
生成AIの代表格であるChatGPTに象徴されるように、LLM(大規模言語モデル)は、私たちの仕事の進め方に大きな変化をもたらしています。
一方で、「機密データが心配」「一問一答しかできないのでは」などの誤解から、導入をためらう企業も少なくありません。
本記事では、LLMの概要、注目される理由、導入における誤解とその解消策、実用的な活用シーンまで、企業にとっての現実的な導入のヒントを初心者の方にもわかりやすく紹介します。
LLM(大規模言語モデル)とは
LLMは、AIの一種であり、大量のテキストデータを学習することで、言語の理解と生成が可能になる高度なモデルです。
ここで言う「大規模」とは、単に「AIのサイズが大きい」ということではなく、以下の2つの意味で“スケールの大きさ”を指します。
1. モデルの構造が大規模であること
LLMは、言葉の意味や文脈を表現するために、数十億〜数兆個のパラメータ(内部の数値情報)を持っています。
パラメータの数が多いほど、より繊細で複雑な言語のニュアンスを理解する能力が高まります。
2. 学習に使われるデータが膨大であること
LLMは、書籍・ニュース・Webページ・会話文など、膨大なテキストデータを読み込み、言葉の使い方や文脈のパターンを学習しています。
つまり、「大規模」であるとは、モデルの構造(パラメータ数)と学習データ量の両面が大きいことを意味しており、それがLLMの高い言語能力の源泉となっています。
LLMの基本的な仕組み
では、このLLMはどのような仕組みでテキストや言語を理解しているのでしょうか。
LLMは、ニューラルネットワークの一種である「トランスフォーマー(Transformer)」アーキテクチャを基盤に構築されています。
トランスフォーマーとは、文章中の単語同士の関係性に「注意(Attention)」を払いながら、どの言葉が文脈的に重要かを判断し、全体の意味を捉える仕組みです。
たとえば「私はりんごを食べた」という文をモデルが読むとします。このとき、「私」と「食べた」が関係していることで「誰が行動したか」がわかり、「りんご」と「食べた」が関係していることで「何を食べたか」が理解できます。
このように、文中の単語同士の意味的なつながり(関係性)に“注意”を向けることで、文の構造や意味を正しく把握する仕組みが「Attention」です。
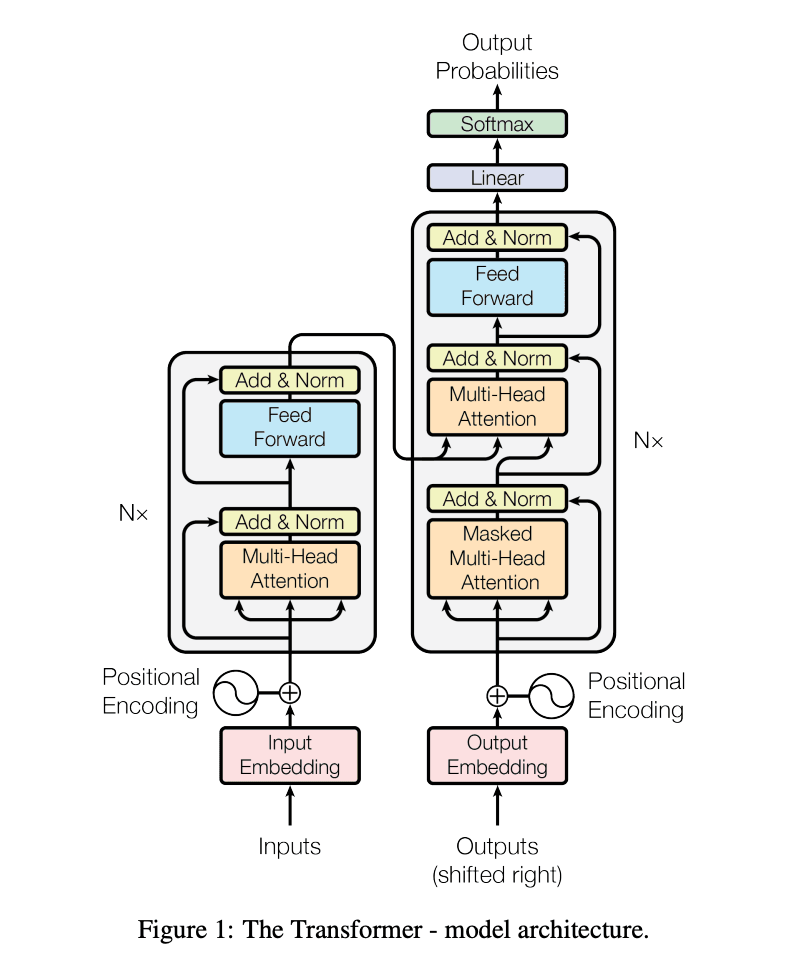
図1) トランスフォーマーモデルアーキテキクチャ(参考:Vaswaniら,Attention Is All You Needに基づき一部改変、日本語訳を付記)

図2) 図1使用語の補足解説(日本語訳)
トランスフォーマーでは、この注意の向け方を図中の「Multi-Head Attention」というブロックで計算しています。ここでは、複数の“視点”から注意を払うことで、さまざまな意味のつながりを同時にとらえることができます。
たとえば、一つの視点では主語と述語の関係、別の視点では目的語との関係に注目するなど、多角的に文脈を理解するための重要な機構です。
LLMと生成AIの違い
LLMと生成AIの違いは、「モデルとしての技術か」「用途としての機能か」というレイヤーの違いにあります。LLMは、自然言語を理解・生成するためのAIモデルそのものであり、あくまで技術的な「手段」にあたります。
これに対して生成AIは、テキスト・画像・音声・動画など、AIによって新たなコンテンツを生み出す“人工知能”を指し、より包括的な「目的や機能」の概念として用いられます。
中でも、ChatGPTやGeminiのようなサービスは、LLMを活用した生成AIの代表例です。このように、LLMは生成AIを通して社会での活用が急速に進んでいます。
なぜ今LLMが活用され始めたのか?4つの技術が生んだブレイクスルー
