
※この記事はLedge.aiに掲載された記事です。
すっかり社会に浸透した生成AIだが、企業での活用はまだ十分に進んでいるとは言い難い。個人利用は急速に拡大する一方で、機密情報の取り扱いや外部LLMへの依存が大きな障壁となっている。生成AIをビジネスに実装する際は、データ保護とサービス独立性を確保する手段として、社内に閉じたローカル環境での基盤構築・運用は不可欠といえるだろう。
さらに、高いパフォーマンスが求められる生成AI基盤の選択肢として、複数のGPUサーバーを協調動作させる「GPUクラスタ」が挙げられる。GPUクラスタはいかにして企業の生産性向上に貢献できるのか、また、セキュリティと独立性を確保したGPUクラスタを導入する場合、企業はどのような点に気を配る必要があるのだろうか。
『GPUクラスタ×生成AI ―13のポイントで実現する次世代基盤とビジュアライゼーション実践ガイド』の著者であり、NTTPCコミュニケーションズ株式会社(以下、NTTPC)でGPUエンジニアとして活躍する大野泰弘氏に、生成AI基盤構築のポイントについて話を伺った。

【書籍出版】GPUクラスタ×生成AI ―13のポイントで実現する次世代基盤とビジュアライゼーション実践ガイド
※インタビューは2025年10月9日に行われた。本記事はインタビュー時の情報に基づく。

企業が生成AIを活用する際に重要なのは「データの扱い」と「独立性」
――日本企業における生成AI活用の現状について、どのようにご覧になっていますか。
大野氏 個人でのChatGPT等クラウド型LLMの利用率はかなり高まっていると感じます。ただ、企業として使う場合は話が違ってきます。多様なビジネスニーズに対応できるよう、企業内情報や顧客情報を学習させたカスタマイズLLMを利用している企業は未だ多くないのが現状です。
――なぜ個人では積極的に使用しているのに、企業では利用が進んでいないのでしょうか。
大野氏 主に企業のセキュリティルールが原因です。非公開情報をパブリックにアップロードすることへの懸念から、多くの企業が社内導入に踏み切れずにいるのではないかと見ています。
――非公開情報の取り扱いに関する懸念点をもう少し詳しく教えてください。
大野氏 一般的な情報であれば、外部APIやクラウド型LLMサービスを使っても問題ないでしょう。しかし、企業の重要な情報をクラウド型LLMにアップロードする場合は注意が必要です。
クラウド型LLMサービスであっても、エンタープライズ契約では「アップしたデータを学習に使わない」と明記されているケースも多くありますが、それが本当に守られているか確認する手段はありません。最終的にはAIサービスを提供している企業倫理に委ねるしかないのです。そのような状況では、たとえエンタープライズ契約であっても企業が慎重になるのは当然です。もし、重要情報をAIで扱うなら、外部に情報が出ないローカルなオンプレミス環境を構築するのがもっとも安全です。
もう一つの重要なポイントは「独立性」です。たとえば、GPT-4oがGPT-5にアップデートされ、出力の性質が変わってしまったケースがありました。企業のワークフローに生成AIを組み込んでいると、こうしたAPI挙動の変化がビジネスに大きな影響を与えます。さらにAPIに障害が発生すれば業務が停止してしまいます。
企業によっては、SlackやGitHubが落ちると仕事ができなくなってしまいますよね。それと同じことがAIにも起こり得ます。こうしたリスクを防ぐには、独立性を保ち、自社でAPIを運用することが重要です。
――将来のリスクに備える意味でもローカル環境が重要になるわけですね。
大野氏 はい。特に大企業は、社内ナレッジやパーソナルデータなど膨大な機密情報を保有していることが多いでしょうから、ローカル環境を整備すべきだと考えます。また、将来的にAIは石油や鉄鋼と同じく戦略物資に位置づけられる可能性もあります。なぜなら、APIを提供している企業がある国が、ある日突然「自国以外にAPIを使わせない」と言い出すと、業務が完全にストップしてしまうからです。そうした状況への対策として、国としての独立性を維持することも重要になるでしょう。


