合計4000基以上のGPUを構築したエンジニアが語る 最新AIエージェントの現在地と LLM/AI基盤の“コスパを最大化”するポイント

生成AIと多様な言語モデル(LLMやSLM)の台頭により、多くの企業でAIの実装が加速度的に進んでいる。2025年は「AIエージェント元年」とも称され、AIの活用がビジネスに与えるインパクトはますます大きくなり、企業のDX推進の中核を担う存在へと進化しつつある。
本記事では、4000基を超えるGPU(Graphics Processing Unit)の設計・構築経験を持つチームの知見を基に、LLM/AI基盤のコストパフォーマンスを最大化するポイントを探る。
LLM/AI基盤構築の現場で直面する課題や、Agentic RAG等との連携による新たな可能性も踏まえながら、効果的なAIインフラ投資の在り方を解説していく。
1. AIエージェントとは?従来の生成AIとの違いをわかりやすく整理
Q1. まず、最近話題のAIエージェントとはどんな存在なのでしょうか?従来の生成AIと比べてどう違うのか、分かりやすく教えていただけますか?
A(エンジニアチーム):
はい、AIエージェントは、一言でいえば「自律的に行動できるAI」です。従来の生成AI、例えばChatGPTは、与えられた質問に対して一度きりの回答を返す“一問一答型”が中心でしたよね。
でもAIエージェントは違います。目標を設定してあげると、自分で手順を考え、複数のタスクを同時並行で処理し、外部システムやAPIとも連携します。ですから、ただ文章を返すだけでなく、業務を任せられる労働力のように振る舞えるんです。
(例を挙げれば…)従来の生成AIが「アシスタント」なら、AIエージェントは「プロジェクトメンバー」。人が細かく進行管理をしなくても、ゴールに向けて自律的に動けるのが特徴です。
| 項目 | AIエージェント | 従来の生成AI |
|---|---|---|
| 目的指向性 | 予め設定された目標に向けて 自律的にタスクを遂行する。 |
与えられたプロンプトに応答する形式(1往復で完結)。 |
| 複雑なタスク管理 | 複数のタスクを同時並行で管理し、 結果を統合して次のステップを決定する。 |
単一のプロンプトに対する応答にフォーカス |
| 連携能力 | 他のシステムやAPIと連携し、 外部データの取得や操作が可能。 |
外部システムやデータ連携は限定的で、インタラクションの範囲が狭い。 |
| ユーザー体験 | 業務を任せられる労働力のように振る舞う 人間がゴールを伝えれば、途中の手順を考えて実行する |
あくまでもコンテンツ「生成」のアシスタント 人間が進行管理をする必要がある |
2. 押さえておきたいAIエージェントの能力と限界
Q2. なるほど、ではそのAIエージェントの能力と限界について教えてください。
A(エンジニアチーム):
はい、エージェントの能力は大きく3つです。
| タスク自動化 | 書類整理、データ入力、顧客対応などの反復的な業務を効率的に処理。 |
| 意思決定支援 | 大量のデータを迅速に分析し、意思決定に必要なインサイトを提供。 |
| 創造的作業 | 文章や画像・デザインを生成し、斬新な企画や アイデアを提案・補完・改善する。 |
ただし課題もあります。例えば医療診断や法律解釈のように専門的知識が必須の領域では精度が不十分です。また、複雑な文脈理解や曖昧な情報解釈も苦手。さらに偏ったデータ学習による倫理リスクもあります。
| 専門性が必要な判断 | 専門性の高い自社業務や研究開発部門、医療診断や法律の解釈など、専門知識が前提となる領域では正確性が不十分な場合がある。 |
| コンテキストの理解不足 | 複雑な文脈や曖昧な情報の解釈が苦手で、誤ったアウトプットを生成する可能性がある。 |
| セキュリティ 倫理的問題 |
門外不出の、顧客情報や研究/開発データの取り扱い。 偏ったデータや不適切な使用による倫理的リスク。 |
ですから、高品質データの提供、タスクの明確化、人との協調が必須です。完全にAI任せにするのではなく、人間が監視・補助を加えながら一緒に使っていく、というのが当面のベストプラクティスですね。
AIエージェントの能力を最大限に引き出すためには
AIエージェントの能力を最大化するには、以下のポイントを押さえる必要があります
- 高品質なデータの提供: AIエージェントは学習データに依存しているため、偏りのない高品質なデータを準備することが重要です。
- タスクの明確化: 具体的なゴールや条件を設定することで、AIエージェントのパフォーマンスを最適化することができます。
- 人との協調: AIエージェントにすべてを任せるのではなく、人間の監視や補助を組み合わせることで、リスクを軽減し精度を向上させます。
エンジニアチームからの”ひとこと”
AIエージェントは、まだ完全に自律できる状態ではありません。ワークフローをエンドツーエンドで自動化しようとするだけでなく、新たな労働力・人材としてのAIエージェントを、従来の社員・パートナーに加えて協働させるワークフローが当面主流になるでしょう。
限られた人間の生産性を向上させようとするだけでなく、人間が携わるべきコア業務と、それ以外でAIエージェントが携わる業務を明確にして、ビジネスプロセスを再設計しましょう。
3. 自社にとって"実用的なAI"にするためのポイントとは?

