
企業のAI開発において、GPUへの投資は数千万円から数億円規模に達することも珍しくありません。「最新のGPUを導入すれば解決するはず」と考え、カタログスペックや汎用的なベンチマークスコアだけを頼りに選定した結果、想定したパフォーマンスが出ない・コスト対効果が見合わないといった課題に直面し、導入後に後悔するケースも見られます。
特に、生成AIの活用およびそれに伴うLLM(大規模言語モデル)の利用が一般化した2026年現在、GPUに求められる性能要件や、重視すべき指標は過去と比べて大きく変化しています。本記事では、GPU選定での失敗を防ぐうえで重要である業界標準ベンチマーク「MLPerf™」の活用法と、最新データに基づいたGPU型番比較について解説します。
なぜ汎用ベンチマークだけでは不十分なのか
GPUを選定する際、多くの担当者がまず参照するのは、メーカー公式サイトのスペック表や、インターネット上で公開されている汎用ベンチマークです。しかし、AI開発、とくにLLMの領域では、これらの数値が必ずしも実運用での性能や扱いやすさを十分に反映しているとは限りません。
例えば、次のような課題が生じることがあります。
| 課題 | 導入後に起きること | 見落としがちな要因 |
|---|---|---|
| 汎用ベンチマークの高スコアGPUを選んだが、AI学習が想定より遅い | 学習ジョブの完了時間が延び、開発サイクルや検証が回らない | グラフィックス系の負荷前提の指標で、行列演算やフレームワーク最適化の差を反映しにくい |
| VRAM容量だけを見て選定したら、推論速度が期待外れだった | モデルは載るが、トークン生成が延びず、同時処理数を上げにくい | 容量だけでなく、メモリ帯域幅やアーキテクチャ世代、実装最適化の影響が大きい |
こうした「スペック表だけでは見えにくいギャップ」を事前に把握するための材料として役立つのが、実際のモデルを使って性能を測定する業界標準ベンチマーク「MLPerf™」です。
次では、MLPerf™の位置づけと、どのような指標を見れば自社の用途に近い性能を読み取れるのかを整理します。
MLPerf™で見極める「AI用途の本当の性能」
AI用途で必要となる実性能は、カタログスペックや一般的なベンチマークだけでは正確に判断できません。こうしたスペックとの乖離(かいり)を防ぎ、導入後のパフォーマンスを客観的に評価する基準として業界で広く利用されているのが「MLPerf™」です。

MLPerf™(参考:Benchmarks MLCommonsバナーから引用)
MLPerf™とは:MLCommons™による業界標準ベンチマーク
