重視した設計です。大容量ストレージ構成やオンサイト保守に対応しており、社内環境での継続的なAI開発や運用を想定しています。セキュリティや安定稼働を重視する企業利用に向いたモデルです。

Dell Pro Max with GB10の詳細は下記よりご確認ください
2つのモデルはいずれもNVIDIA GB10アーキテクチャの性能を最大限に活かしていますが、設計思想にはそれぞれ特徴があります。ASUSは冷却性能を重視した研究開発向け、Dellは保守性と拡張性を重視した業務利用向け、用途や運用環境に応じて、目的に最も適したモデルを選定することが重要です。
なお、これら2つのモデルはいずれもNTTPCコミュニケーションズにて販売しています。価格や仕様の詳細については、製品ページをご確認ください。
DGX Sparkの活用シナリオ
DGX Sparkは、その性能とローカル環境で完結する特性から、多様な業種での現場適用が期待されます。ここでは、想定される代表的な活用シナリオをいくつかご紹介します。
学術・研究機関:AI学習・実験のためのGPU環境
製造ラインでは、不良品の早期検出や設備の異常予兆の把握といった課題に取り組むケースがあります。DGX Sparkを活用することで、カメラ映像やセンサー情報を現場で即座に解析し、クラウド通信の遅延に左右されにくいリアルタイムな判断に繋げることが期待されます。 通信が不安定な環境下でも、オンプレミスで完結する安定したAI検査システムの構築に役立ちます。
製造業:AIによる品質検査・異常検知
大学や研究所では、生成AIや大規模モデルを扱う実験が増えていますが、クラウドの利用にはコストや承認プロセスといった制約が伴うことも少なくありません。
また、DGX Sparkはデスクトップサイズで高性能なGPUを搭載しているため、研究室単位でのAI実験基盤や、授業用途などへの柔軟な導入が見込まれます。学生や研究者にとって「手元で試せるAI環境」を提供するための一つの選択肢となります。
公共・自治体:防災・インフラ監視の現場AI
自治体やインフラ管理の分野では、防災や交通監視などで大量の映像・センサーデータを扱うことが想定されます。DGX Sparkを現場の近くに配置することにより、通信経路の負荷を抑えつつ、その場でデータを解析するといった運用が考えられます。
クラウドに依存しにくい閉域環境で、リアルタイム分析や異常検知を行うシステムへの応用が期待されます。
医療・創薬分野:安全なローカルAI解析
医療・創薬の現場では、患者データなどの機密性の高い情報を外部環境へ転送することが難しい場合があります。DGX Sparkは、ローカル環境でAIモデルの学習や推論を完結できるため、厳格なデータガバナンスを維持しながら研究開発を加速させる一助となる可能性があります。
画像診断AIの開発や、創薬シミュレーションの高速な検証といった用途での貢献が考えられます。
DGX Sparkの導入を検討する際の7つのポイント
DGX Sparkを導入する際は、性能やコストだけでなく、運用目的や将来の拡張性を踏まえた検討が欠かせません。ここでは、導入前に押さえておくべき主要なポイントを整理します。
【ポイント1】導入目的を明確にする ― PoCか本格運用か
AI研究、生成AIの試作、社内データ分析など、導入目的によって必要な構成や運用コストは大きく変わります。PoC段階であれば単体のDGX Sparkでも十分な性能を発揮しますが、本格的な学習環境を構築する場合は、DGX StationやDGX Cloudとの連携を見据えた設計が重要です。
まず「どの工程を手元で完結させたいのか」を明確にし、 GPU性能・メモリ容量・ネットワーク要件を整理しておくことが導入成功の第一歩となります。
【ポイント2】性能要件と拡張性の見極め
DGX Sparkは、コンパクトかつ高性能なAI開発環境として設計されていますが、その設計思想に伴ういくつかの技術的制約があります。導入前にこれらを理解しておくことで、適切な運用計画を立てることができます。
【ポイント3】メモリ容量は128GBで固定
DGX Sparkは128GBの統合メモリを搭載していますが、オンボード設計のためメモリの増設はできません。200Bパラメータまでの推論や70Bパラメータまでのファインチューニングには十分ですが、より大規模なモデルや複数モデルの同時実行を行う場合は、メモリ容量が制約となる可能性があります。
