業務課題解決や効率化、新規ビジネス創出などを目的として、自社でAIやLLM開発を検討する企業が増えています。こうした開発には膨大な演算処理が必要で、処理するデータ量によっては作業負荷が大きく、時間がかかることも少なくありません。
高い並列処理能力を持つGPUは、こうした開発課題を解決する強力な手段です。一方で、高性能なGPUは価格が高いため、自社の用途に合ったものを選びたいですよね。
この記事では、GPUがAIやLLM開発に求められる理由のほか、GPU選定でよくある失敗例と、購入前に知っておきたい選定ポイントなどについてご紹介します。
なぜ今、GPUがAIやLLMの開発に欠かせないのか
GPUはGraphics Processing Unitの略で、元々は画像処理を高速に行うために開発された演算装置です。
しかし近年、その高度な計算能力が画像処理以外の分野にも活用されるようになり、汎用計算向けGPU(GPGPU)として進化してきました。
進化したGPUの大きな特長は、大量の計算を同時並行で高速に処理できる点にあります。
AIやLLM(大規模言語モデル)の開発では、推論時にも膨大なデータを扱って大量のパラメータを学習するため、並列処理性能が欠かせません。CPU単体では処理が追いつかないような大規模な計算でも、GPUを使えば短時間かつ高効率で実行できるようになります。
以上のことから、AI・LLM開発の最前線では、GPUが欠かせないものとなっているのです。
購入前に押さえておきたいGPUの主な用途
GPUはその高い並列処理能力から、様々な分野で活用されています。GPUを購入する際には、自社の用途に応じたスペックや機能を理解した上での検討が欠かせません。GPUの主な用途について確認しておきましょう。
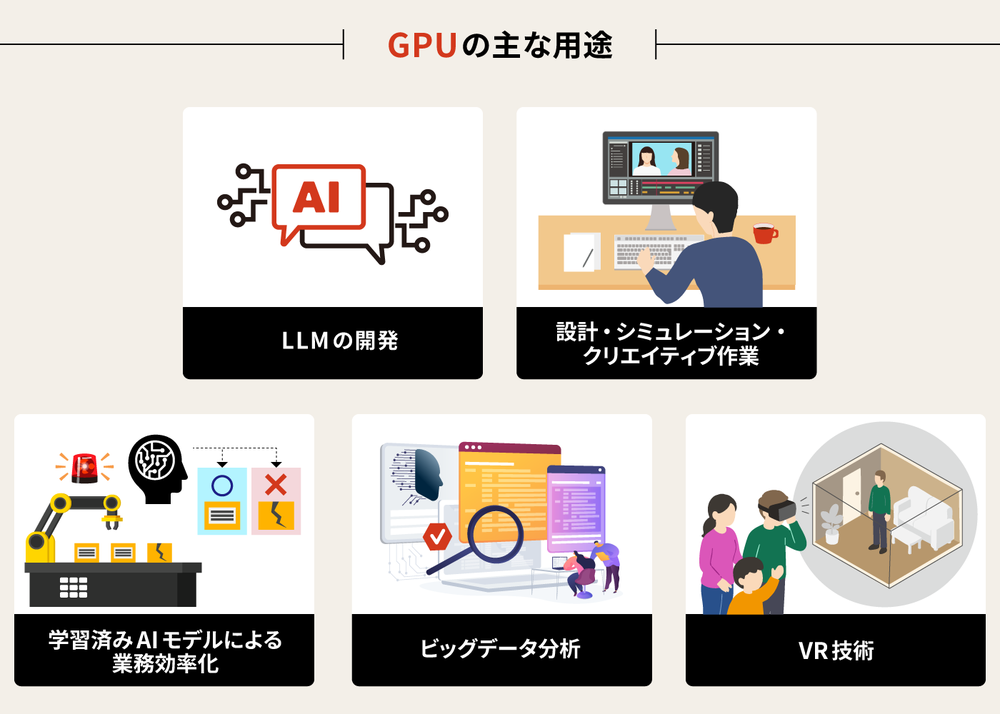
LLMの開発
GPUの並列演算能力は、LLM(大規模言語モデル)開発の基盤技術です。
近年のLLMは数千億〜数兆のパラメータを持つモデルが主流となり、OpenAIのGPT-3は約1,750億のパラメータを持っています。GoogleのGemini、MetaのLlama 3など、1兆を超えるモデルも登場しました。
このような大規模モデルの学習には、膨大な量の行列計算が必要です。しかし、従来のCPUは、1つまたは複数の高性能コアでの逐次処理が得意分野で、同時に大量の計算を行う並列処理には向いていません。
これに対して、GPUは数千個にもおよぶ小さな演算コアを持ち、大規模な並列演算に特化しています。
従来のCPUでは学習に数ヶ月以上かかるような処理も、GPUの並列処理により数週間で処理することができます。
また、低レイテンシで多数のリクエストを処理する必要がある推論フェーズなどでもGPUが使われています。
このように、学習に要する時間やコストの観点からも、GPUはLLMの開発・運用に不可欠な存在だといえます。
設計、シミュレーション、クリエイティブ作業
GPUは、製造業や建築業などの設計現場から、解析・検証、さらには映像制作といったクリエイティブ分野まで、様々な用途で活用されています。
例えば、自動車や建築物の開発では、まずCADソフトを使って精密な3D設計を行います。このとき、複雑な構造や膨大な部品をリアルタイムに描画・操作するために、GPUの描画処理能力が必要不可欠です。
続いて、設計したCADモデルを使って衝突実験などの検証作業(CAE)が行われます。
これらのシミュレーションも、数百万以上の要素を扱う高度な数値計算を含むため、GPUによる並列演算が大幅な時間短縮と精度向上を実現します。