MLPerf™は、Google、NVIDIA、Intel、Meta などの主要企業や大学が参加するコンソーシアム「MLCommons™」によって策定されたベンチマークです。単なるハードウェアの理論性能ではなく、「実際のAIモデルを動かした際の処理性能」を測定することを目的としています。そのため、MLPerf™ではGPU単体の性能だけでなく、GPU台数やノード構成、インターコネクト、ソフトウェアスタックを含めたシステム構成全体を前提とした結果が公開されます。メーカーの発表値も最適条件での性能を把握するうえで有用ですが、複数企業が同一ルール・同一タスクで投稿するMLPerf™は、実運用に近い条件での性能傾向を確認するための客観的な指標となります。
MLPerf™(参考:MLCommons MLPerf 利用画面を引用)
Training(学習)とInference(推論)の測定項目
MLPerf™には複数のベンチマーク群がありますが、企業のGPU選定でまず参照されやすいのは、学習性能を評価する「Training」と、推論性能を評価する「Inference:Datacenter」の2つです。
- Training(学習): AIモデルがどれだけ速く目標精度まで学習を完了できるかを測定します。開発期間の短縮やモデル更新サイクルの高速化を重視する場合に、特に重要となる指標です。
- Inference(推論): 学習済みモデルがどれくらいの速さで応答できるかを測定します。サービスの本番運用時におけるレスポンスや、1台あたりの処理効率・運用コストを評価する際に見るべき指標です。
自社の目的が「AIを作る(学習)」フェーズなのか、「AIを使う(推論)」フェーズなのかによって、確認するべき指標は大きく異なるため、目的に適した指標で評価する必要があります。
汎用ベンチマークとの違いと結果の見方
MLPerf™は、理論性能や単一条件のスコアではなく、実際のAIモデルを決められたルール・実装条件で動かしたときの実測結果を比較できる点が特徴です。加えて、結果はGPU単体ではなく、サーバー構成・GPU台数・ソフトウェア実装(最適化)まで含めた「システムとしての結果」として公開されます。そのためMLPerf™を読むときは、「どのGPUが速いか」をいきなり結論づけるのではなく、「どの構成(=どのシステム条件)で、その数値が出ているか」を先に押さえることが重要です。
また、結果ページ(スイート)によって結果に表示される列は異なります。ただし、同じスイートの結果表内でも提出されたパターンごとに条件があるため、比較に影響する列(モデル、Availability、Accelerator、GPU台数、Scenarioなど)の値が一致している行同士で見比べることや、システム値が異なる前提で参照する必要があります。
このような前提の上で、MLPerf™を読み解く上での主要な項目を次のように整理しました。
| 確認項目 | 読み解く際の観点 | 生じる可能性のある誤読例 |
|---|---|---|