Q3. 企業が“実用的なAI”を導入するために、どんなポイントを押さえるべきでしょうか?
A(エンジニアチーム):
ここが非常に重要なところで、まず、下記3点が大前提となります。
■ 自社にとって実用的なAIを開発する=(知っているはずの)自社業務プロセスを分解/再構築すること
■ AI開発の主役は、自社の業務プロセスを誰よりも深く知る「お客さま」自身であること。
■ 開発する「AI」と、自社競争力の源泉である「データ」の主権は、必ずお客さまが握ること。
以上を踏まえ、AIの価値を引き出すための最初のポイントは、「自社が持つ独自のデータ」を活用することです。汎用的なAIモデルを導入するだけでは、自社の特異な課題を解決することはできません。また、巨大な事前学習モデルをゼロから開発する必要はなく、既存のLLMやSLMをカスタマイズする方が現実的です。開発のステップを大きく分けると、以下3つになります。
| 自社データの整備 | 自社の業務データをクレンジングし、AIモデルに適した形で準備する。 |
| モデル選定 カスタマイズ |
LLMは汎用性が高いがコストも大。SLMは軽量で特化タスク向き。 両者を組み合わせるハイブリッド構成も有効。 |
| 運用知/暗黙知の実装 | 社員の経験や専門知識をモデルに反映する仕組みを構築する。 |
さらに導入後も、KPIを設定し、フィードバックループで継続改善することが不可欠です。AIは導入して終わりではなく、「運用して育てていくもの」と考えるべきでしょう。
3-1. 適切なAIモデルの選定
LLM(大規模言語モデル)やSLM(小規模言語モデル)など、AIモデルにはさまざまな種類があります。それぞれの特徴を理解し、適切なモデルを選定することが重要です。
• LLM: 大量のデータを基にした汎用性の高いモデル。ただし、計算コストが高い。
• SLM: 特定用途向けに最適化された軽量モデル。リソースが限られている場合に有効。
• ハイブリッドアプローチ: 汎用的なLLMを基盤としつつ、特定タスクにはSLMを用いる柔軟な構成。
3-2. 新たな技術の活用による可能性の拡大
AIの効果を最大化するには、最新の技術を積極的に取り入れることが有効です。特に以下の技術が注目されています。
• RAG (Retrieval Augmented Generation): 生成AI(LLM)に検索エンジンのような外部知識を組み合わせる仕組み。
• LoRA (Low-Rank Adaptation): 大規模なAIモデルをファインチューニングする際に、モデル全体ではなく一部パラメータを学習させることで効率的に調整する手法。
• MCP (Model Context Protocol) : AIモデルやツール同士が標準化された方法でやり取りするためのプロトコル。AI界の USB-C のような存在。
3-3. 導入後の効果測定と継続的改善
AIは導入して終わりではなく、運用後の効果測定と改善が必要です。
• KPI設定: AIが達成すべき具体的な目標を定める(例: 作業効率の向上率、コスト削減額)。
• フィードバックループ: 運用データを活用し、モデルの精度を継続的に向上させる仕組みを構築する。
• 現場との連携: 現場の意見を反映し、AIが実際の業務に適合しているかを確認する。
3-4. 実用性を重視した運用
最後に、AIを実用的にするためには、技術の選択だけでなく運用体制も整える必要があります。社内のエンジニアや業務部門との密な連携を通じて、AIを「使いやすい」「成果が見える」形に仕上げ、ユーザー体験を最適化しましょう。
エンジニアチームからの”ひとこと”
カギは「自社が持つ独自データと運用知」をループさせ、自社が学習し続けるための基盤を最優先で構築することです。学習し続ける基盤に投資することこそが、企業の競争優位性を高め、持続的な成長を可能にします。
4. AI同士が連携する時代の展望~マルチAIエージェントとは?

Q4. 最近話題の「マルチAIエージェント」についても教えてください。AI同士が連携する未来はどんなイメージですか?