そのため、導入前に扱う予定のモデルサイズやメモリ使用量を見積もり、2台接続による分散処理で対応できるかを確認しておくことが重要です。
【ポイント4】GPU分割機能(MIG)は非対応
Multi-Instance GPU(MIG)機能には対応していないため、複数のユーザーやジョブでGPUリソースを細かく分割して利用することはできません。そのため、1台を複数チームで共有してリソース管理を行う用途よりも、専有での利用に適しています。
共有環境が必要な場合は、用途ごとに複数台を配置するか、ジョブスケジューリングツールでの運用を検討する必要があります。
【ポイント5】対応OSはLinux専用
DGX Sparkは、NVIDIA DGX OS(Linuxベース)専用のシステムです。Windowsには対応していないため、Windows環境での開発が必要な場合は、別途クライアントPCからリモートアクセスする構成を前提とする必要があります。
AI開発ツールの多くはLinuxベースで最適化されているため、運用面では大きな支障にはならないケースがほとんどですが、社内のIT環境がWindows中心の場合は、リモート接続環境やSSH接続の準備を事前に整理しておくことが重要です。
【ポイント6】推論・開発に最適化された設計
DGX Sparkは、AIモデルの推論やファインチューニング、プロトタイピングに適した設計です。一方で、数百億パラメータ規模の大規模モデルを最初から学習する場合や、高負荷な3Dシミュレーション用途専用に利用する場合は、NTTPCより別のGPUサーバーを提案いたします。
そのため、DGX Sparkは「検証・推論・軽量ファインチューニング」のフェーズに活用し、大規模学習が必要になった段階で適切な環境への移行を計画しておくことが望ましいでしょう。
【ポイント7】クラスタ構成は2台まで
公式には、最大2台までのクラスタ構成がサポートされています。2台構成でも最大400Bパラメータモデルの推論が可能であり、多くのAI開発シーンでは十分な拡張性を持っています。ただし、3台以上の分散処理や、より大規模な並列計算が必要になる場合は、導入時点で将来の拡張パスを明確にしておく必要があります。
まとめ
これまでAI開発の現場では、クラウドのコストや柔軟性の課題とオンプレミス環境が持つ導入・拡張のハードルとの間で、バランスを取る必要がありました。特に、アイデアを迅速に検証したい初期フェーズにおいて、環境面の制約がボトルネックとなるケースは少なくありませんでした。
DGX Sparkは、そのどちらでもない「手元で完結する高性能計算」という新しい選択肢となるでしょう。
NTTPCの導入サポート
NVIDIAエリートパートナーであるNTTPCでは、DGX Spark、OEM版 ASUS Ascent GX10、Dell Pro Max with GB10の販売だけでなく、GPUサーバー全般の導入前の要件定義から運用後のサポートまで、お客さまのニーズに沿い一貫した支援体制を提供しています。
【導入サポートについて】
導入前相談: ワークロードや用途に応じた最適な構成選定の支援
技術サポート: NVIDIA認定エンジニアによる導入支援と運用サポート
AI基盤の導入は、単なるハードウェア選定にとどまらず、運用コスト、拡張性、サポート体制を総合的に検討する必要があります。NVIDIAエリートパートナーとして長年のGPUインフラ構築実績を持つNTTPCは、お客さまのAI活用を技術面・運用面の両面から支援します。
DGX Sparkの導入をご検討の際は、ぜひお気軽にお問い合わせください。
※ASUSおよびAscent GX10は、ASUSTeK Computer Inc.の商標または登録商標です。
※Dell、Dell Pro Max with GB10は、Dell Inc.の商標または登録商標です。
※NVIDIA、NVIDIA Omniverse、NVIDIA DGX SuperPODは、米国およびその他の国におけるNVIDIA Corporationの商標または登録商標です。