| Round / MLCommons™Model / Availability | ラウンド、モデル、提供形態(市販構成かどうか)をそろえて比較する | 前提条件が異なる結果を同列に比較してしまう |
| System Name | サーバー機種とGPU構成(台数・実装形態・プラットフォーム)を含む構成全体として読む | サーバー構成の違いをGPU単体の性能差として解釈してしまう |
| Accelerator | 比較対象となるGPU型番を明確にそろえる | 型番の異なる結果を混在させて比較してしまう |
| GPU台数(Inference:# of Accelerators / Training:Accelerators Per Nodeなど) | GPU型番だけでなく、構成規模(台数)も含めてそろえる | 台数差の影響を単体GPUの性能差として扱ってしまう |
| Scenario | Offline / Serverなど、測定シナリオをそろえる | 条件の異なる結果を比較し、結論が崩れる |
| Software | 推論・学習スタック(例:TensorRT など)を確認する | ソフトウェア最適化の差を考慮せずに結果を解釈してしまう |
例として、System Name に「ASUSTeK ESC N8 H200 (8x H200-SXM-141GB, TensorRT)」のような表記がある場合、これは単なるGPU名を示しているわけではなく、サーバー機種、GPU台数、GPUの実装形態、使用されているソフトウェアスタックなど、その結果が得られた検証済みのシステム構成全体をまとめて示しています。MLPerf™では、こうしたシステム構成に含まれる各要素がセットで評価条件を形成しており、個々の項目を切り出して比較することは想定されていません。
GPUに関する情報も、その一部として提出構成にひもづいて扱われます。そのため、VRAM容量などの詳細はSystem NameやAccelerator表記、あるいは詳細な構成情報を確認したうえで解釈する必要があります。同じGPU型番であっても、提出構成が異なれば前提条件も異なる可能性がある点に留意しておきましょう。
【実践】MLPerf™で読み解く主要GPU構成の学習・推論性能
ここでは、2026年時点で企業がAIインフラとして導入を検討する際に代表的な選択肢となる NVIDIA H100/NVIDIA H200 に加え、Blackwell 世代(NVIDIA B200 搭載構成や GB200 NVL72 など)も視野に入れつつ、MLPerf™ の公開結果や NVIDIA が公開しているベンチマーク情報を参照しながら、学習性能・推論性能をどのように読み解くかを整理します。