A(エンジニアチーム):
はい、マルチAIエージェントとは、複数のAIが協力し合う仕組みです。例えば、自然言語処理を得意とするエージェントと、画像認識に特化したエージェントが一緒に動くと、リアルタイム映像分析や多言語レポート作成といった複雑なタスクも実行可能になります。メリットは大きく分けると下記の3点になります。
| タスク分割・並列処理 | 大きな問題を各分野の専門エージェントに任せることで、単体では不可能だった高度なプロジェクト管理や創造的な作業の自動化が可能になる。 |
| 多角的な意思決定や 相互検証 |
異なる視点を持つエージェント同士の「議論」や「比較検討」により、精度や信頼性の向上、バイアスの軽減が可能になります |
| 継続学習と進化 | 各エージェントがデータを共有し、相互学習することで、システム全体が進化する仕組みが構築されます。また、各エージェントが各役割に関係する情報だけを保持・処理するため、大量のデータも扱いやすくなります。結果、メモリやトークン長の制約を回避しやすくなります。 |
一方で課題も存在します。例えば、エージェント間の連携が複雑化することで通信や同期の問題が発生する可能性があります。またセキュリティ面では、複数のAIがデータを共有することで情報漏洩や不正利用のリスクが高まります。さらに、システム全体を構築・運用するためのコストや技術的ハードルも重要な検討事項となります。
エンジニアチームからの”ひとこと”
■ AI開発の主役は、自社の業務プロセスを誰よりも深く知る「お客さま」自身であること。
■ 開発する「AI」と、自社競争力の源泉である「データ」の主権は、必ずお客さまが握ること。
先に述べた上記2つの前提は、自社のコアコンピタンス領域におけるAI開発において、他には任せられないお客さまの本業部分が肝であることの裏返しです。
では、AIが稼働する基盤(AI基盤)の設計から必要なハードウェアの選定・構築も、お客さま自身で対応可能でしょうか?また、セキュリティを確保する仕組みに加え、各種コンプライアンスへの対応、構築後の運用も大きなハードルではありませんか?果たして投資に見合う価値が得られるのか・・・。
AI基盤の企画段階では、運用フェーズまでを見据えたコストコントロールが最重要ポイントとなります。
5. AIエージェントを成功に導く、コスト意識の高いAI基盤とは

Q5. では、コスト意識の高いAI基盤を設計するには、どんな工夫が必要でしょうか?
A(エンジニアチーム):
私たちが最も強調したいのは、お客さまには本業(コア業務・AIモデル開発・データ価値創出等)へ集中して頂きたい、ということです。AI基盤構築の目的は“基盤をつくること”ではありません。
ゴールはただ一つ、お客さま事業の成長につながるAI活用です。
だからこそ、ビジネスにおける競争力の源泉となる、モデルやデータ活用の設計等はお客さま側で主導、インフラ構築はベストプラクティスを持つ専門ベンダーに任せる、という役割分担が良いと考えています。もちろん、AI基盤に必要なハードウェアの選定・構築が、自社のコアコンピタンス領域である場合を除きます。しかしほとんどのお客さまにとって、インフラ構築部分は自社の強み領域にならないはずです。
AI活用の本丸は、お客さま独自の知とデータから価値を生み続けること。つまり、自社が持つ「独自データと運用知/暗黙知」をループさせ、自社が学習し続けられる運用体制をいち早く築く部分にこそ、自社のスキルとリソースを最大限に投入頂きたい、と考えています。そのためには、AI基盤の構築に不足しているスキルやリソースを専門ベンダーにアウトソースして補い、ムダなコストや工程の遅れを避け、AI活用フェーズへの移行を最短化することが王道だと考えています。
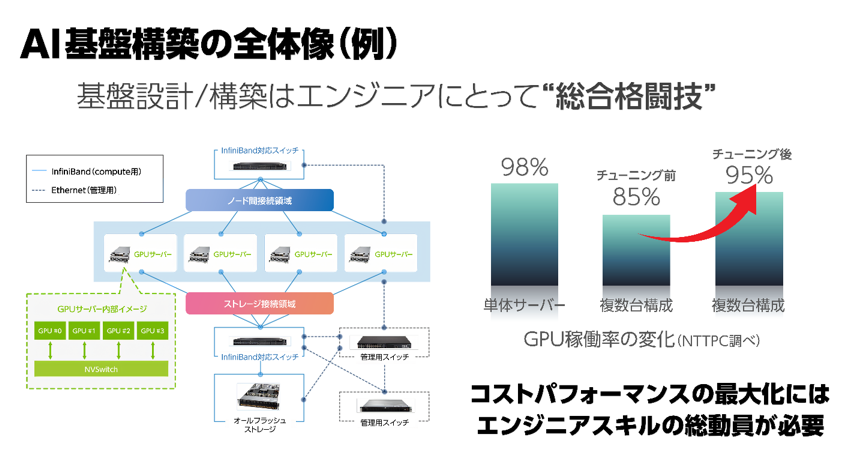
もし、 せっかく構築したAI基盤が、期待したパフォーマンスを出せなかったら?