GPU製品・サービス
AI / IoT、デジタルツイン用途に適したGPUサーバーを設計・構築。さらにデータセンター・ネットワークなど、GPU運用に必要なシステムをワンストップで提供可能。
複数のGPUサーバーを連携させる「GPUクラスタ」が生成AI活用の鍵を握る
――NTTPCでは、企業が生成AIを活用する際のインフラとして「GPUクラスタ」を提供しています。あらためてGPUクラスタの概要について教えてください。
大野氏 複数のGPUサーバーを連携させ、処理を高速化したものがGPUクラスタです。クラスタを構成することで、システムの可用性を上げることができます。万が一システムが停止しても事業が止まらないよう、複数台でクラスタを組むことで安定した基盤を構築するのです。
――GPUクラスタを構築する上で押さえておくべきポイントはありますか。
大野氏 パラメータ数の大きな生成AIモデルを扱う場合、いかに多くのGPUメモリを利用できるかが応答速度に直結します。一つのサーバー内に搭載できるGPU枚数は多くても8~10GPU程度ですが、数十~数百台のサーバーを連結させて動作させることで、さらに多くのGPUメモリ容量を確保できます。これにより、学習スピードを上げたり、より大きなモデルを作成できるようになります。
その際、サーバー同士を高速で接続する「インターコネクト」が重要になります。インターコネクトが遅いと、どんなに高性能なGPUを使っていても全体の処理速度が落ちてしまうからです。いわば二人三脚のようなもので、遅い方に全体のスピードが引きずられるのです。ですから、GPUだけでなく通信部分にも適切な投資をすることが重要です。
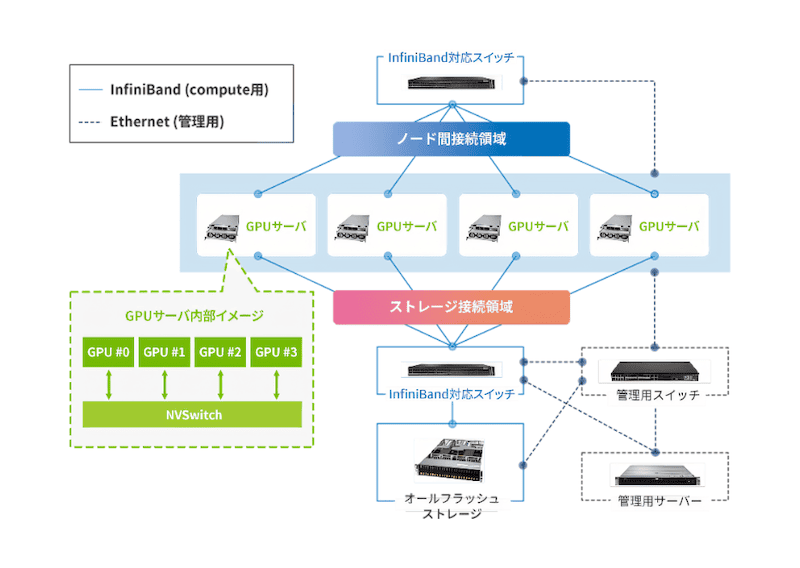
また、同時リクエスト数に応じてクラスタのサイズを調整することも必要です。業務にAIを組み込むと、100件、200件といった同時リクエストが発生することもあるので、それに合わせてクラスタを拡張しなければなりません。
――インターコネクトについては認識されていない企業が多いのでしょうか。
大野氏 そうですね。多くの方は「GPUを買ってつなげば動くのでは」と考えがちです。しかし、適切な設定をしなければ、たとえば400Gbpsや800Gbpsといった高速なイーサーネットで接続しても、通信が輻輳して期待したパフォーマンスが出ないことがあります。後から「ここに投資しておけばよかった」と、多くの人が後悔するのがインターコネクトなのです。
インターコネクトの設計で、ネットワークの速度と安定性が大きく変わってくる
――インターコネクトについて、もう少し詳しく教えてください。
大野氏 端的に言えば、インターコネクトはGPU同士をつなぐ高速なネットワークです。なぜインターコネクトが必要なのかというと、GPUで言語学習などのトレーニングを行う場合、AllReduceという計算方式を使います。この仕組みでは、各GPUにタスクを割り当てて、計算結果を一度集めて再分配するというプロセスを繰り返します。
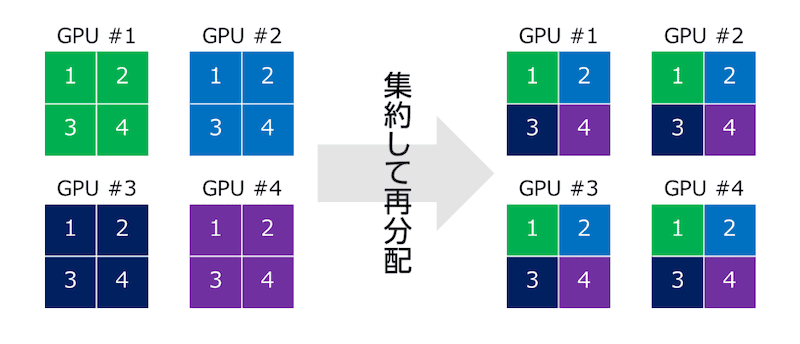
この「集約」と「再分配」の時間が通信時間となり、その間はGPUの稼働率が落ちてしまうのです。低速のネットワークを使うと、GPUの稼働率が5%~10%程度まで下がってしまい、せっかくのGPUのリソースを活かせません。そのため、インターコネクト設計がGPUクラスタの性能を左右するのです。
――適切に設計されたインターコネクトとそうでないものでは、どの程度の差が出るのでしょうか。
大野氏 インターコネクトのパフォーマンスチューニングをしない場合は稼働率が80%程度ですが、適切にチューニングすることで90%~95%まで向上させられます。生成AIの進化は非常に速く、少しでも早く学習を終えてトライ&エラーを繰り返せる環境を整えることが重要です。