実際に MLPerf™ の結果を確認していくと、数値が並んでいることから GPU の単体性能を比較しているように見えてしまうことがあります。しかし、MLPerf™ には GPU 台数やノード構成、インターコネクト、ソフトウェアスタックが異なる、さまざまなシステム構成が含まれており、単純に GPU 型番だけを横並びで比較すると、意図しない読み違いにつながる可能性があります。ここでは、そうした誤解を避けるために、MLPerf™ の結果を「どの GPU が速いか」ではなく、「どのような構成で、どの程度の学習・推論性能が得られているか」という観点で見ていきましょう。
学習性能比較(Training)
まず学習性能ですが、MLPerf v5.1※1(Training)の結果では、各タスクにおける「Latency(学習完了までの時間)」を比較できます。数値が小さいほど高速に学習できることを意味します。
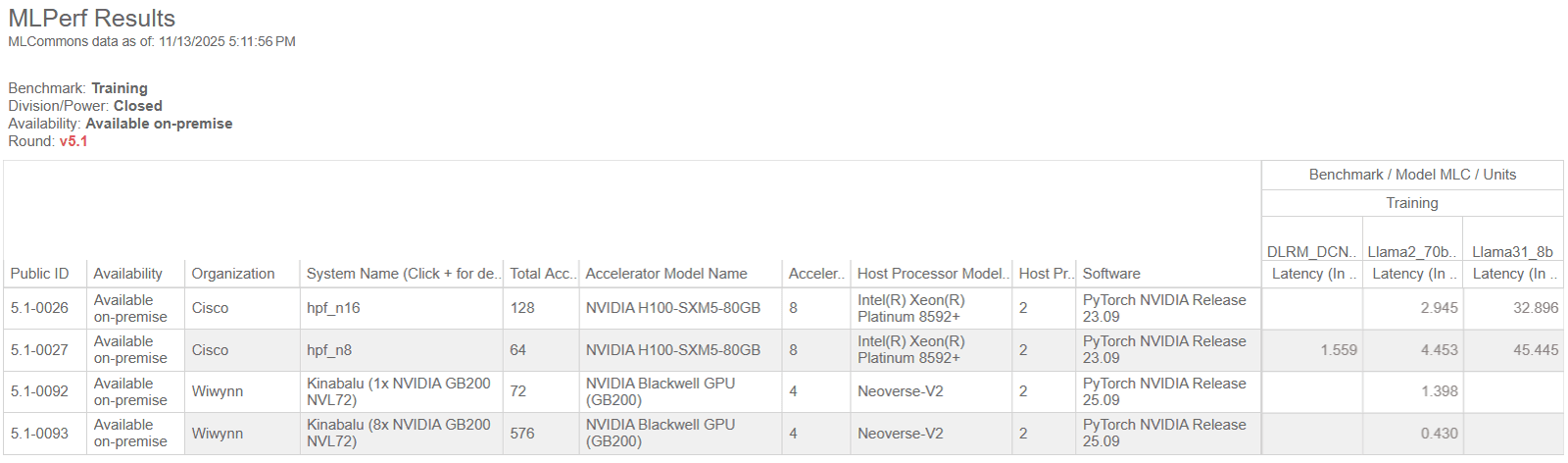
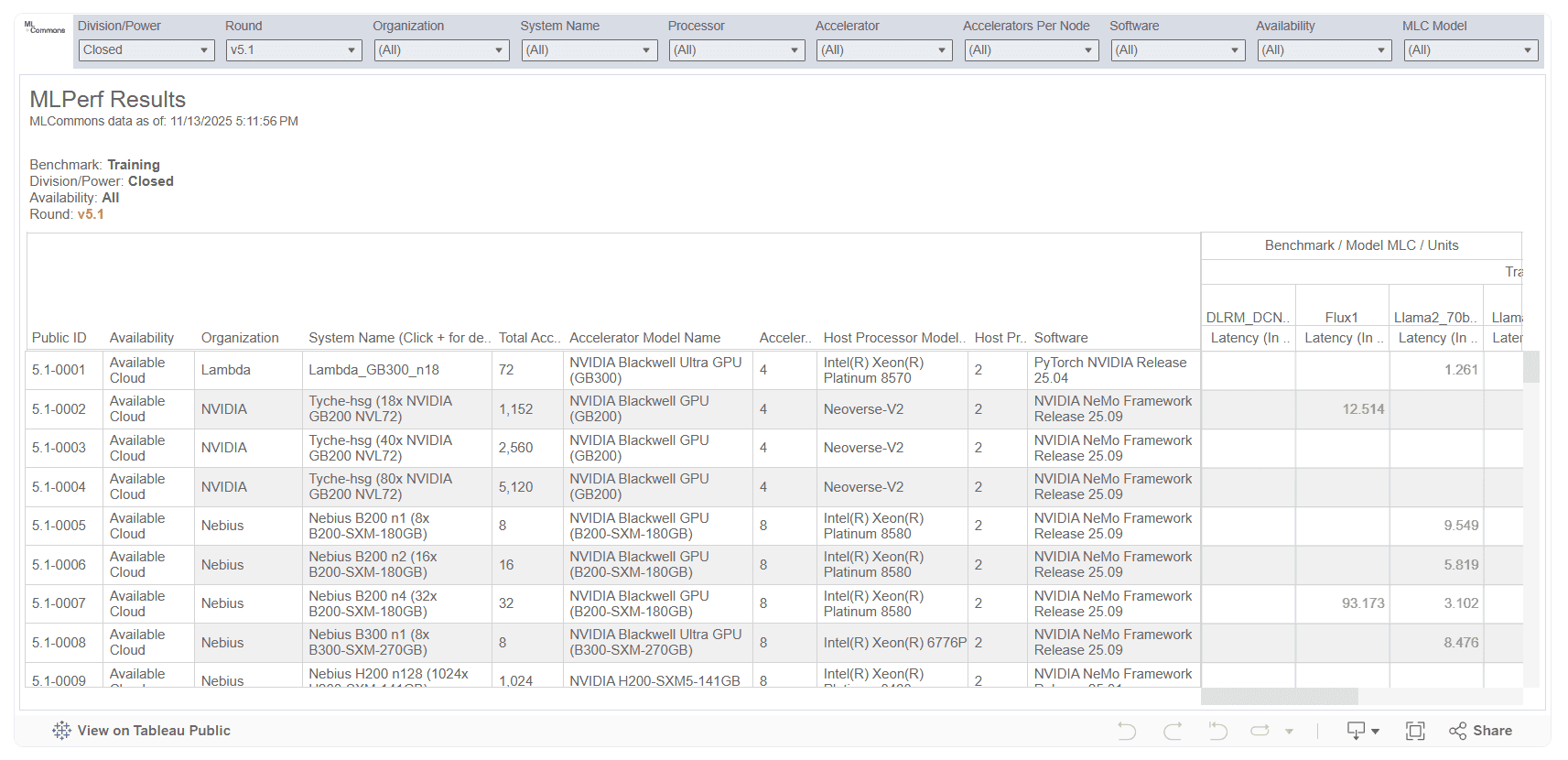
学習性能比較(参考:Benchmark MLPerf Training | MLCommons Version 2.0 Results利用画面を引用)
この表では、各タスクごとに「学習完了までの時間(Latency)」が示されており、数値が小さいほど、同じ学習タスクをより短時間で完了できたことを意味します。ここでは例として、Llama2 の列に注目します。Llama2 列を縦に見ていくと、GB200 NVL72 を用いた構成の行では、H100 を用いた構成の行と比べて、Latency が小さい値になっている例が確認できます。これにより、少なくとも表に含まれている範囲では、GB200 NVL72 構成が学習タスクをより短時間で完了しているケースがあることが分かります。
ただし、この差は GPU 型番単体の性能差を示しているわけではありません。同じ列の中でも、各行を見比べると、総 GPU 数(Total Accelerators)やノード数、構成規模が異なる投稿が含まれていることが分かります。学習性能の数値は、これらの構成条件やインターコネクト、ソフトウェア最適化の影響を受けた結果として表れています。そのため、学習性能をより厳密に比較する場合には、Llama2 列の中から、総 GPU 数や構成条件が近い行同士に注目し、Latency がどのように変化しているかを見ることで、構成ごとの傾向を推定していくことになります。
※1 MLPerf™はバージョン(今回であればv5.1)ごとに評価対象モデルや精度条件、実装ルールが変更されます。異なるバージョン間の数値を直接比較することは公式には推奨されておらず、最終的な判断には最新バージョンの結果や実環境での検証をご利用ください。
推論性能比較(Inference)