さらに、動画編集や3DCG制作といったクリエイティブな作業でもGPUは重要です。高解像度映像のリアルタイムプレビューや複雑なレンダリング、エフェクト処理を高速化し、制作のスピードと品質の両立に貢献しています。
学習済みAIモデルによる業務効率化
製造業では、不良品検出、機械の異常検知、需要予測などにおいて、機械学習や特徴抽出を自動化し、大量のデータから機械学習よりも精度の高い予測や認識ができる、ディープラーニング(※1)を行ったAIモデルが活用されています。その際、高度な分析や推論を高速で行うために、GPUが使われているのです。
また、医療業界でも、AIによる解析で医師の診断を支援する胸部X線画像診断システムが一般的になりつつあります。企業によっては、汎用的なAIに自社の情報を入れることで、より自社に特化したAIモデルとする、ファインチューニング(※2)を行って業務効率化を進めています。
※1ディープラーニング:人間の脳の神経回路を模した「ニューラルネットワーク」を多層に重ねたモデルを使い、大量のデータから特徴やパターンを自動で学習するAI技術。
※2ファインチューニング:あらかじめ大規模データで学習させたAIモデル(事前学習モデル)をベースに、自社の目的やデータに合わせて再学習させる手法。ゼロから学習させるよりも短時間で高精度な自社にあったモデルを作ることができる。
ビッグデータ分析
小売業における顧客行動分析や市場動向予測など、ビッグデータを迅速に処理したいシーンでもGPUが活躍しています。
例えば、店舗のPOSデータやECサイトの購買履歴、SNSの投稿内容など、日々大量に蓄積されるデータの高速解析です。GPUの並列処理によってこれらのデータを解析することで、売れ筋商品の傾向や地域ごとの需要の変化をリアルタイムで把握できます。
さらに、顧客ごとの購買履歴や行動パターンも分析することで、パーソナライズされた商品のレコメンドやターゲット広告の最適化にもつなげることができます。
これにより、在庫の過不足を防ぎつつ販売機会を最大化できるようになり、マーケティング施策や仕入れ戦略の精度とスピードが向上します。結果として、機会損失や在庫の無駄を減らし、市場の変化に即応できる企業として競争優位性を確立することができるでしょう。
VR技術
VRは、実際に体験するのが難しい危険な工場作業の安全教育や、反復練習が重要な外科手術のトレーニング、設計段階にある住宅の内見などに使われています。
これらのVRコンテンツを、よりリアルで没入感の高いものにするために、ユーザーの視点に合ったグラフィックスを高速で描画するGPUが必要です。
また、VRコンテンツの体験時に、頭の動きと映像の動きがずれることで生じる「VR酔い」を防ぐためにも、即座に視点を再計算して、映像の遅れを最小限に抑えられるGPUが欠かせません。
GPU選定でよくある失敗例
GPUの選定に失敗すると、コスト増や性能不足、運用負担の増大を招きます。選定ミスにつながりやすいポイントを事前に把握できるよう、GPU選定で実際によくある失敗例を紹介します。
失敗例① 高機能GPUを購入したが、用途とのミスマッチでオーバースペックに
大手ECサイトを運営する企業が、数千件におよぶ商品の紹介文を自動生成するため、自社システムに生成AIのAPIを導入することに。
「社内データを学習させた専用モデルの稼働には高性能なGPUが必要だろう」とハイエンドモデルを購入しましたが、実際の用途は学習よりも推論が中心だったため、GPUの性能を使いきれていません。
結果として、導入コストや消費電力がかさむ結果となりました。
失敗例② 既存電源を再利用したところ、容量超過で不安定な動作が頻発
AI開発を主力事業とするスタートアップ企業が、最新の深層学習モデルの効率的な学習に向けて高性能GPUを購入。