自然言語処理の研究は、2000年代以前から盛んに行われてきました。しかし、当時の技術では文法解析や翻訳など個別タスクに特化したモデルが中心で、柔軟で汎用的な自然言語処理は難しいとされていました。
その流れを一変させたのが、LLMの登場です。単なるモデルの進化ではなく、計算資源・インフラ・アルゴリズム・データの4つの要素が揃ったことで、LLMという“社会インフラ級”の技術が成立しました。
1. 計算資源:GPUによる並列計算
ディープラーニングにおいては、膨大な行列演算を繰り返す必要があります。これを可能にしたのが、GPUの高い並列演算能力です。
もともとは映像処理向けに開発されたGPUが、機械学習分野で活用され始めたことで、数十億~数百億パラメータ規模のモデルの訓練が現実的になりました。
2. インフラ:スケーリング則とクラウドの進化
OpenAIやDeepMindの研究によって示された「スケーリング則」は、モデルサイズ・学習データ量・計算量を増やすことで、性能が予測可能に向上するという法則です。この理論に基づいて、GPT-3やClaude 3のような巨大モデルが誕生しました。
しかし、それだけの計算資源を企業が自前で持つのは困難です。ここで重要な役割を果たしたのが、Microsoft AzureやGoogle Cloud、AWSなどのクラウドサービスです。GPUクラスタをオンデマンドで利用できる環境が整ったことで、膨大なトレーニングが可能になり、LLMの量産時代が始まりました。
3. アルゴリズム:Transformerアーキテクチャの革新
計算リソースの裏側には、アルゴリズムの進化もあります。LLMの基本的な仕組みの章でもお伝えしたように2017年に登場したTransformerアーキテクチャは、従来のRNN系モデルに比べて並列処理がしやすく、大規模モデルに最適化されていました。この構造がなければ、GPUの能力を最大限に活かすことはできなかったでしょう。
4. データ:学習データの可用性
最後に重要な存在が、インターネット上の膨大なテキストデータの存在です。Wikipedia、GitHubなど、アクセス可能なテキストデータが整備されていたことが、LLMの訓練を可能にしました。これは、2000年代〜2020年代前半の「Webの開放性」がもたらした恩恵ともいえます。
このように、GPUやクラウド、アルゴリズムの革新、そしてWeb上の豊富なデータの存在によって、LLMはかつての自然言語処理とは比べものにならない汎用性と性能を獲得しました。この技術は実際にビジネス現場でどのように役立ち、どのように導入すべきなのでしょうか。
LLM導入は単なる技術選定ではない──企業変革としてのAX( AIトランスフォーメーション)の本質

LLMは、単体で完結する技術ではありません。GPUやクラウドなどの計算インフラ、学習データの供給者、業務アプリケーションや業種特化型ツールといった外部要素と連携することで、初めて実用的な価値を発揮します。
つまり、LLMの導入とは、特定のツールを選ぶ“IT投資”ではなく、業務や組織全体の在り方を見直す企業変革(AX:AIトランスフォーメーション)そのものです。この変革には、インフラ、データ、人材、プロセスといった多くの要素が関わり、それらが相互に進化を促し合う“エコシステム的”な構造が不可欠です。
こうした枠組みが企業間・産業間に広がることで、いまやAIは医療や公共機関、研究など一企業の取り組みに留まらない社会的基盤となりつつあります。
LLMの導入が進まない?LLMにまつわる懸念とその実態
こうしたLLMをはじめとしたAI活用が進む一方で、現場での導入に際しては依然としてさまざまな懸念や誤解が存在します。 そのよくある懸念を見ていきましょう。
以下によくある懸念と考えられる対応策についてまとめました。