次に推論性能についてMLPerf v5.1(Inference: Datacenter)の結果では、Llama2-70bのタスクでTokens/s(推論スループット)を比較できます。
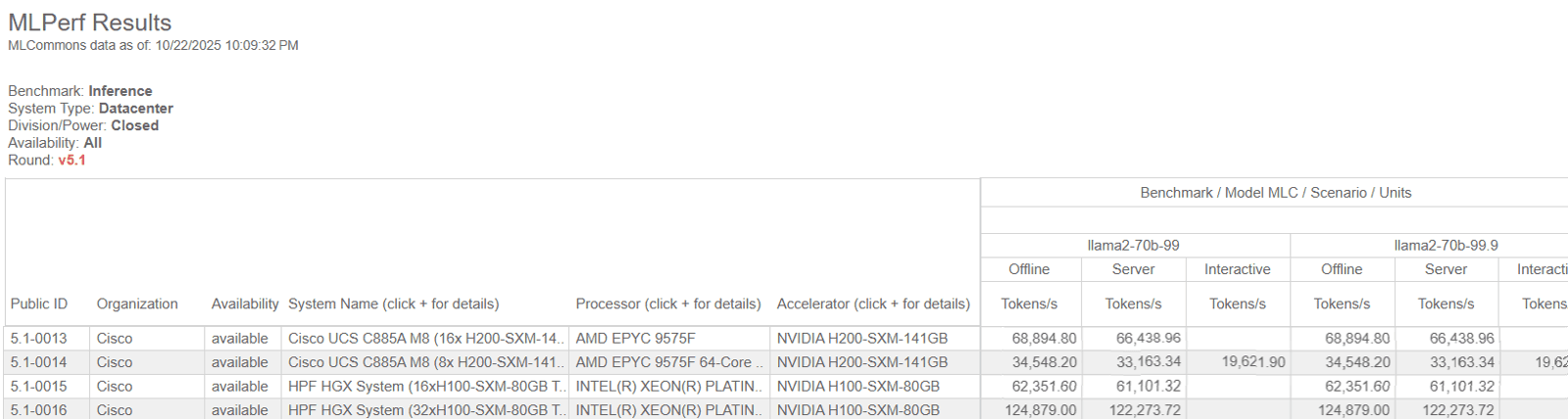
推論性能比較(参考:Benchmark MLPerf Inference: Datacenter |MLCommons V5.1利用画面を引用)
この表では、左側に提出されたシステム名が並び、右側に Llama2-70B に対する推論スループット(Tokens/s)が、精度条件(llama2-70b-99 / 99.9)および測定シナリオ(Offline / Server / Interactive)ごとに整理されています。
ここでは読み解きの一例として、「llama2-70b-99」の Offline シナリオに対応する列に注目します。この列を見ることで、同一の精度条件・同一の測定条件下で、各構成がどの程度の推論スループットを出しているかを横並びで確認できます。該当する行を見ると、H200 を用いた構成や H100 を用いた構成が並んでいますが、それぞれの行には GPU 台数(例:8基、16基、32基)やサーバー構成が異なる投稿が含まれています。
例えば GPU 台数が多い構成では Tokens/s の値が大きくなっていることが確認できますが、これは GPU 型番の違いによるものではなく、構成規模が反映された結果です。このように、GPU単体性能ではなく構成規模の違いによることを整理して読み解く必要があるでしょう。

AI / IoT、デジタルツイン用途に適したGPUサーバーを設計・構築。さらにデータセンター・ネットワークなど、GPU運用に必要なシステムをワンストップで提供可能。
MLPerf™を活用した実践的GPU選定フロー
MLPerf™のベンチマーク結果は、GPUを比較する際の参考として非常に有用ですが、あくまで“判断材料のひとつ”に過ぎません。実際に自社に最適なGPUを選ぶには、まず自分たちのAIワークロード(実際に動かす処理内容)を正しく把握する必要があります。以下では、選定のための基本的な3ステップをわかりやすく解説します。
ステップ1:ワークロード分析(活用目的/モデル規模/重視する性能指標)
最初に整理すべきなのは、今回の目的が「学習(Training)」中心か「推論(Inference)」中心かです(用語の定義は前節参照)。
この前提によって、重視すべき指標(例:学習完了までの時間/応答遅延/スループット)や、必要な構成が大きく変わります。
次に、扱うモデルの規模です。
「7B」「70B」「405B」などの数字は パラメータ数(モデルの大きさ) を表し、Bは“Billion(10億)”の意味です。モデルが大きいほど必要なGPUのメモリ(VRAM)や帯域幅が増えるため、候補となるGPUが変わります。