しかし、導入後、突発的な再起動や不安定な動作などが発生し、作業遅延が目立つようになりました。分析の結果、かつて使用していたミドルレンジGPU用の電源を再利用していたことが原因と判明。設備の再購入や電源周りの改修で予定外の高額なコストが発生したほか、作業遅延に伴う再調整などの手間も増えました。
失敗例③ VRAM容量が不十分で、開発が大幅に遅延
画像解析や機械学習モデルの開発を手掛けるIT企業が、大規模な衛星画像データを活用したAIモデルの開発をスタート。しかし、学習処理や画像処理の速度が極端に低下したり、処理中にアプリケーションがクラッシュしたりする事象が頻発しました。
調査をすると、処理する画像の大きさに対するVRAM(※3)容量の不足がボトルネックになってパフォーマンスが低下していることが判明。学習の処理時間の大幅な超過、およびそれに伴う開発スケジュールの遅延、GPUの再調達コストの発生など、深刻な影響が生じました。
※3 VRAM( Video Random Access Memory):GPUに搭載された専用メモリで、画像データや演算処理中のデータを一時的に保持します。VRAM容量が不足するとスワップが発生し、処理速度が大幅に低下する可能性があるため、パフォーマンス維持に重要な指標となります。
失敗例④ 冷却装置の設計ミスにより、GPUの性能が低下
あるエンジニアリング企業が、大規模な並列演算処理を必要とする新製品開発プロジェクトにおいて、高性能GPUを複数搭載したワークステーションを導入しました。
ところが、導入直後から解析処理が異常に遅く、パフォーマンスが不安定に。調査すると、エアフローやファンの設計ミスでGPUが異常な高温になり、自動的に性能抑制(クロックダウン)が発生していることがわかりました。
これにより、開発の遅滞はもちろん、システムの負荷増大、GPUの短命化などの影響が生じています。
失敗例⑤ ソフトウェアとの互換性がなく、正常に動作しなかった
AIによる自然言語処理や画像認識の受託開発をする企業が、コストパフォーマンス向上のため、AMD製のGPUを搭載した新たな開発環境を構築。
開発に着手すると、PyTorch(※4)やTensorFlow(※5)といったAI開発フレームワークでエラーや動作不良が頻発しました。特に、GPUを用いた学習処理や分散トレーニングの一部が正常に動作しません。原因は、選定したGPUがAMD製だったため、NVIDIAが提供するCUDA(※6)に依存した一部機能との互換性がなかったことにありました。
結果として、期待していた処理の高速化につながらず開発に遅れが生じた上、GPU再選定コストも発生しています。
※4 PyTorch…Facebook(現:Meta)が開発した、機械学習・深層学習のためのオープンソースフレームワーク。Pythonで記述されており、NVIDIA製GPUを使うことで、ニューラルネットワークの学習や推論を高速化できる。
※5 TensorFlow…Googleが開発したオープンソースの機械学習・深層学習ライブラリ。AIモデルの構築、学習、推論(予測)を行うためのフレームワークで、NVIDIA製GPUでの高速学習に対応する。
※6 CUDA…NVIDIAのGPUを、高速な並列計算に活用するためのプラットフォーム。GPUを使って、AI、シミュレーション、画像処理などの重い処理を高速に実行できる。
GPU選びの失敗を防ぐ!用途に合わせたGPUを選ぶためにチェックしたい8個のポイント