あるいは、利用しているクラウド事業者の料金体系・APIの急な仕様変更や突然の機能提供終了、ユーザー数が増えた場合の拡張性/UX維持・・・・など、運用フェーズにおける不安のタネは尽きません。合計4000基以上のGPUを構築した経験から、この不安は決して大規模なAI基盤に限った話ではなく、複数のGPUを搭載したワークステーション1台の規模から共通する課題です。
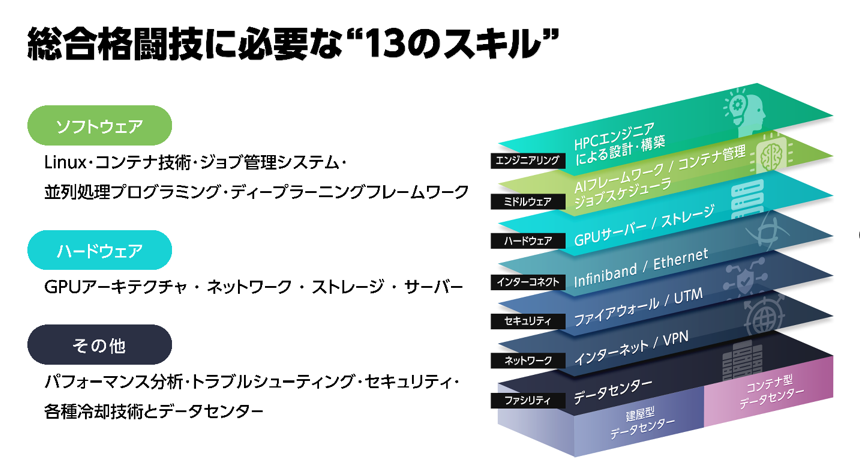
AI基盤は、例えばGPUの性能差、サーバーの性能差、ネットワーク機器の性能差などの単体で評価することはできません。それらを含むすべてが緊密に連携・最適化されて初めて、狙ったパフォーマンスを発揮することができます。運用フェーズをも包含した「フルスタック」エンジニアリングによってこそ、最大の投資対効果が実現すると言えるでしょう。以上を踏まえると、下記の3点がAI基盤のコストパフォーマンス最大化の肝となります。
■ 本業への集中:AI基盤構築のフルスタックエンジニアリングが、自社のコアコンピタンス領域か判断する。
■ TCOの安定化:運用フェーズにおける想定外の事象を限定化することで、隠れコストも最小に。
■ 利益の最大化:最速でAI活用フェーズに到達することによって、いち早く新たな価値創出を実現可能に。
繰り返しになりますが、カギは、自社が学習し続けるための基盤を「最速」で構築することです。そのポイントに投資することこそが、企業の競争優位性を効率よく高め、持続的な成長をいち早く可能にします。
6. AI導入における「オンプレミス」「プライベートクラウド」の潮流

Q6. 最後に、最近のAI基盤構築のトレンドについても教えてください。
A(エンジニアチーム):
はい。AI基盤の選択肢としては、NTTPC社の実績からも、昨年度から「オンプレミス」と「プライベートクラウド」が注目されています。
今年4月、Google社はGoogle Distributed Cloudにて、オンプレミスでGeminiを利用できる計画を発表しました。またOpenAIやAnthropicなどの主要AIベンダーはオンプレミスでの最新モデルの提供はしていませんが、OpenAIの場合は「gpt-oss-120B / 20B」というモデルをリリースし、ローカルあるいはオンプレミスでの実行が可能となっています。
そして同月、コンテナ管理ツールで有名なDocker社も、AIモデルのローカル実行機能「Docker Model Runner」を実装しました。これによって、SLMをコンテナに格納してオンプレミスにデプロイデプロイできるようになりましたね。
もちろん、様々な規模で社内のAI活用が進む中で、当初はいわゆるハイパースケーラーのサービスを使う形が多いでしょう。導入のハードルが低く、様々なAIモデルを利用できるためメリットは大きいと思います。ただし、機密情報を外部に持ち出せずデータ活用が進まない、各種コンプライアンスへの対応などの課題も多く聞こえます。こうした課題を解消し、プライベートな環境でAI活用を進める手段として、ワークステーション1台の規模から「オンプレミス」や「プライベートクラウド」が注目を集めているのだと認識しています。