さらに、重視する性能指標も用途によって異なります。
- Latency(レイテンシ):1つのリクエストに対して、どれだけ速く応答できるかという“待ち時間”の指標
- Throughput(スループット):1秒間に何件の推論処理をこなせるかという“処理量”の指標
例えば、チャットボットや顧客対応システムのように即時応答が重要なサービスでは、Latencyの短さが最優先となります。一方、バッチ処理やレポート生成のように大量の推論を効率的に回したい用途では、Throughputの高さが全体のコスト効率を左右するでしょう。
2:MLPerf™による性能比較(Training性能/Inference性能/実測値の傾向)
MLCommons™の公式サイトでは、「Inference: Datacenter」や「Training」など、用途別に詳細なベンチマーク結果が公開されています。GPU名で絞り込み、自社で想定しているモデルに近いワークロードのスコアを確認することで、実環境に近い性能を把握できます。
特に、結果テーブルの「Available(商用導入可能な構成)」に分類されている構成を基準にすることで、導入後のギャップを抑えた現実的な見積もりが可能になります。
MLPerf™の結果の見方
1.MLCommonsの公式HPにアクセスします。
2.BenchMarkから結果を見たいベンチマークを選択します(例:nference: Datacenter)

参照するベンチマーク(Inference: Datacenter)を選択(Benchmark Work | Benchmarks MLCommons利用画面を引用)
3.結果ページ上部のフィルタでAccelerator(GPU)を選択します(例:NVIDIA H100やH200を選択)。
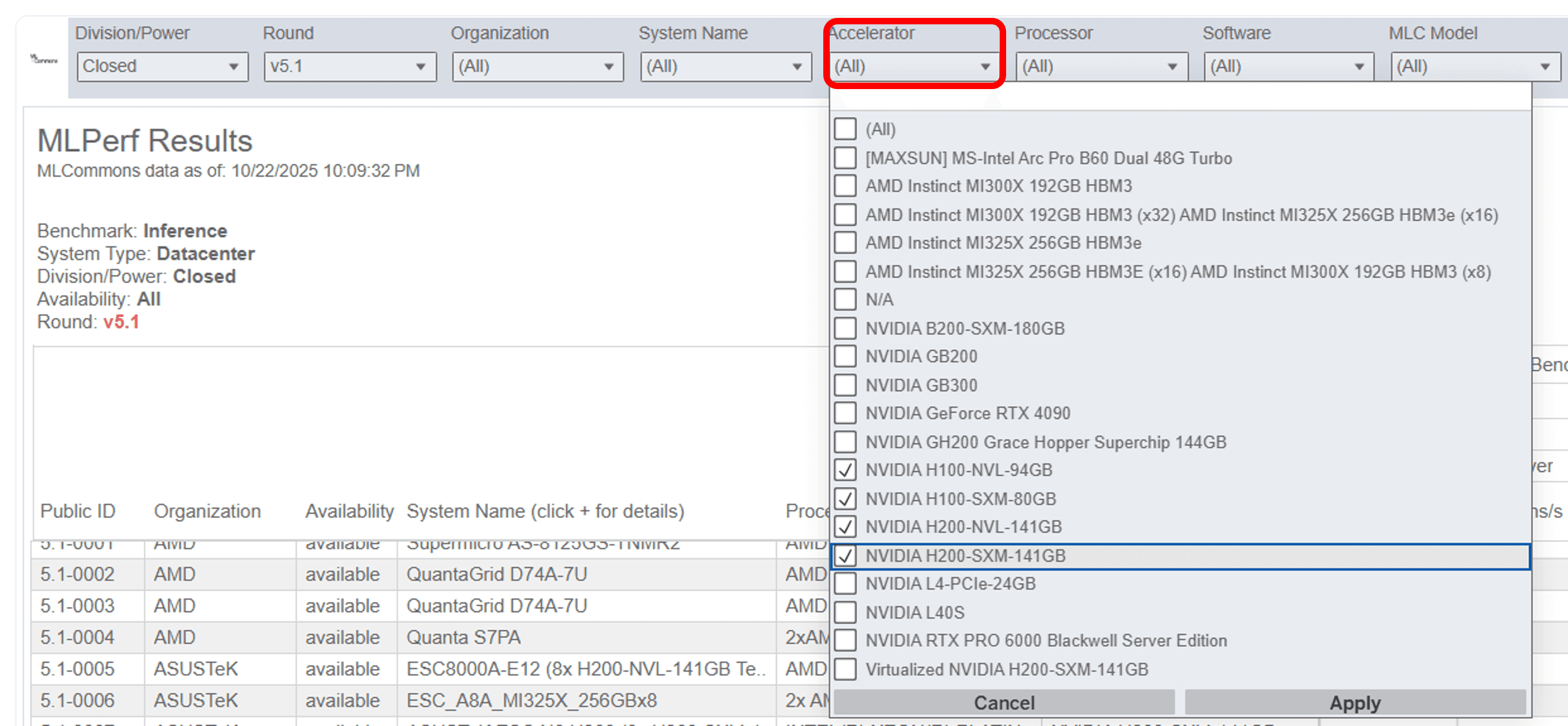
GPU型番の指定(複数選択可)(Benchmark Work | Benchmarks MLCommons利用画面を引用)
4.自社用途に用いるモデルを選択します(例:Llama2-70b)。
モデルの選択 (Benchmark Work | Benchmarks MLCommons利用画面を引用)
5.Availabilityで「Available(購入またはクラウドでレンタル可能な構成)」に絞り、導入可能な構成のスコアを確認します。

「Availability」で“市販・提供可能な構成”に絞る (Benchmark Work | Benchmarks MLCommons利用画面を引用)
このようにMLPerf™は自社の要件に合う環境を簡単に選定し、スペックだけでは見えない“実運用の性能”を把握することが可能です。
