
事業にAIを本格導入する際には、運用を見据えた戦略的な導入設計と、AIの用途や自社の規模に合ったGPUを含む基盤構築が求められます。とはいえ、余計なコストや手間がかかったり、投資効果が出ないまま予算が尽きる可能性を排除するにはどうすべきか、悩ましいですよね。
そこで本記事では、「自社にとっての最適解」を見つけるためのヒントとして、単純なGPUの導入形態だけでなく、LLM/AI基盤のコスパを最大化するポイントまでご紹介します。
LLM/AI基盤のパフォーマンス最大化は、規模と用途に合ったGPUの選定から
LLM/AI基盤を成功させるには、十分な処理能力があるGPUで構築することが重要です。
GPUは、グラフィックス処理用のものから進化を遂げ、膨大な計算を効率的に並列処理できる特性を活かして企業のAI活用を支えています。
AIモデルの学習や推論では、大きく複雑なデータセットを高速に処理し、トレーニング時間を短縮しながらパフォーマンスと精度を向上させることが求められます。また、AI活用が進み、利用者が増えると処理が重くなるケースもあるため、運用時においても適切なパフォーマンスを維持する必要があります。
自社の規模やAIの用途、さらには導入後の運用体制なども考慮したGPU選びで、事業の成功に直結するLLM/AI基盤を構築しましょう。
LLM/AI基盤構築の序盤でよくある「GPUはオンプレミスか、クラウドか」論争
LLM/AI基盤構築の序盤では、「GPUサーバーをオンプレミス型にするか、クラウド型にするか」で議論になることがよくあります。これは、GPUの導入形態によって、コスト構造や拡張性、運用負荷、セキュリティなどに大きな違いがあるためです。
一般的には、例えば小規模な検証から始めるなら「クラウド型」、最初から大規模な開発基盤を作るなら「オンプレ型」というように、代表的な導入形態である2つのどちらを選ぶかが議論の焦点になることが多いでしょう。
しかし、LLM/AI基盤を構築する目的や予算、人員体制、データの性質によって、導入形態の最適解は異なります。大切なのは「オンプレミスかクラウドか」という対立関係で選ぶことではなく、自社でAIをどのように活用したいのか、企画から運用フェーズ(利用開始後の改修やチューニングまで)一気通貫で捉えることです。それによって、「オンプレミスかクラウドか」という主にハードウェアの選択肢として語られる側面が、いか領域の狭いトピックであるか分かって頂けるはずです。
まずは、オンプレミス型GPUサーバーとクラウド型GPUサーバー、それぞれのメリットとデメリットを整理しておきましょう。
オンプレミス型GPUサーバーのメリット・デメリット
オンプレミス型のGPUサーバーは、自社の施設内に物理的なITインフラを設置し、運用・管理する方法です。
オンプレミス型で構築する場合、最大のメリットは自由度と安全性です。自社のAIの開発やトレーニングのプロセスに最適なハード構成を自由に設計し、データは社内に閉じた状態で安全に運用できます。
また、月額利用料が発生しないため、大規模なモデル学習や長期間の運用では、ランニングコストを抑制できる可能性があります。