| よくある懸念 | 実際の現状・解決策 |
|---|---|
| 「自社の業務をAIは知らないので使えない」 | 業務データを活用したRAG構成やファインチューニングで対応可能。自社専用の知識のあるLLMの利用が可能。 |
| 「一問一答の範囲では使い道が限定的」 | 今や業務フローの自動化や意思決定支援など、プロセス全体に組み込めるレベルへと進化している。 |
| 「情報漏洩が心配で社外AIは使えない」 | ローカルGPU環境でのLLMやSLM(Small Language Model)の運用が注目。外部通信を遮断した完全閉域型の構成が可能。 |
| 「社員が使いこなせない/逆に負担になる」 | 導入支援やセットアップ済みGPUサーバー提供により、即運用可能な状態で納品。技術障壁を低減。 |
※SLM(Small Language Model):パラメータ数が比較的少ない小型の言語モデルのこと。エッジデバイスや専用業務向けに活用されることが多く、近年は「小さくても高性能」なSLMも登場している。
これらの誤解が解消されれば、LLMは「実験的な技術」から、「再現性ある業務変革ツール」へと位置づけを変えていきます。
特に、RAG(Retrieval-Augmented Generation)構成やセキュアなプライベートLLM基盤の整備によって、機密情報を含む業務を安心して使える環境が整ってきています。
LLM導入、その先にある「現場での価値」
導入ハードルを乗り越え、社内にLLMを取り入れることができたとします。
そこで次に問われるのは、「実際にどの業務で、どのような成果を生むのか」という実用面での具体性でしょう。
ここでは、PoC(概念実証)で終わらせず、継続的な価値創出へとつなげるためには、LLMがどの業務プロセスに意味のある形で組み込まれるのか具体的な例とともにご紹介します。
LLMが貢献する4つのビジネスシーンとその役割
まず前提として、LLMのようなAI技術には、「得意なこと」だけではなく、「苦手なこと」もあります。
たとえば数値計算や最新情報の正確性といった領域はあまり得意ではありません。一方で、人間のあいまいな意図や文脈を読み取り、それを構造化・再構成するタスクには非常に高い適性を持っています。
このような特性を踏まえると、LLMを導入する際は「どの業務領域に適用するのが効果的か」を見極めることが重要になります。
以下に、そうしたLLMの特性が活かされやすく、企業内でも比較的導入が進みやすい代表的なシーンをまとめました。
| ビジネスシーン | 具体例 | LLMの役割 |
|---|---|---|
| 1. 要望・問い合わせの理解 | 顧客からの製品に関する質問への回答生成 ・社員の業務上の疑問をマニュアルから検索し解答を提示 |
あいまいな表現を構造化・定型化し、アウトプット可能な形式に変換する |
| 2. 提案や説明の最適化 | ・顧客業界に合わせた提案書の作成 ・技術的内容を噛み砕いた説明資料の自動生成 |
相手の文脈や温度感を読み取り、伝わる言葉で再構成する |
| 3. 報告書・資料作成の自動化 | ・会議の音声記録からの議事録作成 ・複数データソースを統合した月次レポートの自動生成 |
異なる情報形式を意味単位で関連付け、自然な文章として出力 |
| 4. タスク・ナレッジへの反映 | ・会議で決まった事項をタスク管理ツールに自動登録 ・新しい知見を社内ナレッジベースに整理・蓄積 |
情報を行動に変換し、他システムとの連携まで自動化 |
具体的な例でもイメージしてみましょう。
たとえば営業担当者であれば──
- 過去のヒアリングメモや提案書をLLMに渡す
- 顧客の業種や興味に応じた提案文のたたき台を自動生成
- そのままCRMにワンクリック登録して共有
というように、「考える・書く・共有する」の流れが一貫して効率化されます。