GPUは、用途や予算、運用環境によって、最適なスペックや構成が大きく異なります。特に、AI関連の活用では、モデルを学習させる「AI学習」と、実際に稼働させる「AI推論」とで求められるGPUの性能が大きく異なるため、運用体制や将来的な拡張性も含めた総合的な視点が重要です。
長期的に安定稼働できる構成を目指すためにも下記のようなポイントをチェックして、自社の用途に適したGPUを選定しましょう。
■自社の用途に合わせたGPUを購入するためのチェックポイント
- コア数
- 演算性能(FP4/FP8/FP16/FP32/FP64)
- 閉域網とインターネットの併用によるコスト削減
- VRAM容量
- メモリ帯域幅
- 運用体制(環境、人員)
- メーカー
- 消費電力
- ソフトウェアの互換性
コア数
GPU内部の処理ユニットの数(コア数)が大きいほど処理性能が向上し、同時に多くの計算を高速で実行できます。AIやレンダリング処理といった複雑なタスクを実行したい場合は、GPUのコア数も用途に応じて選びましょう。
なお、コア数は「CUDAコア数(※7)」「Tensorコア数(※8)」「RTコア数(※9)」といった形で製品に記載されています。
※7 CUDAコア数…GPU内で実際に並列計算を行う小さな演算ユニットの数。数が多いほど同時に多くの処理ができ、AIの学習や画像処理などを高速に実行できる。
※8 Tensorコア数…AIに特化した行列計算を行う専用演算ユニットの数。ディープラーニングの学習や推論を高速化し、短い時間で高精度なAI処理を実現できる。
※9 RTコア数…3DCGをリアルにするためのレイトレーシング(Ray Tracing)処理に特化したコアの数。リアルタイムで、高品質な影や反射などのグラフィック表現を高速に処理できる。
演算性能(FP16/FP32)
コンピューターが数値計算をする際には、「FP4」「FP8」「FP16」「FP32」「FP64」といった浮動小数点数(Floating Point)形式が使われます。これは、数値を表すための形式であり、例えばFP16なら16ビット、FP32なら32ビットで数値を扱うことを示します。
浮動小数点数は、桁数が少ないほうが速くて軽いですが、誤差が生じがちです。一方、桁数が多いと処理は遅くなりますが、正確性が上がります。そのため、用途に合わせて使い分けることが大切です。
特に、AI分野でよく使われるのは「FP16」と「FP32」です。
FP16は、FP32に比べて数値の表現精度がやや落ちる分、処理速度が速く必要なメモリ量も少なくて済むという特徴があります。AIの学習や推論処理では、計算結果の厳密な精度よりも、膨大なデータを高速で処理する能力を重視しなければなりません。そのため、FP16による高速な演算が有効になります。
FP16での演算速度はTensorコアの数に比例するため、AI処理を前提としたGPU選定の際は、Tensorコアの数に注目しましょう。
また、1秒間に行うことができる浮動小数点演算の回数を示す「FLOPS(Floating Point Operations Per Second)」という指標も重要です。例えば、FP16で2.2PFLOPSと記載されていれば、「FP16の精度で、1秒あたり2.2ペタフロップス(=2,200兆回)の計算ができる性能がある」ことを表しています。
ただし、単にコア数の大きいGPUを接続しても、適切なソフトウェアメモリ帯域、冷却設計などが伴わなければ、求める成果は得られません。
特に、生成AI、LLMの学習基盤として機能するGPUクラスタの構築などを視野に入れている場合は、コア数だけでなく全体のバランスを見て慎重に選ぶことをおすすめします。
VRAM容量