ステップ3:用途別の最適GPU選択(業務要件/コスト構造/運用性)
最後に、候補となるGPUを 実際の業務要件に基づいて最終的に絞り込みます。この段階では、性能だけで判断するのではなく、調達コスト、消費電力、可用性、保守性など、継続的な運用に直結する要素を含めて総合的に評価することが重要です。想定しているワークロードや提供形態によって、重視すべきポイントは異なります。
必要とされるのが瞬間的な性能なのか、安定したスループットなのか、あるいは電力効率や稼働率なのかを整理したうえで、単一GPUで完結させる構成か、複数GPUを前提とする構成かといった設計判断もこの段階で行います。
GPUのスペック比較に終始するのではなく、どの構成であれば、必要な性能を過不足なく、かつ無理のない運用コストで継続的に提供できるかという視点で判断することが、導入後のギャップや想定外のコスト増を防ぐための重要なポイントとなるでしょう。
まとめ
本記事では、カタログスペックでは把握しきれないGPUの“実効性能”を、MLPerf™のデータを軸に解説しました。AIインフラの最適化は、もはや理論値だけでは判断できません。実際のワークロードに近いMLPerf™を基準にすることで、導入後の性能ギャップを防ぎ、投資対効果を確実に高めることができます。また、ワークロード分析、MLPerf™による客観的な性能確認、そしてGPU世代ごとの役割理解という3つの視点を押さえておけば、自社の用途に最適なGPU構成を具体的に描けるようになります。AI活用が高度化する今、この一連のプロセスは、企業のAI基盤設計においてより重要な意味を持つようになっています。
NTTPCでは、NVIDIA認定エリートパートナーとして、H200やB200を含む最新GPUプラットフォームの提供に加え、PoC段階の技術検証から、ネットワーク・ストレージを含む基盤構築までを一貫して支援しています。GPU選定に迷われている企業様や、自社に最適な構成を検討したい方は、お気軽にご相談ください。
AI / IoT、デジタルツイン用途に適したGPUサーバーを設計・構築。さらにデータセンター・ネットワークなど、GPU運用に必要なシステムをワンストップで提供可能。
※「MLperf」「mlcommons」はMLCommons Associationの商標または登録商標です。
※「Google」はGoogle LLCの商標または登録商標です。
※「NVIDIA」「NVIDIA H100」「NVIDIA H200」「NVIDIA B200」はNVIDIA Corporationの商標または登録商標です。
※「Meta」「Llama」はmeta platforms, inc.の商標または登録商標です。
※「Intel」はIntel Corporationの商標または登録商標です。