このように考えると貴社の業務に当てはまる場面があるのではないでしょうか。「伝えるのが難しい」「繰り返し説明している」「一から作るのが面倒」そんな場面こそ、LLMが得意とする処理が発生するポイントです。
LLMの導入事例と効果
それでは、こうした課題に対して実際にLLMを導入した事例をみてみましょう。LLMの導入は、官公庁や自治体など、厳格な運用が求められる組織でも導入が進み始めています。
国土交通省の事例:行政データ処理の自動化
国土交通省の「Project LINKS」では、膨大な行政情報が十分に活用されていない現状を改善するため、生成AI(LLMを含む)を活用したデータ整備スキームの確立に取り組んでいます。
具体的には、生成AIを用いて、Word文書などの非構造データを、機械処理・二次利用が可能な形式に自動変換する仕組みの開発を進めています。
こうした取り組みにより、国土交通分野の行政情報を誰もが使いやすい形で提供し、官民で活用可能な情報インフラの構築を目指しています。オープンイノベーションの促進や、政策立案におけるデータ活用(EBPM)の推進を通じて政策の質を高め、社会全体の生産性向上に貢献することが期待されています。
【参考】What’s Project LINKS (国土交通省)
茨城県での事例:議会答弁書作成業務の効率化
茨城県取手市では、生成AIによる議会答弁書作成支援システムを導入しました(2024年9月)。
このシステムに一般質問の内容を入力すると、想定質問と答弁書の素案が作成されます。同システムは、市議会の議事録検索システムとも連動しており、一般質問に関連する過去の発言記録や他自治体の事例を検索・要約し、答弁書の素案に反映することができます。
システムを利用した職員へのアンケートによると、130件の議会答弁書のうち38件でシステムを活用し、利用職員の約半数が「業務時間が50%程度削減された」と回答しています。
なお、実際の答弁書作成については、「参考程度とし、ほぼ一から作成」との回答が45.9%、「大幅な修正を行って完成」が24.3%、「若干の手直しを加えて完成」が21.6%、「ほぼ手直しなしに完成」は0%、「その他」が8.2%でした。
LLMは単純な作業代替ではなく、人間がより高度な判断業務に集中できる環境を構築する技術として機能し始めています。
まとめ
本記事ではLLMの概要や仕組み、実際の導入までを紹介してきました。
多くの企業がLLMの導入に踏み切れない背景には、「まだ早いのではないか」「難しそうだ」「自社には合わないのでは」といった漠然とした不安や懸念が存在します。
しかし実際には、GPUを活用したローカル運用や、軽量なSLMによる省リソース対応、RAGを通じた社内ナレッジの活用など、すでに“使える選択肢”は整いつつあります。自身の環境にあった技術を選択することが有効となるでしょう。
NTTPCは、ミッションクリティカルなAIサービスから、高いパフォーマンスが求められる研究開発基盤に至るまで、用途・予算に合わせた適切なAI基盤の設計・構築が可能です。LLMの活用・GPUの導入を検討されている企業の方は、お気軽にお問い合わせください。
※「ChatGPT 」はOpenAI OpCo, LLCの登録商標または商標です。
※「Gemini」、「Google Cloud(GCP)」はGoogle LLCの登録商標または商標です。
※「Microsoft Azure」は、Microsoft Corporation の商標または登録商標である。
※「AWS」はAmazon.com,Inc. の商標または登録商標である。
※「Wikipedia」はWikimedia Foundation, Inc.の商標または登録商標である。
※「GitHub」はGitHub Inc.の商標または登録商標です。