重要なのは、AI基盤が自社の持つ「独自データと運用知/暗黙知」に接続できることです。開発する「AI」と、自社競争力の源泉である「データ」の主権をお客さまが握ったうえで、そのデータをいかに生かすかが、今後のAI活用の成否を左右することになるでしょう。
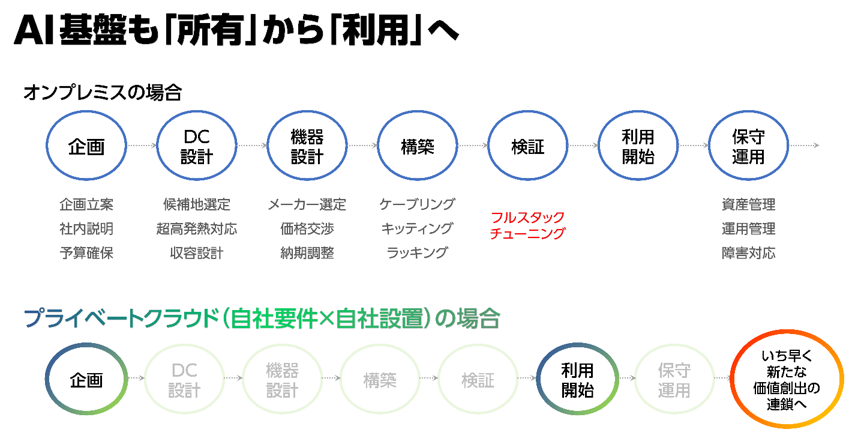
例えば、AI基盤の構築をオンプレミス型で考えている場合、GPUプライベートクラウドの活用も有効ではないでしょうか。
GPUプライベートクラウドは、自社専用に構築・管理されるGPUリソースのクラウド環境です。GPUプライベートクラウドを利用すれば、自社に最適化されたAI基盤を短期間で構築でき、運用管理に悩まされることなく自社の本業に集中することができます。
7.まとめ
Q7. それでは、ここまで伺ってきた内容を振り返って、最後に読者へ「AI基盤の導入で成功するためのアドバイス」をお願いします。
A(エンジニアチーム):
はい、それでは大きく3つにまとめます。
1. ビジネス差別化の源泉は社内にある
自社独自のデータおよび運用知/暗黙知こそが競争力の源泉。RAGや軽量モデルを組み合わせて、“実用の精度”を高めましょう。モデル開発とデータ活用の主導権は、お客さま側が握るべきだと考えています。
2. AI基盤は外部の型を借りる
外部のノウハウを利活用し、ベストプラクティス(型)で一気に立ち上げるのが効率的です。自社で一から設計する際に起きがちな手戻り・やり直し、トラブル対応に費やす時間・人件費・機会損失といった、TCOを底上げしてしまう“隠れコスト”を抑えることができます。
3. 運用でコスパは育つ
言い換えると、“見える化 → 小さく改善 → 再計測”のサイクルを定期的に回し、費用と性能を少しずつ改善していくということです。具体的には、GPUの空き時間を減らす(自動停止・適正スケール)/推論1回あたりのコストを下げる(バッチ処理・キャッシュ・量子化)/応答の速さや可用性を維持・向上させる等です。ムダな固定費を変動費化しながらQoEを維持することが、継続的なコスパ改善のカギですね。
本日は、ありがとうございました。
※「NVIDIA」はNVIDIA Corporationの登録商標または商標です。
※「Google」「Gemini」はGoogle LLCの登録商標または商標です。
※「Docker」「Docker Model Runner」はDocker, Inc.の登録商標または商標です。

GPU製品
生成AI / LLM・GPUクラスタ構築・NVIDIA DGX・Omniverseなら
NVIDIA エリートパートナーのNTTPC
AI / IoT、デジタルツイン用途に適したGPUサーバーを設計・構築。
さらにデータセンター・ネットワークなど、GPU運用に必要なシステムをワンストップで提供可能。