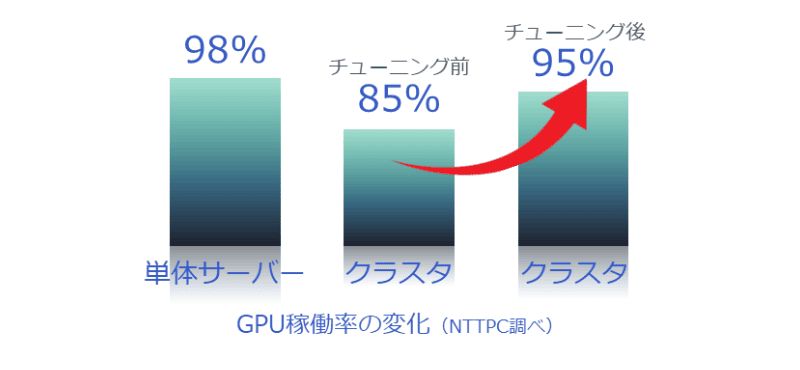
――長期間かけて何度も繰り返す作業となると、最終的には大きな差につながりそうですね。
大野氏 はい。それから、速度と同じくらい重要になるのが安定性です。場合によっては1ヶ月間ずっとAIの学習を回し続けるようなこともあるでしょう。その際、途中でエラーが発生すると1か月間の学習がすべてリセットされてしまいます。チェックポイントを設けて定期的に保存は行いますが、仮に1時間分の計算が無駄になるだけでも大きな損失です。
――ネットワークの安定性を確保するためのポイントはありますか?
大野氏 弊社では、設計段階で光ケーブルの損失を計算したり、トランシーバーに負荷をかけてストレステストを行っています。軽い検証でスタートしてしまうと、本番運用時に問題が発生することがあります。単にベンチマークソフトを回すだけでなく、複数のパラメータで検証し、厳しい条件で試すことが大切です。
――大野さんは国内有数の大規模プロジェクトを率いたご経験を豊富にお持ちです。そのご経験から、GPUクラスタの設計思想についてお聞かせください。
大野氏 もっとも重要なのは、お客さまのユースケースに合わせた設計をすることです。たとえば、学習パターンによっては高いスループットが不要な場合もあるので、過剰な設計にならないようネットワークを組むことが大切になります。お客さまもビジネスとしてサーバーに投資されるわけですから、投資した以上の利益を上げないといけません。そのためにも、コストを削減することが我々ベンダーの大切な役割になるのです。
また、ネットワークの設定だけでなく、サーバー内部のLinuxカーネルの設定なども適切に行い、通信のスピードを最適化することが求められます。仮に10台や20台のGPUサーバーでクラスタを構築し、稼働率が10~20%向上すれば、それだけでサーバー1~2台分の効果が得られることになりますよね。そういった形で、お客さまの資産を最大限に活用できる形でクラスタを組むことを心がけています。
――そのあたりは、豊富なご経験を持つ大野さんやNTTPCならではですね。
大野氏 はい。自前で構築したものの、思ったようなパフォーマンスが出ないと感じている方は多いと思います。実はドライバーのファームウェアのバージョンをそろえるだけでも、大きく変わることがあるんですよ。

――データの学習やファインチューニングなど、AIのライフサイクル全体を管理する「AIファクトリー」が注目を集めています。AIファクトリーの構築は、技術に詳しくない一般企業や中小企業でも可能なのでしょうか。
大野氏 専門知識を持った人材がいれば自社で構築することも可能でしょう。しかし、専門家を採用したり育成したりするのは簡単ではありません。現実的には、弊社のような専門企業にAIファクトリーの設計から構築、導入までご依頼いただくのが近道です。その方が、お客さまも自社のビジネスに集中できます。
――AIファクトリーを導入し、生成AI活用を進めることで、企業はどのようなビジネス課題を解決できるでしょうか。
大野氏 一つは、社内の暗黙知の活用です。社内にはSlackなどでやりとりしてきた情報が蓄積されているはずです。これらをデータベース化し、AIで参照できるようにすれば、24時間365日質問に回答できるシステムが出来上がります。
他には、メール応答の自動化なども効果的です。たとえば、お客さまからの見積もり依頼メールに対して、不足している情報を自動的にAIで問い合わせることができれば、見積もり作成までの時間が短縮でき、お客さまへの対応が早くなるでしょう。
このように、企業のワークフローの中で定型化している業務をAIに任せることで、他の業務にリソースを集中できるようになるのです。
――自前のAI基盤を持つことが、企業に競争優位性にどうつながると考えますか。
大野氏 一つは、企業内のワークフローを安定的に提供できることです。熟練者が退職してしまっても、AIが知識を引き継ぐことで業務の連続性が確保できます。少子化が進む中で、特に重要になる要素でしょう。