一方で、デメリットは初期投資がかかること、構築が長期化すること、運用が煩雑であることの3つです。GPUサーバーは発熱しやすく、冷却設備や電源などにまとまった設備投資が必要で、導入までのリードタイムも長くなります。
運用保守やアップグレードも自社で担うため、専門性のある人材も手配しなければなりません。
クラウド型GPUサーバーのメリット・デメリット
クラウド型GPUサーバーは、自社でサーバーを保有せず、ネットワークを介してGPUの計算能力を利用する方法です。
クラウドサーバーのメリットは、スピードと柔軟性です。自社でハードを持たず、使いたいときだけ高性能GPUを利用できるため、初期投資を抑えつつ短期間でAI開発ができます。
自社の規模や用途に応じて、GPUの種類や数をスケールアウト・スケールインできるのも強みです。
ただし、長期利用では累積コストがかさむことに注意が必要です。さらに、突然のサービス停止や料金体系・APの仕様変更などのサービス継続に関する不確実性、機密情報の漏洩リスクやコンプライアンス違反、法的リスクへの注意が必要です。
LLM/AI基盤構築で重要なのは、GPUの導入形態だけではない

LLM/AI基盤構築において重要なのは、GPUの導入形態だけを検討しても、全体のパフォーマンス向上につながらないということです。
GPUは、あくまでLLM/AI基盤のアクセラレーターであり、冷却装置や電源などのハードウェアインフラ、帯域ネットワーク、ストレージ、CPU構成といった要素が噛み合って、初めて真のパフォーマンスを発揮することができます。
よって、LLM/AI基盤構築には、多岐にわたる専門的な知識が必要です。このすべてを自前のエンジニアだけで設計・構築・運用するのは、もはや現実的とはいえません。
自社に最適なLLM/AI基盤を構築するために重要なのは、自社のエンジニアのスキルと、AI戦略における差別化ポイントを見極め、限られたリソースをそのポイントに集中させることです。
例えば、自社独自のAIモデル構築やデータ活用設計は自社で持ち、GPUのクラスタ管理や冷却・電源設計などは外部のベンダーに任せるといった具合です。こうすると、インハウスで持った部分も、ベストプラクティスを持つ専門ベンダーにアウトソースした部分も、高速で作業が進みます。
結果的に、無駄なコストや作業の遅れによるロスを省いて、スピーディーにLLM/AI基盤を立ち上げることができるでしょう。
LLM/AI基盤を構築する際は、GPUの導入形態に関する議論に終始せず、長期戦略のもとでインハウスとアウトソースの使い分けを検討することが大切です。
GPUサーバーのコスパを最大化するポイント
前述したとおり、LLM/AI基盤の構築は、目的と規模に合ったGPUサーバーを導入すれば成功するわけではありません。最終的なゴールは、事業成長につながるAI活用であり、そのためにはトラブルのない運用を実現する必要があります。
つまり、自社のスキルやリソースでカバーできない、例えばハードウェアの詳細設計や冷却・電源設計を外部のベンダーにアウトソースすることは、AI導入を今後の成長戦略への投資と位置付ける企業にとって合理的で成功率の高い方法なのです。