GPUに搭載されるVRAMの容量が大きいほど、画像や動画、学習データなどを一時的に多く保持でき、高い解像度が求められるグラフィック作業をスピーディーに行えます。
一方、容量が不足するとスワップが発生して処理速度が低下するため、タスクに応じた容量を見極めなければなりません。特に、高度な映像処理や大規模なAIモデルを扱う場合には、十分なVRAM容量があるものを選んでください。
製品には、4GB、8GB、12GB、16GB、24GBのように記載されています。
メモリ帯域幅
メモリ帯域幅は、GPUとVRAM間で1秒間にやりとりできるデータ量を示す指標です。帯域幅が大きいほど、高速に大量のデータを処理でき、AI学習やリアルタイム分析などのパフォーマンスが上がります。高性能GPUを選ぶ際には、必ずチェックしましょう。
メモリ帯域幅のスペックは、「GB/s」という単位で製品に記載されています。
運用体制(環境、人員)
高性能なGPUは、高い処理能力を発揮する分だけ発熱しやすく、適切な冷却設計が必須です。
特にオンプレミス環境の場合、十分な冷却性能を備えたサーバールーム、周辺ストレージの構成、ネットワーク帯域といった周辺インフラも含めて整備しなければなりません。また、それらの環境を安定的に運用するための人員も必要です。
高性能GPUを選ぶ場合は、発熱の大きさを想定して設備とメンテナンス体制を整え、トラブルを未然に防ぐ運用体制が確立できるかを検討しましょう。
メーカー
GPUのメーカーも、選定時の重要な要素です。
半導体メーカーとしてGPU市場をリードするNVIDIA、コストパフォーマンスに定評があるAMDといった世界的に実績があるメーカーであれば、導入後のサポートやトラブル対応も充実していることが多く、運用面の不安を解消できます。
消費電力
高性能GPUは消費電力が大きく、電源ユニットのアップグレードや補助電源の準備が必要になる場合があります。導入費用やランニングコストを左右する可能性が高いため、TCO(総所有コスト)の視点で自社環境に合った消費電力のGPUを選びましょう。
ソフトウェアの互換性
ソフトウェアとGPUに互換性がないと、使用したいソフトやフレームワークを正常に動作させることができません。ソフトウェアの公式サイトなどで、動作確認済みのGPUリストを確認しましょう。
特に、PyTorchやTensorFlowといったAI開発フレームワークを使う場合は、CUDA対応が必須です。
自社に合ったGPU選びがビジネス成長のカギ

GPUは、AI・LLM開発やグラフィック開発をはじめとした、現代の様々なコンピューティング領域において不可欠な存在です。企業がGPUを適切に活用できれば、現状のビジネス課題を解決し、新たな価値を生み出す大きな武器になるでしょう。
その一方、GPUの強化は、高価な投資であることも確かです。用途や予算に合わせて、必要十分な性能を持つ製品を見極めることが、コストの最適化とビジネス成果の最大化を両立することにつながります。
NTTPCは、NVIDIA認定 エリートパートナーとして、用途や規模に合ったGPU選定をサポートします。
また、マルチベンダーとして、サーバー、ストレージ、ネットワークを含めた一貫性のある組み合わせの提案が可能です。統合的なクラスタ設計・構築ノウハウを活かして、お客さまのビジネスにあったGPUプラットフォームを数多く提供してきました。
さらに、ネットワークやデータセンターまでをワンストップで提供する「GPUプライベートクラウド」で、運用管理も支援しています。
GPU選びは、単なるハードウェア選定ではなく、企業の成長を支える重要な戦略投資です。失敗のないGPU選びに向けて、まずは適切なパートナーを選び、自社にとって最適なGPU環境を整備していきましょう。