二つ目は心理的安全性の向上です。AIは質問しても怒らず、いつでも相談に乗ってくれます。といっても、ChatGPTは一般的な知識はあっても、会社特有の情報は教えてくれないのであまり役立ちません。自社のAIなら、会社のことを教えてくれる「やさしい相談相手」が常に存在することになります。
三つ目はセキュリティの担保です。ローカルでAIを運用することで、新入社員などが「この情報をAIに入れても大丈夫か」と迷うことがなくなります。気兼ねなく質問できる環境が整うことで、問題解決のスピードが向上するでしょう。
GPUクラスタの導入実績と未来のユースケース
――NTTPCのGPUクラスタを導入した企業からは、どのような反響がありますか。
大野氏 弊社が構築したクラスタを運用されているお客さまからは、「非常に安定している」という評価をいただいています。また、「トラブルが発生した際の対応が非常に早い」というフィードバックもよくいただきます。弊社には約20名のエンジニアがおり、分担してトラブルシューティングを行うことで、迅速な対応が可能になっています。
――今後、GPUクラスタ構築がより求められる業界や領域はどこだとお考えですか。
大野氏 日本の製造業、特に自動車産業ではGPUクラスタの処理能力が不可欠になると考えています。たとえば、NVIDIA Omniverse™やNVIDIA Isaac Simなどを活用したデジタルツイン空間では、現実では不可能な実験を無限に行うことができます。実際の道路で事故データを収集するのは難しいですが、デジタルツイン上では様々な事故シナリオのシミュレーションが可能です。
Omniverse:NVIDIAが提供する仮想コラボレーションおよびリアルタイムシミュレーションのためのプラットフォーム
Isaac Sim:Omniverseを基盤するロボティクスシミュレーションプラットフォーム
また、産業ロボット分野でも、工場のラインをデジタルツイン上で作成し、テストを行った上で実際の環境に適用するといった活用方法が考えられます。無限に実験できる環境を持つことは、企業にとって大きな価値につながるはずです。
――様々な利用シーンがあるのですね。GPUクラスタの領域ではやはりNVIDIAの存在感が強いのでしょうか。
大野氏 はい。GPUクラスタのベストプラクティスとして、NVIDIAからは「NVIDIA DGX SuperPOD™」が公開されています。これは単なるハードウェアの集合ではなく、GPUコンピューティング、ストレージ、ネットワーキング、ソフトウェア、インフラ管理までまとまったフルスタックプラットフォームです。互換性の取れた構成と標準化されたモジュールにより、短い期間でシステムを立ち上げることができ、運用コスト・リスクを低減できます。弊社はNVIDIAエリートパートナーとして、DGX SuperPODの設計・構築・導入も手掛けています。
――今後、GPUクラスタの導入を検討している企業へアドバイスをお願いします。
大野氏 まずは、スモールスタートで始めることをおすすめします。弊社には設計から構築までの豊富なノウハウがありますので、ご相談いただければお客さまの状況に合わせてご希望に合わせたご提案をさせていただきます。


GPU製品・サービス
AI / IoT、デジタルツイン用途に適したGPUサーバーを設計・構築。さらにデータセンター・ネットワークなど、GPU運用に必要なシステムをワンストップで提供可能。
※ChatGPTは、OpenAI社の登録商標または商標です。
※Slackは、Slack Technologies, Inc.の登録商標あるいは商標です。
※GitHub は、GitHub Inc.の商標または登録商標です。
※NVIDIA、NVIDIA Omniverse、NVIDIA DGX SuperPODは、米国およびその他の国におけるNVIDIA Corporationの商標または登録商標です。