では、どのようなポイントで検討すれば、LLM/AI基盤のコストパフォーマンスを最大化できるでしょうか?
ポイント1:自社に最適化されたLLM/AI基盤を構築する場合、当初は1台のGPUサーバーで十分であっても、利用者増や計算能力の要求増に伴って、複数台構成に拡張する必要があります。
基盤全体としても、従来の企業内ネットワークとは異なる特性に耐えうる高速で大容量なネットワーク設計や、大量のデータを効率的かつ安全に管理できるストレージ機器が求められます。
ポイント2:また、ハードウェアを支える運用・ジョブ管理・モニタリングなどのソフトウェア設計も欠かせません。チューニングやパフォーマンス分析、セキュリティ・トラブルシューティングなどの要素にも注目する必要があります。
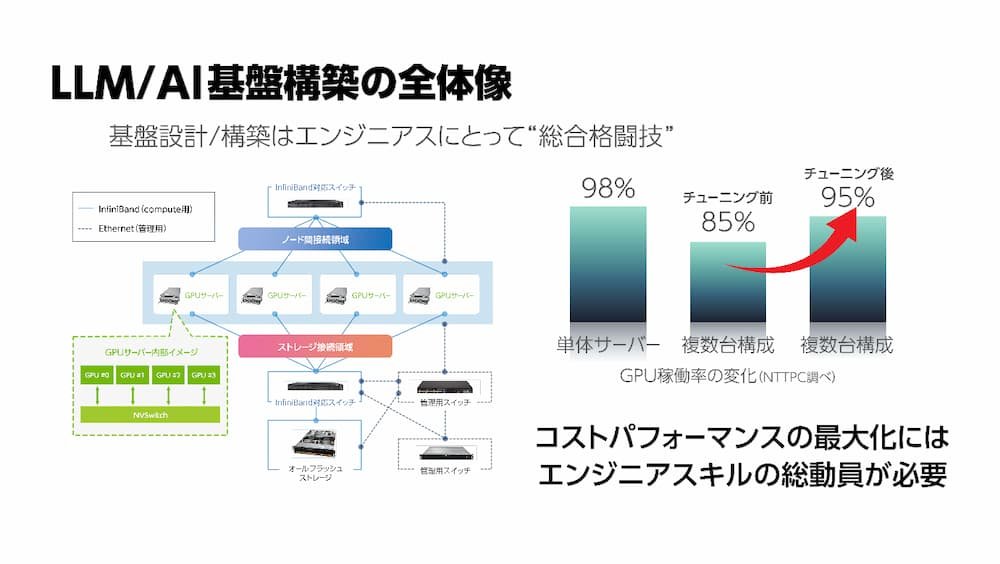
これらのことから、LLM/AI基盤の包括的な設計・構築は、いわば総合格闘技のようなものであり、単にGPUを並べるだけでは不十分であるといえます。
LLM/AI基盤全体のパフォーマンスを最大化しつつ真に使いこなすには、ハードとソフトの両輪を兼ね備えた視点と知見を持ち、AI基盤全体の設計・構築・運用をトータルで支援できるベンダーをパートナーにすべきといえるでしょう。
自社に合ったGPU選定で、AI活用の成果を最大化しよう

GPUは、確かにLLM/AI基盤構築の要であり、スペックだけでなくAI活用の目的・規模・リソースに合わせた導入形態と構成が求められます。ただし、LLM/AI基盤のパフォーマンスを決めるのはGPUだけではありません。クラウド型でもオンプレミス型(ワークステーション1台~必要に応じて複数台に拡張できるサーバー構成)でも、運用管理までには様々なポイントでノウハウの注入が必要です
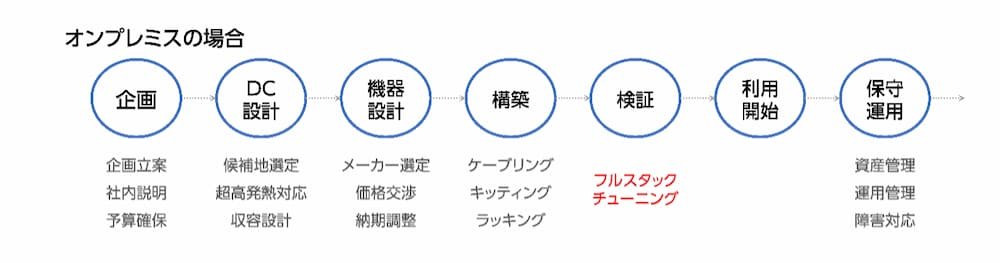
特にオンプレミスでのGPUサーバー構築を選んだ場合、GPUクラスタの設計に必要なスキルをすべて自社エンジニアでカバーしていると、AIの利用開始までに長期間を要する可能性が大きくなります。
自社の強みを活かして目的に合ったLLM/AI基盤を構築するには、よくある「オンプレミスか、クラウドか」の2択での判断は、おすすめできません。自社でノウハウを貯めるべき部分と、パートナーに任せる部分を明確に切り分けて、パフォーマンスと費用対効果を最大化できるプランが必須です。
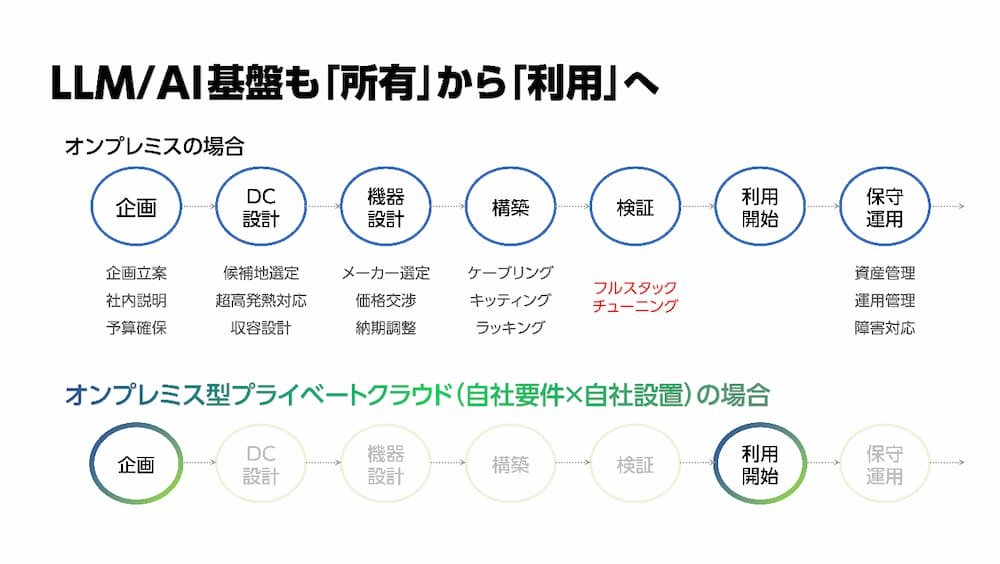
例えば、オンプレミス型を考えている場合、GPUプライベートクラウドの活用も有用ではないでしょうか。
GPUプライベートクラウドは、自社専用に構築・管理されるGPUリソースのクラウド環境です。GPUプライベートクラウドを利用すれば、自社に最適化されたLLM/AI基盤を短期間で構築でき、運用管理に悩まされることなく自社の本業に集中することができます。
経営課題解決に向けたLLM/AI基盤構築は、多様な規模で構築実績のあるNTTPCにお任せください。











